Файл: Определение и задачи распределенной системы (Задачи распределенных систем).pdf
Добавлен: 13.03.2024
Просмотров: 32
Скачиваний: 0

СОДЕРЖАНИЕ
ГЛАВА 1. ТЕОРЕТИКО-МЕТОДОЛОГИЧЕСКИЕ ОСНОВЫ РАСПРЕДЕЛИТЕЛЬНОЙ СИСТЕМЫ
1.1Определение распределенной системы
1.2 Задачи распределенных систем
ГЛАВА 2. ПРОГРАММНЫЕ СРЕДСТВА РАСПРЕДЕЛИТЕЛЬНЫХ СИСТЕМ
2.1 Традиционные операционные системы
2.2.Распределенная система сбора данных и управления серии NL
Содержание:
ВВЕДЕНИЕ
Актуальность данной темы состоит в том, что в мировой экономике происходят процесса глобализации и информационной интеграции. Они затронули и нашу страну, которая в силу географического положения и размеров вынуждена применять распределенные информационные системы (ИС). Распределенные ИС обеспечивают работу с данными, расположенными на разных серверах, различных аппаратно-программных платформах и хранящимися в различных форматах. Они легко расширяются, основаны на открытых стандартах и протоколах, обеспечивают интеграцию своих ресурсов с другими ИС, предоставляют пользователям простые интерфейсы.
C самого начала развития вычислительной техники образовались два основных направления ее использования. Первое направление - применение вычислительной техники для выполнения численных расчетов, которые слишком долго или вообще невозможно производить вручную. Становление этого направления способствовало интенсификации методов численного решения сложных математических задач, развитию класса языков программирования, ориентированных на удобную запись численных алгоритмов, становлению обратной связи с разработчиками новых архитектур ЭВМ.
Второе направление - это использование средств вычислительной техники в автоматических или автоматизированных информационных системах. Обычно объемы информации, с которыми приходится иметь дело таким системам, достаточно велики, а сама информация имеет достаточно сложную структуру. Одними из естественных требований к таким системам являются средняя быстрота выполнения операций и сохранность информации.
Но поскольку информационные системы требуют сложных структур данных, эти индивидуальные дополнительные средства управления данными являлись существенной частью информационных систем и практически повторялись от одной системы к другой. Стремление выделить и обобщить общую часть информационных систем, ответственную за управление сложно структурированными данными, и явилось, судя по всему, первой побудительной причиной создания различных систем управления.
Очень скоро стало понятно, что невозможно обойтись общей библиотекой программ, реализующей над стандартной базовой файловой системой более сложные методы хранения данных, например, хранение информации в нескольких файлах. Таким образом, все это способствовало созданию распределенных информационных систем.
Именно распределенная система баз данных осуществляет обеспечение средствами слияния локальных баз данных, находящихся в определенных узлах вычислительной сети, с тем, чтобы пользователь, который работает в каком-то узле сети, располагал доступом ко всем существующим базам данных как к единой базе данных.
Объектом исследования являются распределенные базы данных.
Предметом исследования является изучение видов распределенных баз данных, а также процессы их функционирования.
Цель работы состоит в исследовании и анализе распределенных баз данных, а также распределенных систем баз данных.
Основываясь на поставленной цели, можно выделить следующие задачи исследования:
1. определить понятия распределенных баз данных и системы управления базой данных;
2. проанализировать реализацию систем распределенных баз данных;
3. изучить основы проектирования распределенных баз данных.
Структура исследования. Данная работа состоит из введения, 2 глав, заключения и списка литературы.
ГЛАВА 1. ТЕОРЕТИКО-МЕТОДОЛОГИЧЕСКИЕ ОСНОВЫ РАСПРЕДЕЛИТЕЛЬНОЙ СИСТЕМЫ
1.1Определение распределенной системы
До 80-х годов прошлого века компьютерные системы были большими и дорогими. Соответственно большинство организаций имели в лучшем случае несколько компьютеров, работающих как правило независимо друг-от-друга.
С середины 80-х ситуация начала меняться, чему способствовали два фактора:
появление первых микропроцессоров и соответственно основанных на них компьютеров;
появление высокоскоростных компьютерных сетей.[3]
Локальные сети (Local Area Network, LAN) соединяют сотни компьютеров, находящихся в здании. В результате компьютеры могут обмениваться данными на очень больших скоростях (100 Mbit/s, 1 Gbit/s, бывает больше, но редко).
Глобальные сети (Wide Area Network, WAN) позволяют компьютерам по всему миру обмениваться информацией между собой. Скорости, как правило, ниже чем в LAN.
В результате на сегодняшний день достаточно легко можно собрать компьютерную систему состоящую из множества компьютеров соединенных высокоскоростной сетью которая обычно называется компьютерной сетью или распределенной системой (distributed system) в отличие от централизованных (sentralized system) или однопроцессорных (single-processor system) систем.
В вольной трактовке распределенную систему можно определить как набор независимых компьютеров, предоставляющейся их пользователю в виде единой обьединенной системы.
В этом определении следует выделить два момента:
Аппаратура - все компьютеры автономны;
Программное обеспечение - пользователь думает, что имеет дело с единой системой.
К важнейшим характеристикам распределенных систем следует отнести следующие:
От пользователя скрыты различия между компьютерами и способы связи между ними;
Способ, при помощи которого пользователи и приложения единообразно работают в такой системе;
Распределенные системы должны относительно легко поддаваться расширению (масштабирование);
Пользователи и приложения не должны зависеть от того, что часть системы может временно выйти из строя. [10]
Для поддержания представления различных компьютеров и сетей в виде единой системы распределенные системы часто включают в себы дополнительный уровень ПО, находящийся между верхним уровнем (на котором работают пользователи и приложения) и нижним уровнем (на котором находятся операционные системы). Такая система обычно называется системой промежуточного уровня (middleware).
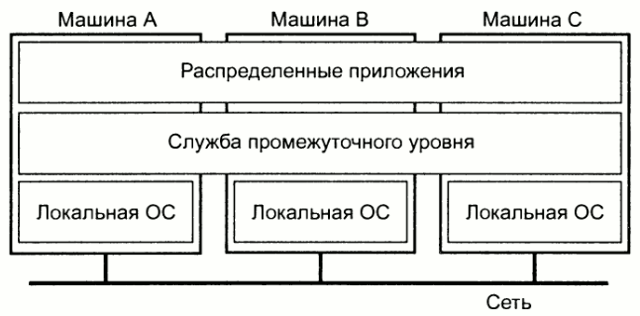
Некоторые примеры распределенных систем:
Сеть рабочих станций в университетской лаборатории. Эта распределенная система может обладать единой файловой системой, в которой все файлы одинаково доступны для всех машин с использованием постоянного пути доступа.
Система автоматической обработки заказов. Обычно подобные системы используются сотрудниками различных отделов, возможно находящимися в разных местах. Заказы передаются с мобильных терминалов (ноутбуки, КПК, телефоны). Приходящие заказы автоматически пересылаются в отдел планирования преобразуясь там во внутренние заказы на поставку которые поступают в отдел доставки и в заявки на оплату поступающие в бухгалтерию. Пользователи остаются в неведении о том, как заказы курсируют внутри системы, для них все представляется так, будто вся работа происходит в централизованной базе данных. [4]
Всемирная Паутина (World Wide Web, WWW) предоставляет простую, целостную и единообразную модель распределенных документов. Публикация документа очень проста - вы должны только задать ему имя в виде унифицированного указателя ресурса (Unified Resource Locator, URL), которое ссылается локальный файл с содержимым документа. В идеале, если-бы WWW предоставлялась пользователям гигантской системой документооборота, она могла-бы считаться истинно распределенной системой. На практике это не так, так-как пользователи осознают, что документы находятся в разных местах и распределены по различным серверам.
1.2 Задачи распределенных систем
Рассмотрим четыре важнейшие задачи, решение которых делает построение распределенных систем осмысленным.
Задача 1. Доступ пользователей к ресурсам
Основная задача распределенной системы - облегчить пользователям доступ к удаленным ресурсам и обеспечить их совместное использование, регулируя этот процесс. Традиционно ресурсы включают в себя: принтеры, компьютеры, устройства хранения данных, файлы и данные. Одна из очевидных причин совместного использования ресурсов - экономичность. Другая очевидная причина - облегчение кооперации и обмена информацией.
Так, широкое использование сети интернет привело к появлению концепции виртуального офиса, когда географически удаленные друг от друга группы сотрудников работают вместе при помощи систем групповой работы (groupware) - программ для совместного редактирования документов, проведения презентаций и т.д. [12]
Стоит заметить, что по мере роста степени совместного использования ресурсов все более и более важными становятся вопросы безопасности.
Задача 2. Прозрачность
Сокрытие того факта, что процессы и ресурсы физически распределены по множеству компьютеров - важная задача распределенных систем. Распределенные системы, которые представляются пользователям и приложениям в виде единой компьютерной системы называют прозрачными (transparent).
Концепция прозрачности применима к различным аспектам функционирования распределенных систем:
Доступ (access transparency). Скрывается разница в представлении данных и доступа к ресурсам. Например, при передаче целого числа с компьютера на базе процессора Intel x86 на компьютер на базе процессора Sun SPARC следует учитывать, что на Intel используется Little Endian представление целых чисел, а на SPARC - Big Endian.
Местоположение (location transparency). Скрывается местоположение ресурса. Важную роль в реализации прозрачности местоположения имеет именование. Например URL http://www.yandex.ru/index.html не содержит никакой информации о реальном местоположении сервера Яндекса.
Перенос (migration transparency). Скрывается факт переноса ресурса в другое место. Т.е. смена местоположения ресурса не влияет на доступ к нему.
Смена местоположения (relocation transparency). Скрывается факт перемещения ресурса в другое место в процессе обработки. В качестве примера - мобильные пользователи, работающие с беспроводным переносным компьютером и не отключающиеся от сети при переходе с места на место.
Репликация (replication transparency). Скрывается факт репликации ресурса, т.е. существования нескольких копий ресурса. Для скрытия факта репликации необходимо, чтобы все реплики (копии) имели одно и то-же имя. Соответственно система, которая поддерживает прозрачность репликации должна поддерживать и прозрачность местоположения. [11]
Параллельный доступ (concurrency transparency). Скрывает факт возможного совместного использования ресурса несколькими пользователями одновременно. Такой параллельный доступ к совместно используемому ресурсу сохраняет этот ресурс в непротиворечивом состоянии. Для обеспечения непротиворечивости может быть использован механизм блокировок или механизм транзакций (хотя реализация механизма транзакций - очень непростая задача в рамках распределенной системы)
Отказ (failure transparency). Скрывается факт выхода из строя и восстановления ресурса. Лэсли Лампорт: "Вы понимаете, что у вас есть эта штука, поскольку при поломке компьютера вам никогда не предлагают приостановить работу". Основная трудность состоит в сложности отличить неработоспособный ресурс от ресурса с очень медленным доступом.
Сохранность (persistence transparency). Скрывается, хранится программный ресурс на диске или находится в оперативной памяти. Например, многие объектно-ориентированные базы данных предоставляют возможность непосредственного вызова методов для сохранных объектов. Сервер БД при этом копирует состояние объекта в оперативную память, вызывает метод объекта запрошенный пользователем и сохраняет новое состояние объекта на диск. Пользователь об этой цепочке ничего не знает.
Несмотря на то, что прозрачность в общем желательна для любой распределенной системы, существуют ситуации когда попытки скрыть от пользователя всякую распределенность не слишком разумны. Существует паритет между высокой степенью прозрачности и производительностью системы. Таким образом можно сказать, что достижение прозрачности - это разумная цель при проектировании и разработке распределенных систем, но она не должна рассматриваться в отрыве от других характеристик системы.
Задача 3. Открытость
Открытая распределенная система (open distributed system) - это система, предполагающая службы, вызов которых осуществляется с использованием стандартизированного синтаксиса и семантики.
В распределенных системах службы обычно определяются через интерфейсы, которые описываются некоторым образом, например в помощью специального языка определения интерфейсов (Interface Definition Language, IDL). Описание интерфейсов касается в основном синтаксиса служб, семантика-же должна быть описана отдельно, чаще всего средствами естественного языка (в виде документов-спецификаций и комментариев). [14]

