Файл: Определение и задачи распределенной системы (Задачи распределенных систем).pdf
Добавлен: 13.03.2024
Просмотров: 33
Скачиваний: 0

СОДЕРЖАНИЕ
ГЛАВА 1. ТЕОРЕТИКО-МЕТОДОЛОГИЧЕСКИЕ ОСНОВЫ РАСПРЕДЕЛИТЕЛЬНОЙ СИСТЕМЫ
1.1Определение распределенной системы
1.2 Задачи распределенных систем
ГЛАВА 2. ПРОГРАММНЫЕ СРЕДСТВА РАСПРЕДЕЛИТЕЛЬНЫХ СИСТЕМ
2.1 Традиционные операционные системы
2.2.Распределенная система сбора данных и управления серии NL
Будучи правильно описанным определение интерфейса допускает возможность совместной работы произвольного процесса, нуждающегося в таком интерфейсе, с другим произвольным процессом, реализующим этот интерфейс.
Способность к взаимодействию (interoperability) характеризует насколько две реализации системы в состоянии совместно работать, полагаясь только на то, что службы каждой из них соответствуют общему стандарту.
Переносимость (portability) характеризует то, насколько приложение, разработанное для распределенной системы A может без изменений выполняться в распределенной системе B.
Гибкость (flexibility) характеризует легкость конфигурирования системы, состоящей из различных компонентов, возможно от разных производителей. Добавление к системе новых компонентов или замена существующих не должно вызывать затруднений. Гибкость == расширяемость.
В построении гибких открытых распределенных систем решающим фактором оказывается организация этих систем в виде наборов относительно небольших и легко заменяемых или адаптируемых компонентов. Это предполагает не только описание интерфейсов верхнего уровня, но также и интерфейсов внутренних модулей приложения и описания взаимодействия этих модулей.
Задача 4. Масштабируемость
Масштабируемость системы может измеряться по трем различным показателям:
Система может быть масштабируемой по отношению к ее размеру, что означает легкость подключения к ней дополнительных пользователей и ресурсов.
Система может быть масштабируемой географически, т.е. пользователи и ресурсы могут быть разнесены в пространстве.
Система может быть масштабируемой в административном смысле, т.е. быть проста в управлении при работе во множестве административно-независимых организаций.
Рассмотрим масштабирование по размеру. При необходимости увеличить число пользователей или ресурсов могут возникнуть ограничения, связанные с централизацией служб, данных и алгоритмов. Например:
|
Концепция |
Пример |
|
Централизованные службы |
Один сервер на всех пользователей |
|
Централизованные данные |
Единый телефонный справочник |
|
Централизованные алгоритмы |
Организация маршрутизации на основе полной информации |
Иногда использование единственного сервера является неизбежным, например при обеспечении работы с конфиденциальной информацией.
Централизация данных так-же вредна, как и централизация служб. Сложно представить себе например систему DNS, построенную на основе единственного супер-сервера, хранящего все записи.
Централизация алгоритмов - это тоже очень не удачная идея. Основная проблема в том, что попытка собрать всю необходимую для работы алгоритма информацию со всей сети на одном узле приведет к тому, что сеть будет перегружена служебным трафиком и нормальное функционирование системы станет невозможно. [6] Соответственно в распределенных системах следует использовать децентрализованные алгоритмы, которые обладают рядом свойств, отличающих их от централизованных алгоритмов:
ни одна из машин не обладает полной информацией о состоянии системы;
машины принимают решения на основе локальной информации;
сбой в работе одной машины не нарушает работу алгоритма;
не требуется предположение о существовании единого времени.
Первые три свойства более-менее понятны, последнее-же возможно требует некоторого уточнения. Любой алгоритм, начинающийся со слов "Ровно в 12:00:00 все машины делают ..." работать не будет, поскольку невозможно синхронизировать все часы на свете.
У географической масштабируемости - свои сложности. Одна из основных проблем масштабирования распределенных систем, разработанных для локальных сетей, на глобальные сети - то, что в их основе лежит принцип синхронной связи. Т.е. процесс, выполняющий запрос, блокируется до получения ответа. Другое важное отличие организации глобальных коммуникаций от локальных - существенно меньшая надежность глобальных сетей с точки зрения передачи отдельно-взятого блока данных.
Также следует принимать во внимание вопрос обеспечения масштабирования распределенной системы на множество административно-независимых областей. Основная проблема, которую надо при этом решить - состоит в конфликтах правил, относящихся к использованию ресурсов (и плате за них), управлению и безопасности. Здесь можно выделить два типа проверок безопасности: злонамеренные атаки из новой области на системы и атака на ресурсы области из самой распределенной системы.
Существуют три основные технологии масштабирования:
сокрытие времени ожидания связи;
распределение;
репликация.
Сокрытие времени ожидания применяется в случае географического масштабирования. Идея - постараться по возможности избежать ожидания ответа от удаленного сервера. Т.е. нужно разрабатывать приложения в расчете на использование только асинхронной связи. Когда будет получает ответ, приложение прервет свою работу и вызовет специальный обработчик для завершения отправленного ранее запроса. В случае, если использование асинхронной связи слишком сложно либо не соответствует паттерну использования приложения - можно пойти другим путем - уменьшить объем необходимого взаимодействия, например перенести часть логики с сервера на клиент.
Распределение предполагает разбиение компонентов на мелкие части и последующее разнесение этих частей по системе. Хороший пример - DNS.
Репликация компонентов распределенной системы не только повышает доступность, но и помогает выровнять загрузку компонентов, что ведет к повышению производительности. Особая форма репликации - кэширование. Основное различие - кэширование происходит на стороне потребителя ресурса, а репликация - на стороне системы предоставляющей ресурс.
У репликации и кэширования есть один подводный камень: поскольку есть множество копий ресурса, модификация одной из них делает ее отличной от остальных - возникает проблема непротиворечивости данных (consistency).
ГЛАВА 2. ПРОГРАММНЫЕ СРЕДСТВА РАСПРЕДЕЛИТЕЛЬНЫХ СИСТЕМ
2.1 Традиционные операционные системы
Программно распределенные системы очень похожи на традиционные операционные системы. Прежде всего они работают как менеджеры ресурсов существующего аппаратного обеспечения, помогающие множеству пользователей и процессов совместно исползховать процессоры, память, перефирийные устройства, сеть и данные всех видов. Во вторых распределенная системы скрывает сложность и гетерогенную природу аппаратного обеспечения на базе которого она построена, предоставляя виртуальную машину для выполнения приложений. [6]
Операционные системы для распределенных компьютеров можно подразделить на:
сильно связанные - операционная система старается работать с единых глобальным представлением ресурсов, которыми она управляет;
слабо связанные - представляются как набор операционных систем, каждая из которых работает на своем компьютере, которые однако функционируют совместно, делая собственные службы доступными другим.
Сильно-связанные операционные системы обычно называют распределенными операционными системами и чаще всего используют для управления мультипроцессорами или гомогенными мультикомпьютерами.
Слабо-связанные операционные системы в свою очередь называют сетевыми операционными системами и используют для управления гетерогенными мультикомпьютерами. Как правило в купе с сетевой операционной системой частью распределенной системыв являются системы промужеточного уровня (middleware).
Распределенные операционные системы
Существует два типа распределенных операционных систем:
мультипроцессорная операционная система - управляет ресурсами мультипроцессора;
мультикомпьютерная операционная система - разрабатывается для гомогенных мультикомпьютеров.
Операционные системы для однопроцессорных компьютеров[11]
Традиционно операционные системы строились для управления компьютерами с одним процессором. Основной задачей таких операционных систем была организация легкого доступа пользователей и призожений к разделяемым устройствам - процессору, памяти, дискам и перефирийным устройствам. Для приложения это выглядит так, словно эти ресурсы находатся в его полном распоряжении. В этом смысле говорят, что операционная система реализует виртуальную машину предоставляя приложениям средства многозадачности. Важно тут то, что приложения как-бы отделены друг от друга - например приложения A не может изменить данные приложения B просто обратившись в ту область памяти, где эти данные хранятся. Также важно то, что приложения могут использовать предоставленные их ресурсы только так, как это предписано операционной системой. Например приложениям обычно запрещено копировать данные напрямую в сетевой интерфейс - нужно использовать специальный API операционной системы.
Следовательно операционная система должна полностью контролировать распределение и использование аппаратных ресурсов. Поэтому большинство процессоров поддерживают как минимум 2 режима работы:
режим ядра (kernel mode) - доступны для выполнения все инструкции процессора, доступна вся имеющаяся память и регистры;
пользовательский режим (user mode) - доступ к регистрам и памяти ограничен, запрещены к исполнению некоторые инструкции процессора.
На время выполнения кода операционной системы процессор переключается в режим ядра. Единственный способ перейти из пользовательского режима в режим ядра - сделать системный вызов - одну из базовых служб предоставляемых операционной системой, полностью контролируемую ей.
Типичной ситауцией является то, что практически весь код операционной системы выполняется в режиме ядра, т.е. операционная система (вернее ядро операционной системы) представляет собой большую монолитную программу, выполняющуюся в едином адресном пространстве. Замена или адаптция компонентов системы в таком случае без перезакрузки системы является затруднительной.
Другой вариант - организация операционной системы в виде двух частей:
набор модулей для управления аппаратным обеспечением, которые могут выполняться на пользовательском уровне (по крайней мере большая часть их кода);
микроядро, содержащее исключительно код для установки регистров устройств, переключения процессора с процесса на процесс, работы с блоком управления памятью и перехвата аппаратных прерываний. Также в нем обычно содержится код, преобразующий вызовы соответствующих модулей пользовательского уровня в системные вызовы и возвращающий результаты.
Схема организации операционной системы на основе микроядра приведена ниже:
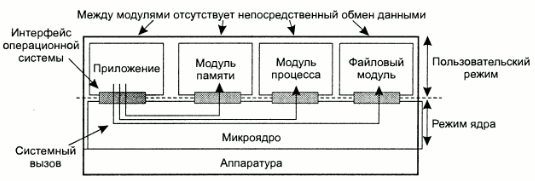
TODO: Достоинства и недостатки микрояденных систем.
Примеры микроядерных операционных систем:
AIX
Mac OS X (Mach 3.0)
OpenVMS
Minix
Мультипроцессорные операционные системы
Логичным развитием однопроцессорных операционных систем является возможность поддержки нескольких процессоров имеющих доступ к совместно используемой памяти. С концептуальной точки зрения данное расширение функциональности не сложно. Однако многие классические однопроцессорные операционные системы разработаны как монолитные программы с одним потоком управления. Адаптация подобных систем под мультипроцессорные зачастую означает повторное проектирование и реализацию всего ядра. Современные ОС как правило изначально разрабатываюся с учетом возможности работы в многопроцессорных системах. [7]
В многопроцессорных операционных системах, как впрочем и в мультизадачных однопроцессорных, ставится задача обеспечения взаимодействия между приложениями, для чего используются специальные конструкции: семафоры и мониторы.
Семафор может быть представлен как целое число, поддерживающее две операции - инкремент и декремент. При этом операция декремента на семафоре, имеющем нулевое значение блокируется до того момента, пока не произойдет инкремент этого семафора (как правило другим процессом). Операции над семафорами являются атомарными, т.е. во время операции над семафором ни один другой процесс не может получить доступ к этому семафору.
Монитор представляет собой конструкцию языка программирования, напоминяющую обьект в обьектно-ориентированных языках. Монитор содержит переменные и процедуры, причем доступ к процедурам может осуществляться только путем вызова соответствующих процедур. И в каждый момент времени выполнение процедуры доступно только одному процессу, т.е. если один процесс выполняет какую-либо процедуру монитора, то второй процесс будет заблокирован при попытке вызова процедуры монитора (той-же самой или другой) до тех пор, пока первый процесс не закончит выполнение процедуры. Реализация мониторов чаще всего строится на базе специальных семафоров, которые могут принимать значения 0 или 1. Такие семафоры носят название мьютекс (mutex, mutual exclusion) и с ними ассоциируются две операции - lock и unlock. Также мониторы применяются для организации такого примитива синхронизации как условные переменные - специальные переменные с двумя доступными операциями: wait (ждать события) и signal (породить событие).

