Файл: Разработка объектной программы для обработки данных о авторах издательства.docx
Добавлен: 18.03.2024
Просмотров: 147
Скачиваний: 3
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
УЧРЕЖДЕНИЕ ВЫСШЕГО ОБРАЗОВАНИЯ
«УНИВЕРСИТЕТ УПРАВЛЕНИЯ «ТИСБИ»
Факультет «Информационные технологии»
КУРСОВАЯ РАБОТА
по дисциплине «Программная инженерия»
на тему: «Разработка объектной программы для обработки данных о авторах издательства»
Выполнил: студент гр. ПИ-812
Габдуллин И.Л.
Проверил: ст. преподаватель
Якунина Е.А.
Казань 2020
Содержание
Постановка задачи 3
1.Описание используемых структур данных 5
2.Краткие сведения об объектном подходе 12
3.Формализованное описание разработанных классов 17
4.Описание демонстрационного модуля 19
5.Описание структуры проекта 24
Список литературы 25
Приложение 26
Постановка задачи
Книжное издательство ведет список своих авторов с указанием уникальной фамилии автора и номера его мобильного телефона. Для каждого автора создается список книг с названием книги и ее тиража.
Разработка программы включает в себя: определение необходимых объектов и способов их взаимодействия, формальное описание объектов в виде классов, программную реализацию всех необходимых методов включая подсчет суммарного тиража как по каждому автору, так и в целом по всему издательству, всестороннее тестирование методов с помощью консольного (при разработке) и оконного (в окончательном варианте) приложения.
Для объединения авторов используется структура данных в виде очереди на основе динамического массива со сдвигом элементов. Для объединения книг каждого автора используется структура данных в виде адресного разомкнутого неупорядоченного однонаправленного списка с заголовком.
Разработка выполняется с учетом следующих требований:
-
Имена классов, свойств и методов должны носить содержательный смысл и соответствовать информационной задаче -
Обязательное соблюдение принципа инкапсуляции – использование в классах, только закрытых свойств и реализация необходимого набора методов доступа -
Наличие двух методов для сохранения и всей объектной структуры во внешнем файле и обратной загрузки, при этом стандартные механизмы сериализации разрешается использовать только как дополнение к самостоятельно реализованным методам -
Тестовое оконное приложение должно обладать удобным пользовательским интерфейсом с контролем вводимых данных и отображением текущего состояния объектной структуры с помощью списковых или табличных компонентов. -
Стандартные контейнеры/коллекции (включая обобщенные классы) разрешается использовать только как дополнение к самостоятельно разработанным классам. -
В качестве языка разработки используется Object Pascal и среда разработки Lazarus.
-
Описание используемых структур данных
Реализация списковых структур.
Линейный список – это набор связанных однотипных элементов, в котором каждый элемент каким-то образом определяет следующий за ним элемент. Добавление нового элемента возможно в любом месте списка, также можно удалить любой элемент списка. Списковые структуры являются более гибкими, но и немного более сложными в реализации.
Стандартный набор операций со списком включает:
-
поиск в списке заданного элемента -
добавление нового элемента после заданного или перед заданным элементом -
удаление заданного элемента -
проход по списку от первого элемента к последнему с выполнением заданных действий
Динамическая реализация линейных списков, основана на динамическом выделении и освобождении памяти для элементов списка. Каждый элемент списка имеет адресное поле-указатель на следующий, а для двунаправленного еще и предыдущий элемент, т.е. адресные связи выстраиваются от первого элемента к последнему, последний элемент в адресном поле имеет нулевой адрес. Логически последовательные элементы списка физически могут размещаться в любых областях памяти.
Для управления списком необходимо знать размещение в памяти его заголовочного элемента, для чего вводится основная переменная-указатель Head.
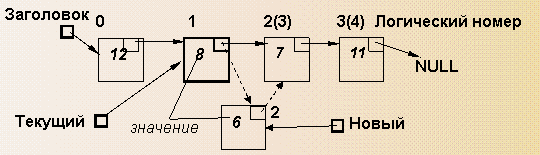
Рис.1 Структура списка с заголовком
Заголовочный элемент:
-
всегда находится в начале списка -
никогда не удаляется из списка -
содержит адрес первого реального элемента списка -
адресуется неизменяемым указателем (например – Head)
Рассмотрим алгоритмы основных операций:
-
Инициализация пустого списка
-
Выделение памяти для заголовочного элемента с использованием указателя Head
Head := TBook.Create();
При добавлении и удалении элементов часто приходится выполнять операцию поиска. Рассмотрим алгоритм этой операции. Поиск оформляется как функцию, принимающую входной параметр – искомое значение информационного поля и возвращающую результат поиска – либо адрес найденного элемента, либо пустой адрес:
-
Search(aLastName: string): TBook -
Объявление вспомогательного указателя temp -
Установка указателя в адрес первого элемента:

temp:= Head.GetNext;
-
Организация цикла по условию достижения последнего элемента while (temp <> nil) do<тело цикла> -
В теле цикла очередной элемент списка сравнивается с искомым значением и в случае если элемент найден, цикл прерывается, с выводом адреса найденного элемента, либо происходит переход к следующему: temp:= temp.GetNext;
-
Добавление Первого элемента
-
Создание элемента -
Формирование полей первого элемента: Head.SetNext(aBook); -
Увеличение счетчика числа элементов: BooksCount := BooksCount + 1;
Добавление нового элемента в список после заданного:
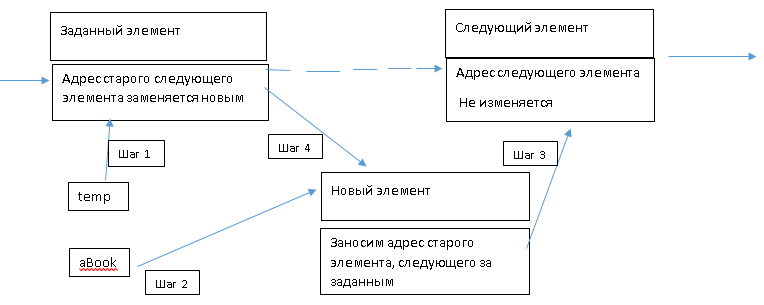
Рис. 2 Добавление нового элемента в список (после)
-
Поиск места вставки с помощью функции поиска:
temp := Search(aBookName)
-
Выделение памяти с помощью вспомогательного указателя aBook -
Формирование полей нового элемента:
В поле temp заносится адрес следующего элемента:
aBook.SetNext(temp.GetNext);
Изменяем адресного поля у заданного элемента с записью в него адреса нового элемента:
temp.SetNext(aBook)
-
Добавление нового элемента в список перед заданным:
Рис. 3 Добавление нового элемента в список (перед)
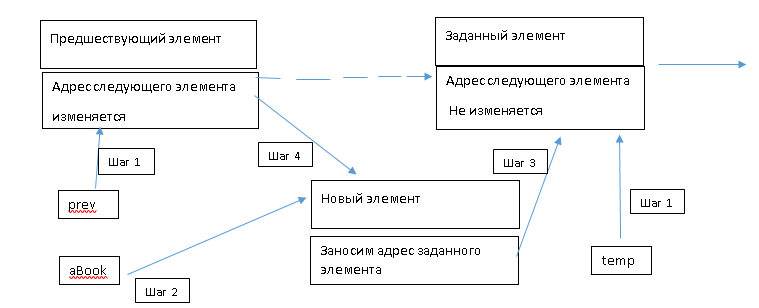
-
Поиск заданного элемента с помощью измененной функции поиска: она должна возвращать еще и адрес элемента, который предшествует заданному. Для этого можно использовать еще одну адресную переменную (например, prev), значение которой возвращается как выходной параметр:
temp := Search(aBookName, prev);
-
Выделение памяти с помощью вспомогательного указателя aBook -
Формирование полей нового элемента:
В поле Next заносится адрес заданного элемента:
aBook.SetNext(prev.GetNext);
-
Изменяем адресное поле Next у предыдущего элемента на адрес нового элемента:
prev.SetNext(aBook);
-
Алгоритм удаления заданного элемента
-
Проверка наличия элементов в списке -
Поиск удаляемого элемента с помощью измененной функции поиска:
temp := Search(aBookName, prev);
-
Изменение адресного поля у предшественника удаляемого элемента, с занесением в него адреса элемента, следующего за удаляемым:
prev.SetNext(temp.GetNext);
-
Обработка удаляемого элемента, используя указатель temp
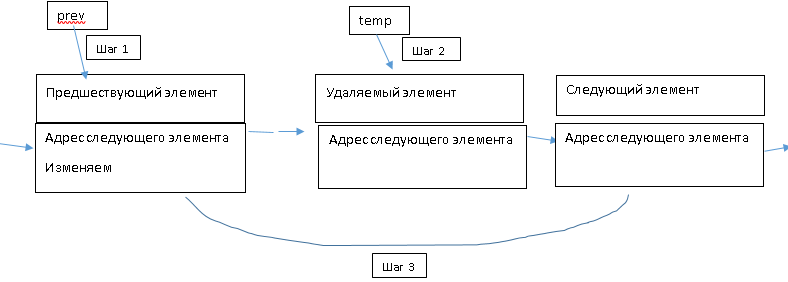
Рис. 4 Обработка удаляемого элемента
Очередь (Queue) – это последовательность однотипных элементов, характерная тем, что новые элементы в нее добавляются с одного конца, а удаляются с другого.
Очередь работает по принципу «Элемент, помещенный в очередь первым, извлечен будет тоже первым». Иногда этот принцип обозначается сокращением FIFO (от английского «FirstIn – FirstOut», т.е. «Первым зашел – первым вышел»). Для очереди определяется ее начало (первый элемент в очереди) и конец (последний элемент).
Рассмотрим способ реализации очереди на основе динамического массива. Суть способа довольно проста и состоит в следующем: элементы очереди заносятся в ячейки массива последовательно, начиная с первой ячейки массива, а вот при удалении извлекается элемент из первой ячейки массива и все остальные элементы сдвигаются влево на одну ячейку, так что новый первый элемент очереди оказывается всегда в первой ячейке массива.
Особенность динамичного массива заключается в возможности изменения его размерности во время выполнения программы при помощи вызовов специальных методов для работы с массивами.
Для реализации необходимо:
-
Объявить динамический массив с элементами необходимого типа: -
AuthorList: array of TAuthor; -
Объявить одну индексную переменную для отслеживания конца очереди и одновременно – числа элементов в очереди: -
AuthorCount: integer; -
Инициализировать динамический массив, установив его изначальную размерность:
SetLength(AuthorList, aSize);
-
Установить начальное значение переменной счетчика 0 AuthorCount := 0; -
Реализовать операции добавления и удаления в соответствии с их алгоритмами
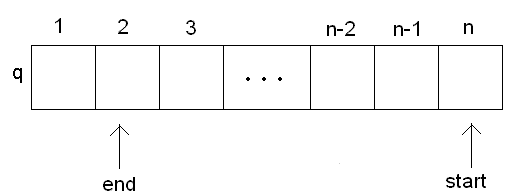
Рис.5 Структура очереди
Алгоритм добавления элемента в очередь:
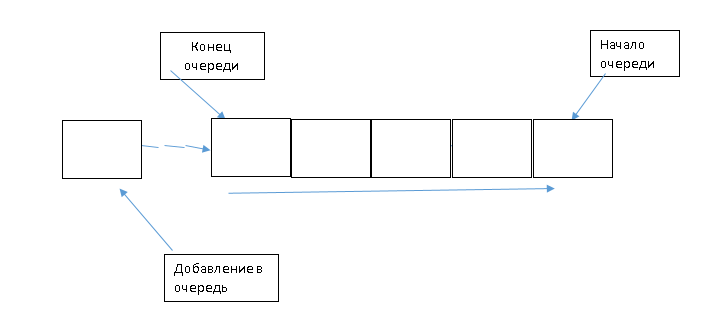
Рис.6Добавление в очередь
-
Проверить возможность добавления
if (AuthorCount = Length(AuthorList)) then
-
При необходимости увеличить размерность массива:
SetLength(AuthorList, Length(AuthorList) * 2);
-
Занести элемент в массив по значению индекса-счетчика:
AuthorList[AuthorCount] := aAuthor;
-
Увеличить значение индекса счетчика: Inc(AuthorCount);
Алгоритм удаления элемента из очереди
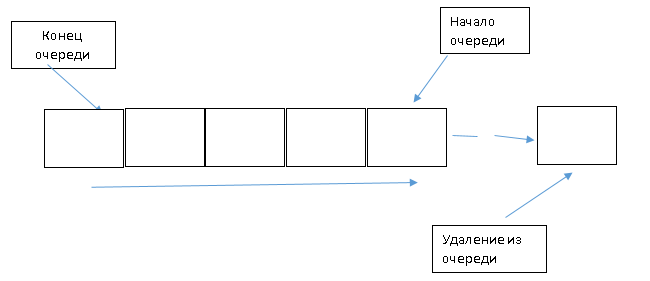
Рис.7Удаление элемента
-
Проверить наличие элементов
if (AuthorCount > 0) then
-
Организовать for-цикл сдвига элементов влево на одну ячейку
for i := 0 to Count - 2 do OfficeList[i] := OfficeList[i + 1];
-
Уменьшить значение индекса-счетчика
Dec(AuthorCount);
- 1 2 3 4 5