Добавлен: 24.04.2024
Просмотров: 48
Скачиваний: 0
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.

Отчёт по производственной практике.
Задание №1
Существуют следующее современные и актуальные методы анализа данных в информационных системах:
- Искусственная нейронная сеть (ANN), обычно называемые просто нейронными сетями (NN) или, еще проще, нейронными сетями, [1] представляют собой вычислительные системы, основанные на биологических нейронных сетях, которые составляют мозг животных.
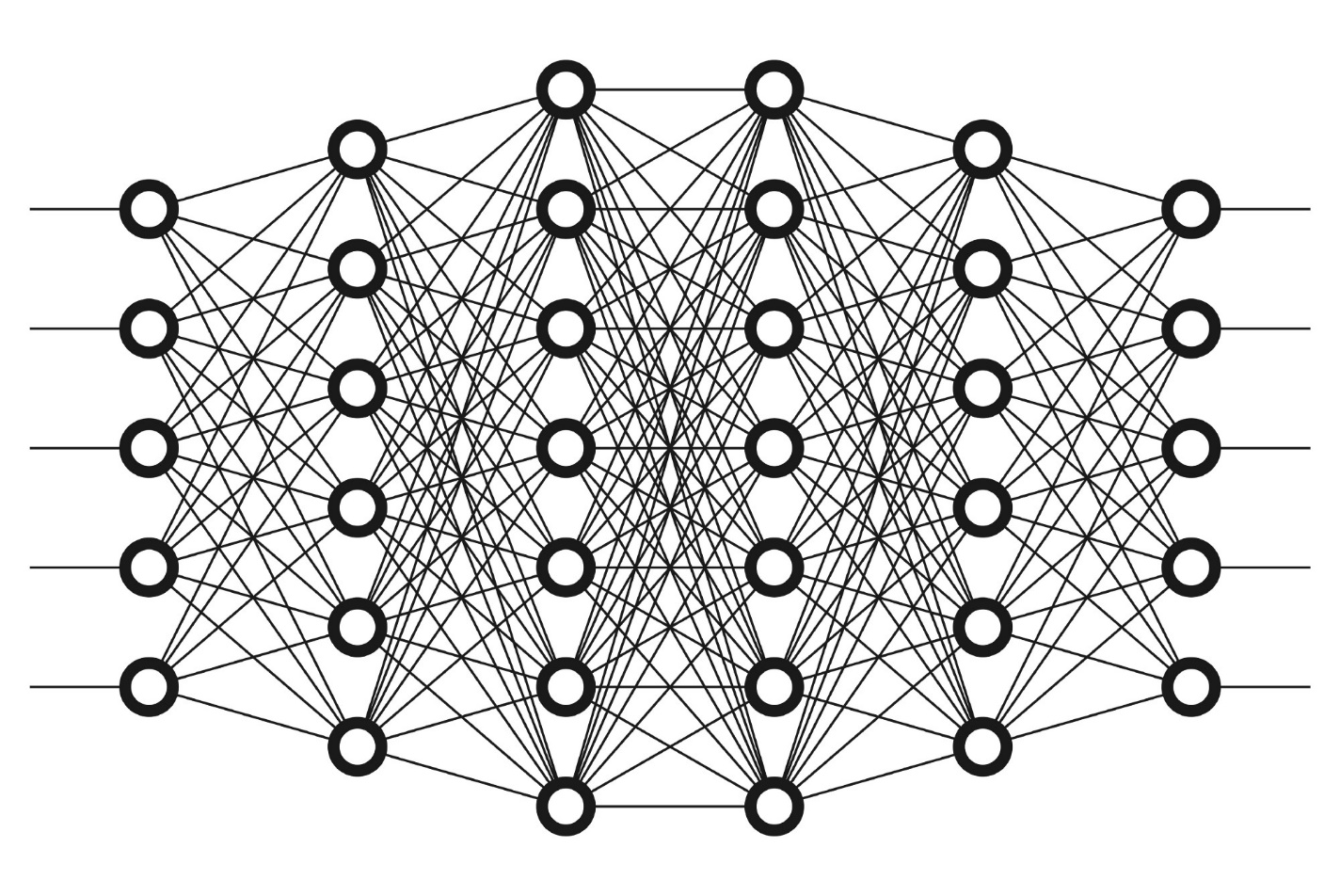
ИНС основана на наборе соединенных блоков или узлов, называемых искусственными нейронами, которые в общих чертах моделируют нейроны биологического мозга. Каждое соединение, подобно синапсам в биологическом мозге, может передавать сигнал другим нейронам. Искусственный нейрон получает сигналы, затем обрабатывает их и может передавать сигналы нейронам, подключенным к нему. "Сигнал" при соединении представляет собой действительное число, а выходные данные каждого нейрона вычисляются с помощью некоторой нелинейной функции от суммы его входных данных. Соединения называются ребрами. Нейроны и ребра обычно имеют вес, который корректируется по мере обучения. Вес увеличивает или уменьшает силу сигнала при соединении. Нейроны могут иметь такой порог, что сигнал отправляется только в том случае, если совокупный сигнал пересекает этот порог. Обычно нейроны объединяются в слои. Различные слои могут выполнять различные преобразования на своих входных данных. Сигналы передаются от первого слоя (входного слоя) к последнему слою (выходному слою), возможно, после многократного обхода слоев.
- Фа́кторный анализ — многомерный метод, применяемый для изучения взаимосвязей между значениями переменных. Предполагается, что известные переменные зависят от меньшего количества неизвестных переменных и случайной ошибки.
Факторный анализ позволяет решить две важные проблемы исследователя: описать объект измерения всесторонне и в то же время компактно. С помощью факторного анализа возможно выявление скрытых переменных факторов, отвечающих за наличие линейных статистических корреляций между наблюдаемыми переменными.
Две основных цели факторного анализа:
-
определение взаимосвязей между переменными, (классификация переменных), то есть «объективная R-классификация»[1][2]; -
сокращение числа переменных необходимых для описания данных.
При анализе в один фактор объединяются сильно коррелирующие между собой переменные, как следствие происходит перераспределение дисперсии между компонентами и получается максимально простая и наглядная структура факторов. После объединения коррелированность компонент внутри каждого фактора между собой будет выше, чем их коррелированность с компонентами из других факторов. Эта процедура также позволяет выделить латентные переменные, что бывает особенно важно при анализе социальных представлений и ценностей. Например, анализируя оценки, полученные по нескольким шкалам, исследователь замечает, что они сходны между собой и имеют высокий коэффициент корреляции, он может предположить, что существует некоторая латентная переменная, с помощью которой можно объяснить наблюдаемое сходство полученных оценок. Такую латентную переменную называют фактором. Данный фактор влияет на многочисленные показатели других переменных, что приводит нас к возможности и необходимости выделить его как наиболее общий, более высокого порядка. Для выявления наиболее значимых факторов и, как следствие, факторной структуры, наиболее оправданно применять метод главных компонент (МГК). Суть данного метода состоит в замене коррелированных компонентов некоррелированными факторами. Другой важной характеристикой метода является возможность ограничиться наиболее информативными главными компонентами и исключить остальные из анализа, что упрощает интерпретацию результатов. Достоинство МГК также в том, что он — единственный математически обоснованный метод факторного анализа[1][3]. По утверждению ряда исследователей МГК не является методом факторного анализа, поскольку не расщепляет дисперсию индикаторов на общую и уникальную[4].Основной смысл факторного анализа заключается в выделении из всей совокупности переменных только небольшого числа латентных независимых друг от друга группировок, внутри которых переменные связаны сильнее, чем переменные, относящиеся к разным группировкам.
Факторный анализ может быть:
-
разведочным — он осуществляется при исследовании скрытой факторной структуры без предположения о числе факторов и их нагрузках; -
конфирматорным (подтверждающим), предназначенным для проверки гипотез о числе факторов и их нагрузках.


- Регрессио́нный анализ — набор статистических методов исследования влияния одной или нескольких независимых переменных {\displaystyle X_{1},X_{2},...,X_{p}} на зависимую переменную {\displaystyle Y}. Независимые переменные иначе называют регрессорами или предикторами, а зависимые переменные — критериальными или регрессантами. Терминология зависимых и независимых переменных отражает лишь математическую зависимость переменных (см. Корреляция), а не причинно-следственные отношения. Наиболее распространённый вид регрессионного анализа — линейная регрессия, когда находят линейную функцию, которая, согласно определённым математическим критериям, наиболее соответствует данным. Например, в методе наименьших квадратов вычисляется прямая(или гиперплоскость), сумма квадратов между которой и данными минимальна.;
- Панельный анализ (данных) статистический метод, широко используемый в социальная наука, эпидемиология, и эконометрика для анализа двухмерного (обычно поперечного и продольного) данные панели. Данные обычно собираются с течением времени и по одним и тем же лицам, а затем регресс проходит по этим двум измерениям.
Панельные данные[1][2], или лонгитюдные данные[2] — используемые в социальных науках и эконометрике многомерные данные, получаемые серией измерений или наблюдений за несколько периодов времени для одних и тех же компаний или людей. Исследование, в котором используются панельные данные, называется панельным исследованием.
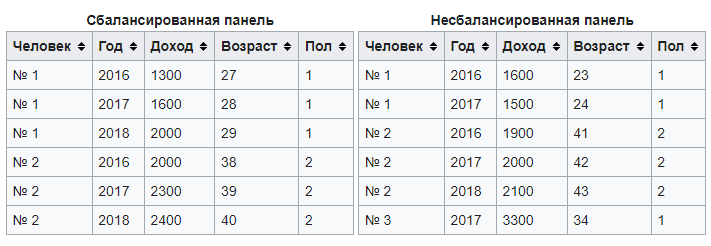
В приведенном примере показаны два набора данных, собранные в панельную структуру. Индивидуальные характеристики (доход, возраст, пол) собираются для разных людей и разных лет. В первом наборе данных два человека (№ 1, № 2) наблюдаются каждый год в течение трех лет (2016, 2017, 2018). Во втором наборе данных три человека (№ 1, № 2, № 3) наблюдаются два раза (человек № 1), три раза (человек № 2) и один раз (человек № 3), соответственно, за три года (2016, 2017, 2018); в частности, для человека № 1 отсутствуют данные по 2018 году, а для человек № 3 — по 2016 и 2018 году.
Сбалансированная панель[3] (первый пример) представляет собой набор данных, в котором каждый член группы (то есть человек) наблюдается каждый год. Следовательно, если сбалансированная панель содержит N единиц наблюдения и Т периодов, число наблюдений (n) в наборе данных обязательно составит п = N × T[4].
Несбалансированная панель[3] (второй набор данных в примере) представляет собой набор данных, в котором, по меньшей мере, один член группы не имеет данных по всем периодам. Поэтому, если несбалансированная панель содержит N единиц наблюдения и Т периодов, то число наблюдений (n) в наборе данных строго меньше их произведения: п < N × T[4].
Оба набора данных структурированы в длинном формате, в котором одна строка содержит одно наблюдение за один раз. Другим способом структурирования панельных данных является широкий формат, где одна строка представляет одну единицу наблюдения для всех моментов времени[5] (например, в широком формате будет только две (первый пример) или три (второй пример) строки данных, с дополнительными столбцами для каждой переменной времени (доход, возраст).
- Корреляционный анализ — метод обработки статистических данных, с помощью которого измеряется теснота связи между двумя или более переменными.;
Семанти́ческий ана́лиз — этап в последовательности действий алгоритма автоматического понимания текстов, заключающийся в выделении семантических отношений, формировании семантического представления текстов. Один из возможных вариантов представления семантического представления — структура, состоящая из «текстовых фактов». Семантический анализ в рамках одного предложения называется локальным семантическим анализом.
- Анализ данных — область математики и информатики, занимающаяся построением и исследованием наиболее общих математических методов и вычислительных алгоритмов извлечения знаний из экспериментальных (в широком смысле) данных
[1]; процесс исследования, фильтрации, преобразования и моделирования данных с целью извлечения полезной информации и принятия решений. Анализ данных имеет множество аспектов и подходов, охватывает разные методы в различных областях науки и деятельности.

Прежде чем говорить о выборе метода анализа данных, следует выделить фундаментальную основу любого программного продукта - основная цель или задача, которую будет решать этот продукт. От направления зависит, какую информацию необходимо подавать на вход информационной системы, а от того какой она будет на входе уже зависит сам выбор метода. Таким образом, если вектор имеет, например, экономическую направленность, то на вход будет подаваться экономическая информация (чаще выраженная в числах), а в качестве метода будет использоваться метод, работающий с такой информацией.
Наиболее часто в организациях используются экономические информационные системы, то есть системы, работающие с экономической информацией и на выходе дающие соответствующего рода результаты. Под экономической информацией понимаются сведения о процессах производства, материальных ресурсов, трудовых ресурсов, финансовых процессах и о состоянии объектов управления на определенное время. Она возникает в процессе производственной-хозяйственной деятельности хозяйствующих субъектов, а ее назначение состоит в применении для управленческих нужд. Особенности экономической информации предопределяют необходимость и экономическую целесообразность применения специальных технических средств, в том числе средств вычислительной техники, при её сборе, накоплении, передаче и обработке. Поэтому экономическая информация является как предметом, так и продуктом автоматизированной обработки. Данный вид информации чаще всего выражается в числовом формате, поэтому методам для его обработки необходимо находить причинно-следственные связи в числовых структурах для этих целей могут использоваться методы факторного анализа, регрессионного анализа и анализа панельных данных. Информация, подаваемая на вход информационной системы может быть представлена в смешанном виде или иметь отфильтрованный вид, то есть