Файл: Модель клиент-сервер (История возникновения модели).pdf
Добавлен: 13.03.2024
Просмотров: 40
Скачиваний: 0

СОДЕРЖАНИЕ
Глава 1. История возникновения модели
Глава 2. Характеристика модели
Глава 3. Архитектурные подходы на основе модели «клиент-сервер»
Глава 4. Программное обеспечение для реализации архитектуры клиент-сервер
4.1 Использование программного обеспечения одного производителя
4.2 Работа приложений с сервером БД
4.3 Средства разработки приложений
4.4 Клиентские приложения, поддерживающие протокол DDE
4.7 Поддержка группы стандартов интерфейса
Уровень презентационной логики ввода и вывода данных (Presentation Logic) как часть приложения заключается в том, что клиент приложения видит на своем экране, в ходе его работы. Сюда включаются все экранные формы интерфейса, которые пользователь видит или заполняет в ходе работы приложения, к данному уровню относится то, что показывается пользователю на экран как промежуточные итоги решения некоторых задач, либо как справочная информация. Поэтому основными задачами презентационной логики являются:
-
- формирование экранных изображений;
- чтение и запись в экранные формы информации;
- управление функционалом приложения;
- обработка движений мыши и нажатие клавиш клавиатуры.
Часть возможностей для организации презентационного уровня приложений предоставляет знако-ориентированный пользовательский интерфейс, задаваемый моделями CICS (Customer Control Information System) и IMS/DC компании IBM и моделью TSO (Time Sharing Option) для централизованной main-фреймовой архитектуры. Модель GUI -- графического пользовательского интерфейса, поддерживается в операционных средах Microsoft's Windows, Windows NT, в OS/2 Presentation Manager, X-Windows и OSF/Motif.
Уровень бизнес-логики, выполняющая преобразования данных в рамках определенных бизнес-процессов (Business processing Logic), - это часть кода приложения, которая реализует алгоритмы выполнения конкретных задач. Обычно этот код пишется с использованием различных языков программирования, таких как С#, C++, Python, PHP, Visual-Basic.
Уровень логики базы данных (Data manipulation Logic) - это часть конфигурации приложения, которая реализуется на уровне БД. Данными управляет собственно СУБД (DBMS). Для обеспечения доступа к данным используются язык запросов и средства управления данными стандартного языка SQL, PL/SQL и т.д (зависит от диалекта БД).
Средства управления ресурсами БД (Database Manager System Processing) позволяют к базе данных, которая обеспечивает хранение и управление базами данных. В идеале функции СУБД должны быть скрыты от бизнес-логики приложения, однако для рассмотрения архитектуры приложения нам надо их выделить в отдельную часть приложения.
В централизованной архитектуре (Host-based processing) эти части приложения располагаются в единой среде и комбинируются внутри одной исполняемой программы.
В децентрализованной архитектуре эти процессы могут быть распределены иначе между серверным и клиентским компьютерами. В зависимости от характера распределения можно выделить следующие модели распределений:
- распределенная презентация (Distribution presentation, DP);
- удаленная презентация (Remote Presentation, RP);
- распределенная бизнес-логика (Remote business logic, RBL);
- распределенное управление данными (Distributed data management, DDM);
- удаленное управление данными (Remote data management, RDA).
Это деление показывает, каким образом может быть распределение задач между серверным и клиентскими процессами. В данном случае отсутствует реализация удаленной бизнес - логики. Таким образом, получается, что она не может быть удалена сама по себе в полной мере. Считается, что она может быть распределена между разными процессами, которые в общем-то могут исполняться на разных платформах, но должны уметь правильно взаимодействовать между собой.
Глава 3. Архитектурные подходы на основе модели «клиент-сервер»
В предыдущей главе мы прояснили принципы работы двухуровневой архитектуры взаимодействия клиент-сервер, заключающийся в том, что обработка запроса происходит на одной машине без использования сторонних ресурсов. Двухзвенная архитектура предъявляет жесткие требования к производительности сервера, но в тоже время является очень надежной. Двухуровневую модель взаимодействия клиент-сервер вы можете увидеть на рисунке ниже.
Модель клиент-сервер устанавливает лишь общие принципы взаимодействия между участниками сети, детали этого взаимодействия задают различные протоколы. Данная концепция нам говорит, что нужно разделять машины в сети на клиентские, которым всегда что-то надо и на серверные, которые дают то, что надо. При этом взаимодействие всегда начинает клиент, а правила, по которым происходит взаимодействие описывает протокол.
В традиционной модели клиент-сервер приходится распределять три составляющие приложения по двум физическим машинам. Обычно ПО хранения данных располагается на сервере базы данных, интерфейс приложения с пользовательскими представлениями на машине клиента, а вот обработку данных необходимо распределять между клиентской и серверной частями. Именно в этом и заключается недостаток двухзвенной архитектуры, из которого вытекают ограничения, сильно усложняющие реализацию клиент-серверных автоматизированных систем.
При делении алгоритмов преобразования данных приходится синхронизировать поведение обеих уровней системы. Каждый разработчик должен иметь четкое представление о последних изменениях, внесенных в систему, и ориентироваться в них. Это создает дополнительные трудозатраты при внедрении клиент-серверных систем, их реализации и сопровождении, т.к приходится тратить большие усилия на настройку взаимодействия разных групп специалистов. В поставках разработчиков часто создаются противоречия, а это тормозит развитие системы и вынуждает дорабатывать уже готовые и проверенные элементы.
Развитием распределенной архитектуры информационных систем с базами данных является трехзвенная модель с сервером приложений (Рис 2). В этом случае в системе кроме сервера базы данных и клиентских компьютеров выделяется еще одна самостоятельная компонента, так называемый сервер приложений, который помещается между клиентскими подсистемами и сервером базы данных.
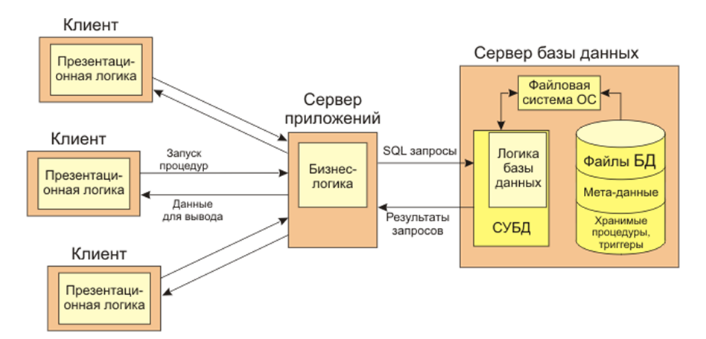
Рис. 2. Архитектура с сервером приложений
На программное обеспечение сервера приложений с клиентского звена системы перекладываются функции, реализующие бизнес-логику решаемых системой прикладных задач.
Такое распределение в первую очередь дает освобождение программного обеспечения клиентского уровня от разработки бизнес-логики приложений делает его более мобильным и масштабируемым, снижая требование к машине клиента, упрощая и унифицируя доступ и требования к пользованию автоматизированной системой вплоть до обеспечения возможности использования для доступа в приложение с помощью стандартных web-браузеров. В связи с этим подходом данное решение еще называют архитектурой с «тонким клиентом», в отличие от приведенной выше традиционной архитектуры клиент-север с гораздо тяжелее нагруженной среды клиента, получившим название «толстого клиента».
Перенос всей бизнес-логики прикладной задачи на сервер приложений значительно снижает риск проблем, связанных с модернизацией и сопровождением прикладного программного обеспечения, совместимости стороннего ПО, установленного на машине клиента и требований к уровню безопасности ПК. Процесс обновления версий приложений с «тонким клиентом» может теперь быть значительно упрощен, за счет изменений только на стороне серверной части.
Не вдаваясь в подробности, можно отметить, что такая трехзвенная архитектура, состоящая из: сервер БД, сервера приложений и машин клиентской стороны, обладает значительной гибкостью и масштабируемостью, повышает надежность системы и ее уровень безопасности.
Безусловно, использование подобной архитектуры приложения очень трудоемко в реализации и проектировании. Необходимо гарантировать надежность работы, целостность данных и их непротиворечивость, необходимые перекодировки и транслитерации, поддержку стабильного многопользовательского режима, мощные инструменты мониторинга и администрирования. Таким образом, для разработки приложений с распределенной базой данных и распределенной обработкой применяются специальные распределенные СУБД. Наиболее известными из них являются Oracle, Postgre, InterBase, SQLServer, Sybase. Наиболее промышленные из них, например, дают возможность единовременно использовать в одном приложении, работающем на сети, различные виды машин серверов и их операционных систем, сетевых протоколов и СУБД.
Во избежание неконсистентности различных элементов архитектуры, обычно выполняют преобразование данных на одной из двух физических частей - либо на стороне клиента ("толстый" клиент), либо на сервере ("тонкий" клиент, или архитектура, называемая "2,5 - уровневый клиент-сервер"). Каждая реализация имеет свои плюсы и минусы. В первом случае довольно сильно перегружается сеть, поскольку по ней транслируются исходные данные без предварительной обработки, в большинстве случаев избыточные. Вдобавок, усложняется сопровождение системы и ее доработки, так как изменение алгоритма вычислений или исправление ошибки влечет за собой изменение всех экземпляров программ на стороне клиентской составляющей. С другой стороны, если вся логика выполняется на стороне сервера, возникает проблема написания сложной логики, редких вещей и выполнение каких то действий на машине клиента вне приложения (к примеру, работа с принтером клиента, или запуск сторонней программы).
Не так давно модель клиент-сервер была модернизирована и доработана. Появилась архитектура, называемая равный к равному (peer to peer). Она реализована, например, в СУБД InterBase компании Borland и в СУБД Oracle Enterprise Edition 7 версии. При этом подходе все участники сети являются равноправными, т.е. они приходятся в роли и клиента и в роли сервера одновременно. Из любого сегмента сети есть возможность запросить и обновить информацию, имеющуюся на любом другом участнике сети. При такой реализации деление компьютеров на серверы и клиенты становится условным и непостоянным, но, т.к участники-серверы нуждаются в достаточно больших вычислительных ресурсов, архитектура равный к равному является ресурсоемкой задачей, а, следовательно, дорогой.
Очевидно, на сегодняшний день проще организовать работу с распределенной БД гетерогенной структуры, в которой часть узлов является и серверами и клиентами одновременно, а другая часть значится только в роли клиентов. Следует заметить, что поскольку сервер БД обеспечивает одновременную работу с данными нескольких пользователей, он должен работать в высоконагруженной или многопользовательской ОС (например, NetWare, OS/2, VMS, Unix , MVS, VM, Windows NT).
Подводя итог, сравнивая два рассмотренных архитектурных подхода можно выделить следующее:
Двухзвенная архитектура проще, так как все запросы обслуживаются одним сервером, но именно из-за этого она менее масштабируема и предъявляет повышенные требования к производительности сервера. Трехзвенная архитектура сложнее и выдвигает высокие требования к поддержке системы, но благодаря тому, что функции распределены между серверами второго и третьего уровня, эта архитектура представляет:
- Высокую степень гибкости и масштабируемости.
- Высокую отказоустойчивость (т.к. компоненты архитектуры обособлены друг от друга).
- Высокую производительность (т.к. задачи распределены между серверами и могут выполняться параллельно).
Глава 4. Программное обеспечение для реализации архитектуры клиент-сервер
В ситуации, когда имеется перечень разнотипных машин с различными операционными системами, включенных в глобальную или локальную сеть, а на этих машинах развернуты БД различных компаний, то можно построить автоматизированную систему, работающую с данными из нескольких БД. При этом в сети могут использоваться различные сетевые протоколы, СУБД могут поддерживать различные модели данных (сетевую, реляционную, иерархическую, навигационную, инвертированные списки и т. д.), а часть данных может храниться в файлах операционных систем.
Но в текущее время, когда выгода от интегрированного использования данных очевидна, а перечень компьютеров меняется все чаще, эту задачу приходится решать оперативно. Сегодня имеется несколько вариантов реализации в подобном сетевом ландшафте приложения с архитектурой клиент-сервер и обеспечить, чтобы одно и то же приложение клиента взаимодействовало с разными серверами БД, и его не требовалось дорабатывать при смене сервера БД.
Наиболее частые решения для подобных ситуаций:
1. Использование на всех компьютерах программного обеспечения одного производителя;
2. Использование на персональных компьютерах-клиентах популярных персональных СУБД с "дополнительными" пакетами для этих СУБД, позволяющими им работать с сервером БД конкретной компании;
3. Использование для разработки клиентских приложений специальных высокоуровневых инструментальных средств разработки приложений, умеющих работать с основными реляционными серверами БД;
4. Использование в качестве платформы для клиентских приложений персональных компьютеров с MS Windows, на которых работают пакеты, обеспечивающие стандарт обмена данными DDE;
5. Использование на компьютерах-клиентах и компьютерах-серверах пакетов, поддерживающих один из стандартов интерфейса клиент-сервер (ODBC, IDAPI, DAL и т.д.);
6. Использование пакетов, поддерживающих совокупность стандартов интерфейса клиент - сервер и позволяющих использовать в макрокомандах и процедурах на языке 4GL различных прикладных пакетов единый набор команд для работы с БД, файлами, почтовыми системами и т.д.;

