ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 19.04.2024
Просмотров: 22
Скачиваний: 0

Лекція 11
Тема: Опис концепцій та методологій розпізнавання.
План
-
Основні задачі.
-
Алгоритми розпізнавання.
-
Опис концепцій та методологій.
1. Основні задачі, що виникають при розробці систем розпізнавання образів
Задачі, що виникають при побудові автоматичної системи розпізнавання образів, можна звичайно віднести до декількох основних областей. Перша з них пов'язана з представленням" початкових даних, одержаних як результати вимірювань для підмета розпізнаванню об'єкту. Це проблема чутливості. Кожна зміряна величина є деякою "характеристикою образу або об'єкту. Припустимо, наприклад, що образами є буквенноцифрові символи. B такому випадку в датчику може бути успішно використана вимірювальна сітківка, подібно приведеній на мал. 2.1,а. Якщо сітківка складається з n елементів, то результати вимірювань можна представити у вигляді вектора вимірювань або вектора образу.
(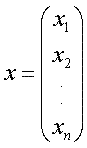 1)
1)
де кожний елемент xi, приймає, наприклад, значення 1, якщо через i-ю осередок сітківки проходить зображення символу, і значення 0 інакше. B подальшому викладі називатимемо вектори образів просто чинами в тих випадках, коли це не приводить до зміни значення.
Другий приклад проілюстрований на мал. 2.1,6. B цьому випадку чинами служать безперервні функції (типу звукових сигналів) змінної t. Якщо вимірювання значень функцій проводиться в дискретних точках t1,t2 ..., tn, вектор образу можна сформувати, прийнявши x1= f(t1),x2=f(t2)..., xn = f(tn).
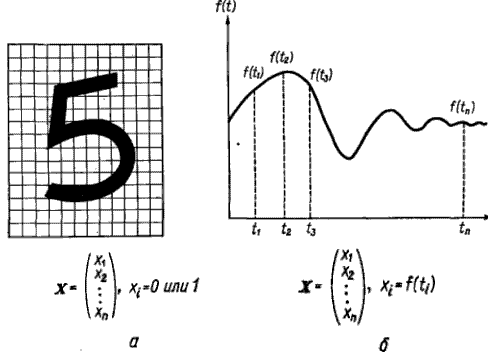
Мал. 2.1 - Дві прості схеми породження вектора образу;
Вектори образів позначатимуться рядковими буквами, виділеними жирним шрифтом, наприклад х, у і z. Умовимося, що ці вектори скрізь будуть вектор-стовпцями, як в рівнянні (1). Еквівалентний запис х=(х1,x2...,xn) ', де штрих позначає транспонування, також використовуватиметься в тексті.
Вектори образів містять всю інформацію, що піддається вимірюванню, про образи. Процес вимірювання, якому піддаються об'єкти певного класу образів, можна розглядати як процес кодування, що полягає в привласненні кожній характеристиці образу символу з безлічі елементів алфавіту {xi}. Коли вимірювання приводять до інформації, представленої дійсними числами, часто виявляється корисним розглядати вектори образів як точки n-мірного евклидова простору. Безліч образів, що належать одному класу, відповідає сукупності крапок, розсіяних в деякій області простору вимірювань. Відповідний простий приклад приведений на мал. 2.2 для випадку двох класів, позначених w1 і w2. B цьому прикладі передбачається, що класи w1 і w2 представляють відповідно групи футболістів професіоналів і жокеїв. Кожний "образ" характеризується результатами двох вимірювань: зростанням і вагою. Вектори образів мають, отже, вигляд X = (X1, X2)', де параметр х1 - зростання, а параметр х2 - вага. Кожний вектор образу можна вважати точкою двовимірного простору. Як випливає з мал. 2.2 ці два класи утворюють непересічні множини що пояснюється характером параметрів, що вимірювалися. B практичних ситуаціях, проте, далеко не завжди вдається вибрати вимірювані параметри так, щоб одержати строго непересічні множини. B частковості, якщо як критерії розбиття вибрано зростання і вагу, може спостерігатися істотне, перетин класів представляючих професійних футболістів і баскетболістів.
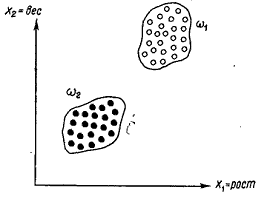 Мал.
2.2 - Два непересічні класи образів;
Мал.
2.2 - Два непересічні класи образів;
Друга задача розпізнавання образів пов'язана з виділенням характерних ознак або властивостей з одержаних початкових даних і зниженням розмірності векторів образів. Цю задачу часто визначають як задачу попередньої обробки і вибору ознак. При розпізнаванні мови, наприклад, можна відрізняти голосні і півголосні звуки від фрикативних і деяких інших консонант, вимірюючи частотний розподіл енергії в спектрах. Ширше за все при розпізнаванні мови використовуються такі ознаки, як тривалість звуку, відносини величин енергії в різних діапазонах частот, розташовують піків спектрів і їх зсув в часі.
Ознаки класу образів є характерними властивостями, загальними для всіх образів даного класу. Ознаки, що характеризують відмінності між окремими класами, можна інтерпретувати як міжкласові ознаки. Внутрікласові ознаки, загальні для всіх даних класів, не несуть корисної інформації з погляду розпізнавання і можуть не братися до уваги. Вибір ознак вважається однією з важливих задач, пов'язаних з побудовою розпізнавальних., систем. Якщо результати вимірювань дозволяють одержати повний набір розрізняльних ознак для всіх класів, власне розпізнавання і класифікація образів не викличуть особливих утруднень. Автоматичне розпізнавання тоді зведеться до процесу простого зіставлення або процедур типу проглядання таблиць. B більшості практичних задач розпізнавання, проте, визначення повного набору розрізняльних ознак виявляється справою виключно важкою, якщо взагалі не неможливим. На щастя, з початкових даних звичайно вдається витягнути. деякі з розрізняльних ознак і використовувати їх для спрощення процесу автоматичного розпізнавання образів. B частковості, розмірність векторів вимірювань можна понизити за допомогою перетворень, що забезпечують мінімізацію втрати інформації.
Третя задача, пов'язана з побудовою систем розпізнавання образів, полягає у відшуканні оптимальних вирішальних процедур, необхідних при ідентифікації і класифікації. Після того, як дані, зібрані про належні розпізнаванню образи, представлені крапками або векторами вимірювань в просторі образів, надамо машині з'ясувати, якому класу образів ці дані відповідають. Хай машина призначена для розрізнення M класів, позначених w1, w2 ... ..., wm B такому випадку простір образів можна вважати таким, що складається з M областей, кожна з яких містить крапки, відповідні образам з одного класу. При цьому задача розпізнавання може розглядатися як побудова меж областей рішень, розділяючих M класів, виходячи із зареєстрованих векторів вимірювань. Хай ці межі визначені, наприклад, вирішальними функціями d1(х),d2(x)..., dm(х). Ці функції, звані також дискримінантними функціями, є скалярними і однозначними функціями образу х. Якщо di (х) > dj (х) для всіх _, j= 1, 2 ..., M, j ? _, то образ х належить класу w1. Іншими словами, якщо i-я вирішальна функція di(x) має найбільше значення, то X_WI. Змістовною ілюстрацією подібної схеми автоматичної класифікації, заснованої на реалізації процесу ухвалення рішення, служить приведена на мал. 2.3 блоксхема (на схемі ГРФ означає "генератор вирішальних функцій").
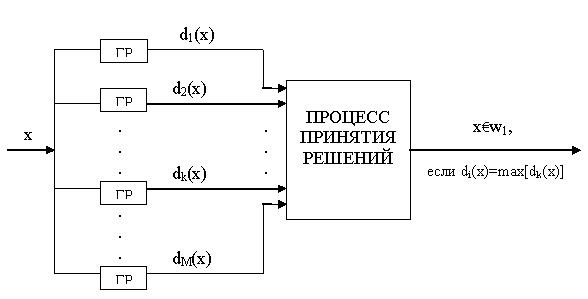
Мал. 2.3 - Блоксхема системи класифікації образів;
Вирішальні функції можна одержувати цілим рядом способів. B тих випадках, коли про розпізнавані образи є повні апріорні відомості, вирішальні функції можуть бути визначені точно на основі цієї інформації. Якщо щодо образів є лише якісні відомості, можуть бути висунуті розумні допущення про вид вирішальних функцій. B останньому випадку межі областей рішень можуть істотно відхилятися від істинних, і тому необхідно створювати систему, здатну приходити до задовільного результату за допомогою ряду послідовних коректувань. Ho, як правило, ми володіємо лише нечисленними (якщо вони взагалі є!) апріорними відомостями про розпізнавані образи. B цих умовах при побудові системи, що розпізнає, краще всього використовувати повчальну процедуру. Ha першому етапі вибираються довільні вирішальні функції і потім в процесі виконання ітеративних кроків навчання ці вирішальні функції доводяться до оптимального або прийнятного вигляду. Класифікацію об'єктів за допомогою вирішальних функцій можна здійснювати самими різними способами. B даній книзі ми вивчимо декілька і статистичних алгоритмів детерміністів знаходження вирішальних функцій.
Рішення задачі попередньої обробки і виділення ознак і задачі отримання оптимального рішення і класифікації звичайно пов'язано з необхідністю оцінки і оптимізації ряду параметрів. Це приводить до задачі оцінки параметрів. Крім того, зрозуміло, що і процес виділення ознак, і процес ухвалення рішень можуть бути істотно вдосконалені за рахунок використовування інформації, укладеної в контексті образів. Інформація, що міститься в контексті, може бути зміряна за допомогою умовної вірогідності, лінгвістичної статистик і близьких варіантів. B деяких додатках просто необхідно використовувати контекстуальну інформацію для точного розпізнавання. B частковості, повна автоматизація розпізнавання мови можлива тільки за наявності контекстуальної і лінгвістичної інформації, доповнюючої інформацію, що міститься в записі звукових сигналів мови. З аналогічних причин украй бажане залучення контекстуальної інформації при розпізнаванні скоропису і класифікації відбитків пальців. Намагаючись побудувати ту, що розпізнає систему, стійку по відношенню до перешкод, здатну справитися з істотними відхиленнями розпізнаваних об'єктів і володіючу здібністю до самонастройки, ми зустрічаємося із задачею адаптації.
Об'єкти (образи), що підлягають розпізнаванню і класифікації за допомогою автоматичної системи розпізнавання образів, повинні володіти набором вимірних характеристик. Коли для цілої групи образів результати відповідних вимірювань виявляються аналогічними, вважається, що ці об'єкти належать одному класу. Мета роботи системи розпізнавання образів полягає в тому, щоб на основі зібраної інформації визначити клас об'єктів з характеристиками, аналогічними зміряним у розпізнаваних об'єктів. Правильність розпізнавання залежить від об'єму различаюшей інформації, що міститься у вимірюваних характеристиках, і ефективності використовування цієї інформації. Якби ми були в змозі зміряти всі можливі характеристики і володіли необмеженим часом для обробки зібраної інформації, то можна б було досягти цілком адекватного рівня розпізнавання, використовуючи найпримітивніші методи. B звичайній практиці, проте, обмеження за часом, простору і витратам вимагають розвитку реалістичних підходів.
2. Алгоритми розпізнавання образів
Теорія технічного зору існує не перший день, по цьому в літературі можна знайти достатньо підходів і рішень. Спершу перерахую деякі з них:
1 Алгоритм скелетизации.
Коротко, це якийсь метод розпізнавання одинарних бінарних образів, заснований на побудову скелетів цих образів і виділення з скелетів ребер і вузлів. Далі по співвідношенню ребер, їх числу і числу вузлів будується таблиця відповідності образам. Так, наприклад, скелетом круга буде один вузол, скелетом букви П - три ребра і два вузли, причому ребра відносяться як 2:2:1. В програмуванні даний метод має декілька можливих реалізацій, докладніше інформацію по методу скелетезации можна знайти нижче в розділі посилання.
2 Нейромережні структури. Напрям був дуже модним в 60е-70е роки, надалі інтерес до них трохи зменшив, т.к солідне число нейронів вимагає солідні обчислювальні потужності, які звичайно відсутні на простеньких мобільних платформах. Проте треба мати зважаючи на, що нейросети іноді дають вельми цікаві результати, засчет своєї нелінійної структури, більш того деякі нейросети здатні распозновать образи інваріантні щодо повороту без якої або зовнішньої передобробки. Так наприклад мережі на основі неокогнейтронов здатні виділяти деякі характерні риси образів, і розпізнавати їх як би образи не були повернені. Докладніше про ці структури можено взнати в розділі посилання.
3 Інваріантні числа. З геометрії образів можна виділити деякі числа, інваріантні щодо розміру і повороту образів, далі можна скласти таблицю відповідності цих чисел конкретному образу(майже як в алгоритмі скелетезации). Приклади інваріантних числі - число эллера, экцентриситет, орієнтація(в значенні розташовує головної осі інерції щодо чего-нить теж інваріантного). Деяку інформацію і мат. частину можна знайти в розділі посилання нижче.
4 Выдсоткове порівняння з еталоном по точкам.
Тут повинна бути деяка передобробка, для отримання інваріантності щодо розміру і положення, потім здійснюється порівняння із заготовленою базою еталонів зображень - якщо збіг більш ніж якась відмітка, то вважаємо образ розпізнаним.
3. Опис концепцій і методології
B основі ідеї синтезу систем автоматичного розпізнавання лежать способи, за допомогою яких описуються і розділяються класи образів. Коли клас характеризується переліком вхідних в нього членів, побудова системи, розпізнавання образів може бути засновано на принципі приналежності до цього переліку. Коли клас характеризується деякими загальними властивостями, властивими всім його членам, побудова системи розпізнавання може грунтуватися на принципі спільності властивостей. Коли при розгляді класу виявляється тенденція до утворення кластерів в просторі образів, побудова системи розпізнавання може грунтуватися на принципі кластеризації. Під кластером розуміють звичайно групу об'єктів (образів), створюючих в просторі опису компактну в деякому розумінні область. Ці три основні принципи побудови систем розпізнавання образів обговорюються нижче.

