Файл: Разработка приложений для мобильных устройств (C#, Java) с использованием.pdf
Добавлен: 16.02.2024
Просмотров: 126
Скачиваний: 1
СОДЕРЖАНИЕ
Глава 1 Изучение предметной области
1.1 Описание разрабатываемого приложения
1.2 Моделирование разрабатываемого приложения
1.2.1 Моделирование приложения с использованием UML
1.2.2 Модель сценариев использования
1.3 Анализ существующих приложений для составления списка покупок
1.4 Обзор и обоснование выбора инструментария для разработки приложения
1.5 Обоснование необходимости разработки приложения
Глава 2. Реализация мобильного приложения
2.1 Сбор данных для создания базы данных
2.3 Основные функции программы
2.3.1. Предоставление списка рецептов и выбор рецепта для составления списка покупок
2.3.2. Добавление имеющихся продуктов
2.3.3. Составление списка покупок
2.4.1. Распознавание по виду продуктов
2.4.2. Распознавание по тексту на продукте
Основным отличием от большинства аналогичных мобильных приложений является возможность распознать название продукта простым наведением камеры на продукт или его часть. На вкладке «Продукты» при нажатии на кнопку добавление продукта, пользователю предоставляется возможность выбирать метод из списка. Рассмотрим каждый метод детально.
2.4.1. Распознавание по виду продуктов
Рассмотрим возможность распознавания продуктов по их внешности. Предположим, что на столе пользователя приложения лежит продукт. Пользователь наводит камеру на продукт, чтобы обученная модель нейронной сети проанализировала фотографию и вывела название продукта. В этом случае пользователю не нужно вводить название продукта вручную, что очень удобно. Для реализации такой возможности есть несколько решений:
- Библиотека TensorFlow
- Фреймворк ML Kit для Firebase
- Imagga
ML Kit для Firebase и Imagga содержат множество продвинутых функций для распознавания объектов, однако большинство их них требуют платную подписку на сервис. TensorFlow в целом похож на ML Kit, поэтому и соперничает с ним, однако выбор отдается TensorFlow, как инструменту с более хорошей документацией и большим сообществом поддерживающим данную библиотеку.
Следующим важным пунктом является создание набора данных для обучения модели. Для данной задачи такими данными будут являться изображения продуктов и аннотации к ним в формате PascalVOC.
Для создания коллекции изображений продуктов питания были проанализированы различные существующие базы изображений с продуктами питаний. UECFood‐100 и Food‐101 (Bossard, 2014) содержат 100 категории продуктов с 1000 изображений в каждой. Данные изображения имеют хорошее качество, однако представляют собой завершенные блюда, а не отдельные ингредиенты, потому было решено найти изображения конкретных продуктов питания. Так, например, база изображений Fruits 360 содержит изображения около 130 фруктов и овощей, что подходит под требования нашего приложения. В базе изображений Open Image Dataset V6 компании Google также находятся изображения некоторых продуктов вместе с аннотациями в определенном формате. В качестве источника изображения также удобно использовать поисковую систему Google, скачивая изображения, по ключевым словам, соответствующим разным продуктам. Кроме того, для всех изображений необходимо изменить размеры разрешения до 800 на 600 пикселей, что в последствии поможет в тренировке моделей нейронной сети.
Формат PascalVOC содержит информацию о границах распознаваемого изображения внутри исходного, а также данные о файле изображения. Во время работы над проектом было использован как ручной метод маркировки изображений с помощью программы LabelImg, так и автоматическое конвертирование данных путем обработки аннотаций к изображениям Open Image Dataset V6.
Для тренировки нейронной сети было решено использовать следующие модели: COCO SSD MobileNet v1 и Faster R-CNN Inception v2. Данные модели были представлены как наиболее подходящие для мобильных устройств, поэтому было решено использовать именно их. Сверточная часть MobileNet состоит из одного обычного сверточного слоя с 3х3 свёрткой в начале и тринадцати блоков, изображенных справа на рисунке, с постепенно увеличивающимся числом фильтров и понижающейся пространственной размерностью тензора. Особенностью данной архитектуры является отсутствие max pooling-слоёв. Описанная выше модель была тренирована на данных MS-COCO и выпущена в 2019 году. R-CNN использует выборочный поиск (J.R.R. Uijlings, 2012) для поиска регионов интереса, после чего алгоритм передает их в сверточную нейронную сеть. Затем полученные карты признаков классифицируются по методу SVM (методу опорных векторов). В Faster версии модели выборочный поиск заменен на небольшую нейронную сеть, которая использует имеющуюся карту признаков для предположения о местонахождении регионов интереса.
Среди двух описанных моделей наиболее хороший результат при параметрах по умолчанию получился у COCO SSD MobileNet не только по точности (loss=1.16 у MobileNet против loss=1.24 у Inception), но и по скорости получения прогноза результата (быстрее в 21 раз). После тренировки обеих моделей, их работа была протестирована на фотографиях, сделанных в домашних условиях. Результатом тестом стало то, что Faster R-CNN справлялось с задачей в 85% случаев против 80%. Обе модели хорошо справляется с распознаванием средних и больших объектов, однако хуже справляется с маленькими объектами, так как большинство изображений в тренировочном наборе данных имеет большой размер.
В итоге, полученная модель была сконвертирована в формата .tflite для использования в мобильном приложении. При наведении на продукт появляется рамка, показывающая местоположение найденного продукта, а внизу экрана появляется его наименование. При этом учитываются только те распознавания, коэффициент доверия к котором больше порогового значения. При нажатии на кнопку «Добавить» найденный продукт добавляется в список продуктов пользователя.



Рис. 9. Распознавание продукта по внешнему виду
2.4.2. Распознавание по тексту на продукте
Рассмотрим возможность распознавания продуктов по их тексту. В этом случае пользователю для распознавания продукта, будет необходимо навести камеру на текст, находящийся на поверхности продукта, например, на название продукта на этикетке. С помощью машинного обучения текст продукта будет распознан, и пользователь получит возможность добавить его название в список. Для реализации такой возможности есть несколько решений:
- ML Kit от Firebase
- TensorFlow
- Tesseract OCR
Mobile Vision Text API от компании Google, входящий в пакет ML Kit сервиса Firebase, позволяет распознавать текст, при этом текст делится на блоки, строки и отдельные элементы, что удобно при анализе и обработке различных объемов текста. Tesseract OCR это библиотека с исходным кодом, которая осуществляет оптическое распознавание символов (англ. optical character recognition, OCR) на изображениях, и имеющая около 200 обученных языковых моделей. Основным моментом при выборе инструмента являлось качество распознавания русских символов, поэтому предпочтение было отдано сервису компании Google.
Когда пользователь нажимает на кнопку «Распознать» приложение получает изображение с камеры телефона и отправляет его на сервер, после чего получает get- запрос с распознанным текстом. Таким образом для работы данной функции необходимо подключение к интернету, которое есть у большинства владельцев смартфонов.
Так как на упаковке продукта присутствует большое количество текстовой информации, показывающей информацию о производителе, названии товара и его описании было решено:
- Использовать центральную часть экрана для распознавания только той информации, на которую указывает пользователь
- Предоставить возможность пользователь составить итоговое название продукта, путем выбора частей распознанного текста, которые должны в нем быть

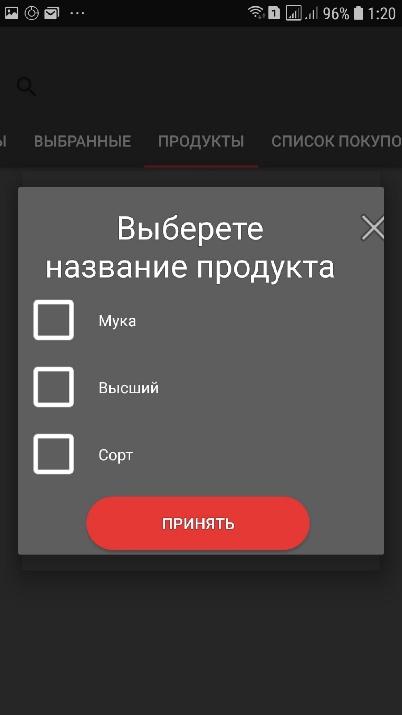
Рис. 10. Распознавание продуктов по тексту
2.4.3. Распознавание по штрих-коду
Кроме приведённых ранее способов продукт можно распознать по штрих-коду. Самым популярным штрих-кодом у российских продуктов является линейный штрих-код с символикой EAN-13, представляющий из себя последовательность полосок разной ширины и кодирующих небольшой объем информации. Получив код EAN-13, можно узнать наименование, а иногда изображение, бренд и производителя продукта.
Для реализации, данной возможность необходим сканер штрих-кода. В интернете существует множество готовых решений, основная функциональность которых очень похожа. Примерами таких решений являются Barcode Recognition SDK от компании Dynamsoft и библиотека ZXing, находящаяся в свободном доступе на сервисе онлайн-хостинга репозиториев GitHub. Так как продукт компании Dynamsoft является платным, то было решено использовать библиотеку ZXing. Её особенностью является простота встраивания в приложение и поддержка различных форматов штрих-кодов, в том числе и EAN-13. Кроме того при работе камеры должен работать автофокус, так как это упрощает распознавание изображения штрих-кода, и данная функция поддерживается в библиотеке ZXing.
После распознавания кода продукта приложение получает информацию о его названии. Данная функция была реализована, путем разработки базы данных, в которой находятся EAN коды продуктов питания и соответствующие им названия продуктов. Для этого использовалась информация из справочника штрихкодов, расположенного в репозитории GitHub (UhttBarcodeReference, 2020). Из полученных данных была отобрана информация о продуктах питания, а также удалены все английские наименования товаров. Кроме того, из названий продуктов были убраны сокращения, числа и знаки препинания. Так как наиболее быстрым способом работы с таким объемом данных, является работа с базой данных, то из полученных данных была сформирована SQLite база данных с штрих-кодами продуктов. Данный файл загружается на телефон пользователя и используется для быстрого получения информации. Так как в названии полученного таким способом продукта может находиться бренд, тип или другая информация о продукте, было решено использовать такой же метод формирования названия продукта, как и для распознавания продукта по тексту.

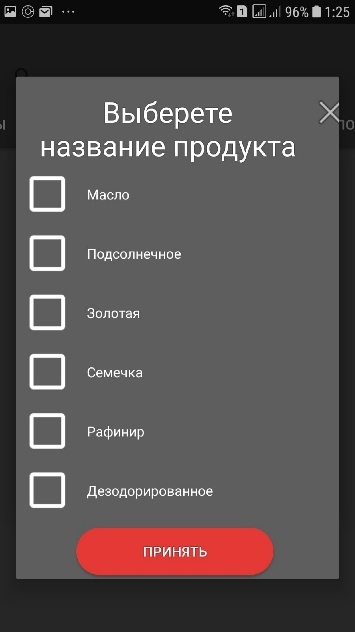
Рис. 11. Пример распознавания штрих-кода
Достоинства такого подхода:
- Высокая точность полученной информации, так как название продукта берется из базы данных
Недостатки:
- Пользователю требуется время, чтобы найти штрих-код на упаковке товара
- Не все продукты имеют штрих-код
2.5. Ручной ввод наименования продукта
И наконец последним методом для добавления продукта является ручной ввод названия продукта. Несмотря на кажущуюся простоту такого подхода по сравнению с предыдущими, пользователю будет необходимо самому вводить название продукта с использованием клавиатуры телефона, что является менее удобным решением по сравнению с вручную написанными списками покупок.
В приложении была добавлена функция автоматического предложения наименования продукта по набранной пользователем части, реализованная через использование компонента AutoCompleteTextView и базы продуктов, полученной из интернета. Это ускоряет процесс ручного ввода названия продукта.
Достоинства такого подхода:
- Позволяет пользователю назвать продукт по своему усмотрению
Недостатки:
- Пользователю нужно набирать текст
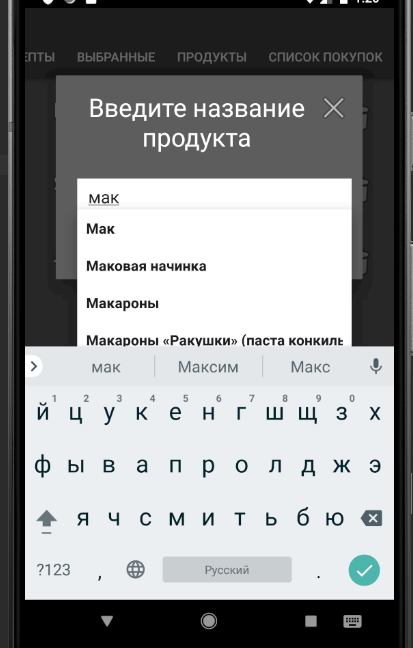
Рис. 12. Ручной ввод наименования продукта
2.5. Тестирование работы приложения
Для тестирования разрабатываемого приложение было решено использовать функциональное тестирование, которое включает в себя проверку реализуемости функциональных требований. При тестировании было решено использовать как встроенные в Android Studio эмулятор мобильного устройства с версией Android API 27, так и на реальном мобильном устройстве с версией Android API 26. В таблице 5 представлена информация о результате прохождение системой тестов.
Таблица 5. Список тестов
|
№ |
Название теста |
Ожидаемый результат |
Полученный результат |
|
1. |
Просмотр списка рецептов на вкладке «Рецепты» и деталей отдельного рецепта |
Рецепты в списке содержат корректное изображение, автора и название текста. При клике на рецепт открывает страница рецепта. Ингредиенты соответствуют рецепту. Инструкция по приготовлению раскрывается при нажатии на кнопку «Увидеть больше». |
Тест пройден |
|
2. |
Добавление и удаление рецепта их списка выбранных |
При нажатии на кнопку «Добавить в выбранные» рецепт появляется на вкладке «Выбранные». Удаление рецепта из выбранного рецепта работает корректно |
Тест пройден |
|
3. |
Добавление продукта с помощью распознавания по виду |
При нажатии на кнопку «По виду» включается камера телефона. При наведении на продукт внизу экрана появляется его название. После нажатия на кнопку «Добавить» это название добавляется в список продуктов |
Тест пройден |
|
4. |
Добавление продукта с помощью распознавания по тексту |
При нажатии на кнопку «По тексту» включается камера телефона. После наведении камеры на текст и нажатия на кнопку «Распознать» открывается окно с выбором названия продукта. После нажатия на кнопку «Принять» составленное из выбранных слов название добавляется в список продуктов |
Тест пройден |
|
5. |
Добавление продукта с помощью распознавания по штрих-коду |
При нажатии на кнопку «По штрих-коду» включается камера телефона. При наведении на штрих-код продукта, открывается окно с выбором названия продукта. После нажатия на кнопку «Принять» составленное из выбранных слов название добавляется в список продуктов |
Тест пройден |
|
6. |
Добавление продукта вручную |
При нажатии на кнопку «Вручную» появляется окно ввода. При введении части названия появляется выпадающий список с корректными названиями продуктов, начинающихся с введенного слова. После нажатия на кнопку «Принять» это название добавляется в список продуктов |
Тест пройден |
|
7. |
Составление списка покупок |
При нажатии на кнопку «Сгенерировать список» появляется список ингредиентов выбранных рецептов без учета продуктов из вкладки «Продукты». Удаление продукта из списка выполняется успешно. |
Тест пройден |