Файл: Операции, производимые с данными (Обзор существующих решений операций, производимые с данными).pdf
Добавлен: 29.02.2024
Просмотров: 50
Скачиваний: 0
СОДЕРЖАНИЕ
Глава 1. Обзор существующих решений операций, производимые с данными
Глава 2. Описание работы с данными
2.1 Функциональность приложения с точки зрения пользователя
2.2 Используемые технологии и детали реализации web-приложения
2.3 Общие элементы кастомизации интерфейса
2.4 Документация по использованию интерфейса с произвольными данными
Содержание:
Введение
Процедура доступа к данным может быть инициирована как самим компьютером (для решения каких-либо своих технических задач), так и конечным пользователем. В последнем случае пользователь формирует запрос, куда включает, в частности, обозначение требуемого вида доступа или действия и указание на то, над какими данными это действие надо выполнить. Как отмечалось ранее, идентификация данных осуществляется с помощью ключей. В качестве же требуемого действия может производиться одно из следующих: добавление, удаление, изменение, просмотр элемента или обработка данных из элемента.
При добавлении элемента информационный массив пополняется новыми данными в виде записи файла или файла в целом, соответственно, для структурированных и неструктурированных данных. В запросе в этом случае, помимо указанной выше информации, приводится и сам новый элемент. При этом объем информационного массива увеличивается.
Удаление, наоборот, является обратным действием, вызывающим исключение упомянутых данных. Это действие приводит к уменьшению объема информационного массива.
Изменение относится не к элементу, а к его составляющим – полям записи файла или тексту, хранящемуся в файле, и означает, в свою очередь, удаление прежних значений полей или строк текста и/или добавление новых. В запрос включается дополнительная информация, указывающая на требуемые составляющие изменяемого элемента, а также сами новые значения этих составляющих. Объем информационного массива при этом не меняется для структурированных данных и, возможно, меняется для неструктурированных;
Просмотр связан с предоставлением данных пользователю на устройстве вывода компьютера, как правило, на дисплее. В запросе в этом случае дополнительно указывается, какие составляющие элемента требуется просмотреть (по умолчанию просматривается весь элемент).
Обработка предусматривает выполнение некоторых арифметических операций над данными элемента, например, накопление суммы и т.д., и относится только к структурированным данным, а потому далее не рассматривается.
Стоить заметить, что концепция распределенных вычислений сложнее для восприятия. При этом, на данный момент есть не так много проектов, где предпринимаются попытки визуализировать алгоритм в действии. Одним из самых известных является реализация raft.io [1], которая на основном информационном сайте алгоритма Raft [2] показывает принцип его работы с помощью анимации. Визуализация дает базовое понимание о работе алгоритма Raft, но она реализована для одного конкретного алгоритма и для одного конкретного тестового случая.
По причине отсутствия обширности визуализационной базы, когда студенты сталкиваются с темой распределенных вычислений впервые, уходит достаточно много времени на прорисовку «от руки» того, как меняются состояния узлов при взаимодействии, какой процесс отправил сообщение другому процессу и т.д. Это занимает достаточно много времени на лекциях и семинарах. Процесс обучения мог бы стать проще, если бы была возможность демонстрации работы данных в действии, с применением минимальных усилий.
Для этой цели разрабатывается проект “Parallel and Conquer” (PAC). Проект состоит из backend и frontend частей, взаимодействующих между собой. Frontend-часть отвечает за визуализацию данных для демонстрации, тестирования и дебага. Backend-часть реализует алгоритмы и тестовые сценарии для некоторых из них (на данный момент это Алгоритм пекарни Лэмпорта (Lamport Mutex) [3], Paxos [4], Raft). В данной работе будет описана frontend-часть проекта.
При создании инструментов, которые будут использоваться в образовательных целях, важно учитывать универсальность. Так как студенты используют разное программное обеспечение, выбор был сделан в сторону Web-приложения, как универсального решения для всех платформ.
PAC также должен был учитывать проблемы уже существующих решений и избегать их. Перед проектом ставились следующие требования:
- Простота использования
- Отсутствие зависимости от платформы
- Возможность отобразить основные алгоритмы, изучаемые в университетах, показав их особенности
- Возможность визуализации данных пользователя, вне зависимости от того, какие языки программирования ему известны
В соответствии с этим был выбран протокол общения между клиентом и сервером через определенный application programming interface (API) так, что, если в дальнейшем базовый backend-сервер меняется на пользовательский, для User Interface (UI) части ничего не меняется, если используется тот же API.
Далее будет сделан краткий обзор существующих решений в данной области, а затем будут описаны все детали использования интерфейса PAC, его техническая реализация и особенности.
Глава 1. Обзор существующих решений операций, производимые с данными

Есть несколько инструментов для визуализации и тестирования, помогающих в изучении распределенных данных. Ниже приведен краткий обзор некоторых из них:
Xtango [5] — это система анимации данных общего назначения, которая помогает программистам реализовывать анимированное отображение своих собственных данных. Недостатки этой системы:
- необходимость написания программы на языке C или создание файла трассировки, который читаем драйвером C
- невозможность отображения дополнительной информации о состояниях процессов для тестирования и отладки
Polka [6] — это система анимирования, которая подходит для визуализации однопоточных и параллельных программ. Основным недостатком этой реализации является то, что она требует Motif или Xaw (набор виджетов Athena), поэтому пользователь должен приложить дополнительные усилия для использования этой системы.
“A tool for interactive visualization of distributed algorithms” [7] (название проекта не указано) — это инструмент для визуализации распределенных вычислений. Он имеет ограниченный список данных, написанных на Java, но пользователь может реализовать свой собственный алгоритм, вызывая определенные методы из своего Java- кода. Требование знать определенный язык программирования может помешать некоторым студентам использовать этот инструмент визуализации, и в этом заключается недостаток данного решения.
У проекта Lydian [8] есть инструмент, разработанный, по словам авторов, для образовательных целей, который помогает в изучении распределенных данных. В проекте используется библиотека Polka для визуализации, обзор которой приведен выше. Анимация позволяет наблюдать за взаимодействием процессов, причинно-следственными связями и логическими временами. Тем не менее, в окошке приложения может быть отражена только одна компонента из всего приложения, из-за чего у пользователя нет возможности сравнивать и проводить связи между процессами, журналами, уникальным состоянием процесса и тем, как они влияют друг на друга.
Проект ViSiDiA [9] — это самый современный из перечисленных инструмент для визуализации с настраиваемым интерфейсом. Недостатки этого проекта заключаются в следующем:
- пользователь должен знать и использовать язык программирования Java
- для визуализации пользовательского проекта в код должны быть встроены методы библиотеки ViSiDiA
- загрузка проекта с официального сайта является сложной задачей из-за необходимости прямого контакта с разработчиками
Таким образом, существующие на данный момент решения имеют недостатки, которые могут быть существенны при выборе инструмента для визуализации и тестирования. “Parallel and Conquer” старается учесть проблемы описанных выше реализаций и создать простое в использовании приложение, которое будет понятно пользователю.
Глава 2. Описание работы с данными
Ниже описано, как происходит процесс использования интерфейса пользователем и как ему трактовать некоторые детали визуализации, если он совсем не знаком с распределенными алгоритмами. Затем разобраны детали реализации с более подробным описанием внутренней логики. После этого в пункте «Общие элементы кастомизации интерфейса» показано, как меняется смысл компонент приложения в зависимости от проигрываемого алгоритма. В последнем пункте основной части описано, как пользователь должен использовать API и особенности приложения для понятной визуализации своего собственного алгоритма.
Во всем документе слова “узел”, “процесс” и “нода” (от англ. node) будут использованы, как синонимы, во избежание излишних повторений.
2.1 Функциональность приложения с точки зрения пользователя
Для пользователя PAC — это single page application (SPA или одностраничное приложение). Первое, что он видит, заходя в браузер, — это форма с несколькими полями.
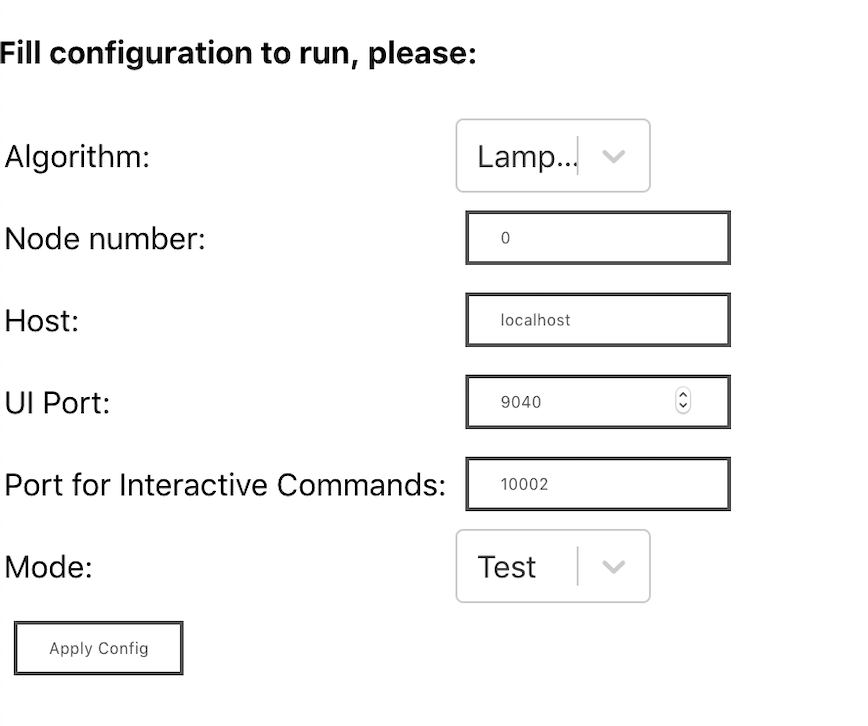
Рисунок 1. Функциональность приложения
Первым этапом предлагается выбрать алгоритм, который нужно визуализировать и тестировать. Пользователь может выбрать один из четырех данных: Lamport Mutex, Paxos, Raft, Custom[1].
В зависимости от выбранного алгоритма будут предложены варианты дополнительных полей для заполнения[2].
Общими для всех данных полями являются “Node number”, “Host”, “UI Port”. “Node number” не должно быть меньше одного или превышать 20. Ограничение по числу было сделано из-за редкого изучения и демонстрации в образовательных учреждениях алгоритмах, на числе узлов больше 10, и из-за потенциального нагромождения визуальных элементов. В поле “Host” нужно указать localhost или IPv4 ip-адрес тестирующего сервера. В поле “UI Port” требуется указать порт, по которому происходит общение с UI по Websocket.
При корректном заполнении полей и нажатию кнопки “Apply Config”, будет происходить переход на следующий view.

Рисунок 2. View перед запуском алгоритма.
В нижнем левом углу доступны 2 кнопки: “PLAY” и “Change Config”. Для запуска теста следует нажать первую, для изменения конфигурации алгоритма — вторую.
Выше кнопок располагается ScrollBar, с помощью которого при проигрывании теста можно будет отматывать тест назад и перепроигрывать сценарий.
В правом нижнем углу располагается область Logs, где при проигрывании теста будут записываться логи, приходящие с сервера.
В правом верхнем углу можно увидеть 2 формы — “Time slowdown” и “View slowdown”. “Time slowdown” замедляет (а при желании, ускоряет) время проигрывания теста так, что изменения будут происходить в x * базовая скорость исполнения раз медленнее (или быстрее). “View slowdown” «замедляет» отображение, то есть визуализация становится шире, чем предполагается по линейной зависимости между реальным временем и сеткой координат визуализации. По умолчанию “Time slowdown” — это 1.0, то есть скорость отображения соотносится 1:1; “View slowdown” — 10, чтобы все сообщения не сливались в одно при передаче от узла к узлу (процесса к процессу).
Остальные компоненты до запуска теста не несут никакой информации.
При нажатии кнопки “PLAY” происходит запуск тестового сценария выбранного алгоритма в соответствии со сценарием на сервере, и появляются новые детали визуализации.
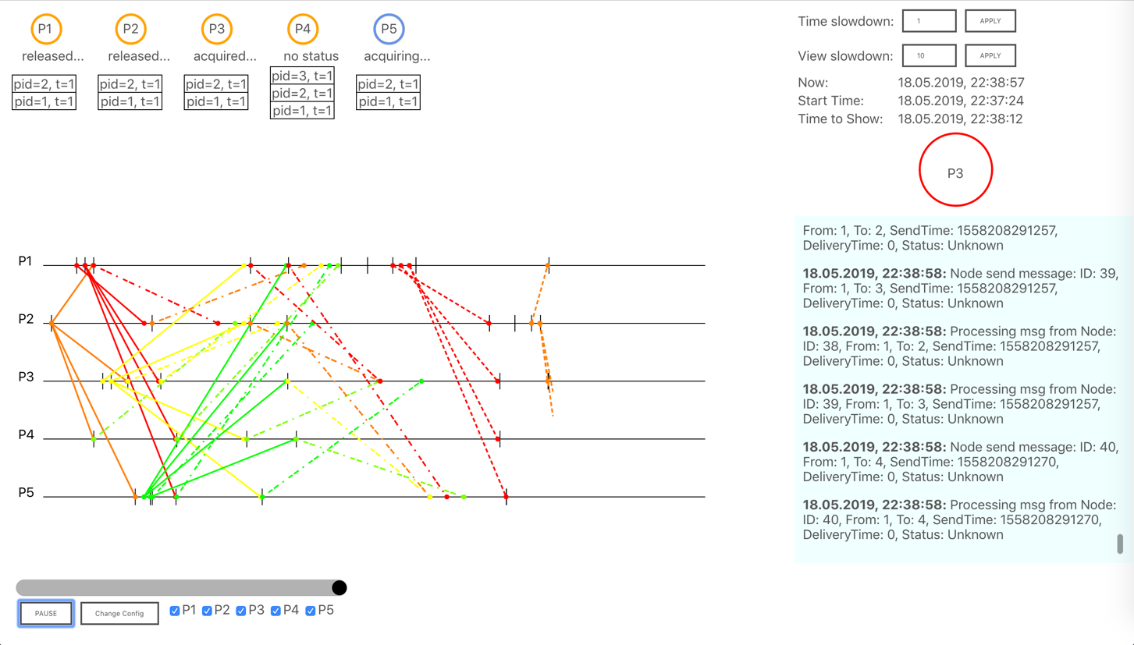
Рисунок 3. View во время исполнения алгоритма.
В верхней части слева располагаются стеки (или очереди) внутренних состояний нод. Каждая нода имеет свою очередь, в которой отражается информация, специфичная для алгоритма[3]. При наведении показывается расширенная информация о записи в стеке/очереди и подсвечивается временная метка на линии времени, которая соответствует добавлению этой записи в стек. При желании воспользоваться «ручным режимом» – режим исполнения, при котором пользователь сам инициирует действия со стороны процессов – необходимо кликнуть по номеру ноды над очередью состояния. Появится Popup, в котором можно выбрать действие, которое должна выполнить нода. Для закрытия popup нужно совершить клик в любом месте вне него. На текущем этапе развития проекта, «ручной режим» работает для данных Lamport Mutex и Raft.