Файл: В., Фомин С. С. Курс программирования на языке Си Учебник.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 16.03.2024
Просмотров: 194
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Глава 8
ПОДГОТОВКА И ВЫПОЛНЕНИЕ
ПРОГРАММ
Упрощенная схема подготовки программ, существующая во многих операционных системах, изображена на рис. 8.1 (см. также §2.1, рис. 2.1).
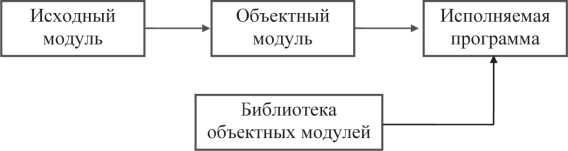
Рис. 8.1. Упрощенная схема подготовки исполняемой программы
Текст программы, набранный в любом текстовом редакторе и сохраненный в файле в виде последовательности символов, называется исходным модулем. Имена файлов, содержащих тексты программ и функций на языке Си, обычно имеют расширение «с».
Исходные модули обрабатываются компилятором, в результате чего получается промежуточный модуль, называемый объектным. Объектный модуль состоит из двух основных частей: тела модуля, представляющего собой программу в кодах команд конкретной ЭВМ, и заголовка, содержащего внешние имена (имена переменных, используемых в данном модуле, но определенных в других модулях). Эта информация необходима для построения из набора объектных модулей программы или программной системы, готовой к выполнению.
Объектные модули обрабатываются компоновщиком, который строит исполняемую программу, содержащую только команды ЭВМ. В зависимости от операционной системы исполняемую программу могут называть исполняемым файлом, exe-модулем, загрузочным модулем и т. п. При построении исполняемой программы к объектным модулям, полученным из исходных модулей, подключаются объектные модули из одной или нескольких библиотек, содержащих, например, объектные модули функций ввода-вывода, вспомогательных библиотечных функций (обработка строк, массивов, выделение динамической памяти и т. д.).
Существование промежуточного объекта (модуля) в цепочке построения, готовой к выполнению программы, позволяет:
На различных этапах разработки программы может применяться разная технология сборки готовой к выполнению программы, например:
Даже небольшая программа обычно содержит значительное количество функций и текстов определений и описаний внешних (глобальных) объектов, размещенных в отдельных файлах.
Развитие любой программы приводит к тому, что в итоге ее структура становится сложной, и программисту трудно удержать в голове логическую схему этой структуры. Постоянно следить за файлами, которые требуют перекомпиляции после внесения изменений, становится невозможным.
Современные операционные системы и системы программирования предлагают пользователю средства, в той или иной степени решающие задачу автоматизации разработки программ.
В этой главе рассмотрим средства подготовки программ в операционных системах семейства как UNIX.
в операционной системе UNIX
В UNIX для документирования взаимосвязей между модулями и для автоматизации построения программной системы служит утилита make. Исходной информацией для утилиты make является описание взаимосвязей модулей, на основе которого утилита make собирает программу. При дальнейших модификациях текстов отдельных частей программы описание взаимосвязей модулей позволяет утилите make перестраивать при сборке программной системы только ту часть системы, которая подверглась модификации.
Схема подготовки исполняемой программы в UNIX приведена на рис. 8.2.
От традиционной для почти всех операционных систем схемы подготовки исполняемых программ схема на рис. 8.2 отличается тем, что в UNIX трансляция исходного модуля ведется на языке
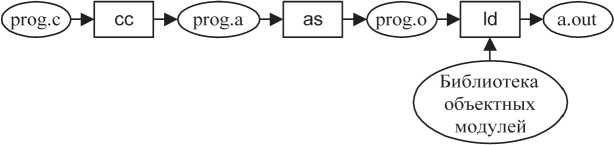

Рис. 8.2. Схема подготовки исполняемой программы в UNIX: *.c - исходный модуль на языке Си;
*.a- модуль на ассемблере; *.o- объектный модуль; a.out- стандартное имя исполняемого модуля (исполняемой программы); cc- компилятор языка Си; as- компилятор языка ассемблера; ld- компоновщик (редактор связей)
ассемблера и исполняемый модуль, если не указано другого, имеет стандартное имя a.out. Выбор фиксированного имени объясняется тем, что UNIX в свое время создавалась для удобной разработки и отладки программ. В режиме отладки нет необходимости хранить промежуточные версии исполняемых программ и вполне можно называть их одним именем.
Компилятор Си позволяет за один вызов выполнить всю цепочку преобразования исходного модуля в исполняемую программу. Для задания последовательности преобразований в команде вызова компилятора сначала указываются ключи компилятора и затем параметры компоновщика.
Формат команды cc, вызывающей компилятор языка Си, предусматривает задание следующих параметров (в форматах команд операционных систем принято помещать необязательные элементы в квадратные скобки [ ]):
сс [-ключи] исходные_модули [ключи_компоновщика] [объектные_модули] [библиотеки]
где
□ ключи - однобуквенные параметры, задающие режимы работы компилятора. Перед каждым ключом должен стоять знак минус ('-'). После некоторых ключей могут указываться дополнительные параметры. Приведем некоторые (наиболее часто употребляемые) ключи команды сс:
-1 библиотека_объектных_модулей
Примечание
Способ указания имени библиотеки объектных модулей объясняется ниже в разделе «Библиотеки объектных модулей».
Если программа состоит из одного исходного модуля с именем main.c, то для построения исполняемого модуля достаточно выполнить команду (% - «приглашение» от операционной системы): %cc main.c
Исходный модуль будет последовательно преобразован (см. рис. 8.2) в модуль на языке ассемблера, объектный модуль, исполняемый модуль. Исполняемый модуль получит стандартное имя a.out. При повторном вызове компилятора языка Си командой сс и указании в качестве параметра команды имени другого исходного модуля вновь полученный исполняемый модуль также будет иметь имя a.out, но будет соответствовать другому исходному (только что обработанному) модулю.
Для того чтобы определить произвольное имя исполняемого модуля, необходимо в команде вызова компилятора указать ключ -о и сразу за ним через пробел задать имя исполняемого модуля:
%cc -o begin main.c
Построение исполняемого модуля можно провести в два этапа с промежуточным получением объектного модуля:
%cc -c main.c
%cc -o begin main.o
В первой строке применен ключ -с, в результате чего процесс обработки исходного модуля прервется, когда будет получен объектный модуль (main.o).
Во второй строке определено имя исполняемого модуля begin и в качестве параметра команды сс указано имя объектного модуля (main.o), полученного на предыдущем этапе.
8.3. Утилита make
Утилита make позволяет документировать взаимосвязи между модулями и освобождает пользователя от рутинной работы по слежению за изменениями в модулях.
Утилита make при вызове обновляет (перестраивает) исполняемый модуль, причем транслируются только те функции, в исходные тексты которых были внесены изменения.
Исходными данными для утилиты make служит файл описаний зависимостей модулей. Описания зависимостей модулей и соответствующих действий хранятся в так называемом make-файле, который по умолчанию называется makefile или Makefile. В этом случае он может не указываться при вызове команды make. При выборе для make-файла (файла зависимостей) произвольного имени часто назначают имена, начинающиеся с заглавной буквы, так как при просмотре содержимого каталога (в UNIX для просмотра используется команда ls -1) они будут располагаться в верхней части списка модулей каталога, что облегчает поиск и распознавание make-файлов.
Приведем текст файла зависимостей модулей для иллюстративной программы, состоящей из следующих модулей: add_node.c, new_node.c, print.c. В простейшем случае make-файл будет выглядеть так:
tree: tree.o add_node.o new_node.o print.o
%cc -o tree tree.o add_node.o new_node.o print.o
В первой строке первым параметром перед символом ':' указывается имя так называемого целевого файла, а после символа ':' приводится список имен файлов, от которых зависит целевой файл. Эта строка информирует утилиту make о необходимости выполнить команду, записанную в следующей строке, если какой-либо из объектных модулей (файлы *.o) имеет более позднюю дату модификации, по сравнению с целевым файлом tree, являющимся в нашем примере исполняемым модулем иллюстративной программы.
Если какой-либо из исходных модулей на препроцессорном уровне включает файл с текстом части программы, то описание зависимостей файлов необходимо дополнить соответствующей строкой по следующему образцу:
prog.o a.o: def.h
Здесь указано, что объектные модули prog.o и a.o зависят от включаемого (директивой #include) файла def.h.
Помимо описаний зависимостей, утилита make использует в процессе своего выполнения набор так называемых встроенных правил.
Одно из основных правил: повторно должны быть откомпилированы лишь те исходные модули, дата последней модификации которых оказалась старше даты создания соответствующего им объектного модуля. Компилируются, конечно, и те исходные модули, для которых соответствующие объектные модули не существуют. Таким образом, утилита make осуществляет лишь те минимальные действия, без которых невозможно было бы получить новую версию целевого файла.
Формат файла описаний зависимостей модулей. Файл описаний зависимостей модулей представляет собой текстовый файл, содержащий последовательность строк, которые являются набором спецификаций взаимозависимостей, используемых утилитой make при ее выполнении. Спецификация взаимозависимостей имеет следующую структуру:
Формат спецификации взаимозависимостей следующий:
target1[ target2 . . . ]:[:][depend1 . . .][# . . .] [(tab)commands][#]
где (квадратные скобки означают необязательность элементов):
Примечание
Если список имен файлов, от которых зависит целевой файл, не умещается на одной строке, для обозначения переноса части списка на другую строку можно воспользоваться символом '\', например:
tree: tree.o \
add_node.o \
new_node.o \ print.o команды UNIX
Формат команды make. Команда make имеет следующий формат: make [-f makefile][ключи][имена][макроопределения]
Квадратные скобки, выделяющие параметры, означают их необязательность. Параметры в команде отделяются друг от друга пробелами.
Первый параметр с ключом -f задает имя файла зависимостей модулей, если это имя отлично от makefile или Makefile.
Из множества ключей, определяющих режим работы утилиты make, упомянем следующие, необходимые для отладки make-файла:
Параметр имена позволяет задавать имена целевых файлов.
Коротко остановимся на некоторых возможностях утилиты make, которые не используются в нашем примере.
Макроопределения. Утилита make позволяет использовать при записи спецификаций взаимозависимостей макроопределения. Это дает возможность добиться большей наглядности файла описаний взаимозависимостей и использовать один и тот же файл описаний для различных имен целевых файлов и файлов, от которых зависит целевой файл.
Макроопределения записываются в соответствии со следующим форматом:
имя_макроса = значение
где имя_макроса - имя макроса утилиты make; значение - строка символов, которая подставляется вместо конструкции $(имя_ма- кроса) при ее использовании в строках файла взаимозависимостей.
Пример макроопределения:
CC=cc
После такого макроопределения контекст вида $(CC) будет заменен в строках make-файла на сс.
Введем в качестве первой строки в приведенный выше файл описаний взаимозависимостей для целевого файла tree следующее макроопределение:
OBJECTS=tree.o add_node.o new_node.o print.o
Тогда позже в том же файле для указания объектных модулей, перечисленных справа от знака равенства, можно применять конструкцию $(OBJECTS).
Теперь файл взаимозависимостей для рассматриваемой программы будет выглядеть так:
OBJECTS=add_node.o new_node.o print.o
tree: tree.o $(OBJECTS)
cc -o tree tree.c $(OBJECTS)
Встроенные правила. В процессе выполнения команда make использует набор так называемых встроенных правил. Одним из подмножеств этого набора являются правила автоматического установления взаимосвязей между файлами по суффиксам их имен. Например, когда в команде make в качестве параметра задано имя файла с суффиксом '.c', автоматически выполняется вызов компилятора языка Си, который строит исполняемый модуль из исходного модуля, находящегося в заданном файле. Таблицу встроенных правил утилиты make, соответствующих конкретной реализации UNIX, можно найти в документации по операционной системе. Здесь стандартные встроенные правила мы рассматривать не будем.
Программист может изменить встроенное правило, для чего новый вариант правила необходимо включить в файл описаний зависимостей, то есть во входные данные для make.
Простейшее правило, описывающее процедуру подготовки исполняемого модуля из исходного модуля (расширение имени 'с', суффикс имени '.с'), будет выглядеть так:
.c:
cc -o $@ $*.c
где $@ - внутренний макрос утилиты make, предназначенный для спецификации полного имени целевого файла; $* - внутренний макрос, определяющий префикс имени файла.
Это правило, включенное в файл описаний зависимостей модулей, заменит внутреннее правило утилиты make для суффикса '.c'.
Если теперь ввести команду make с указанием имени целевого файла (исполняемой программы)
%make prog
то исходный файл prog.c будет скомпилирован, а исполняемый модуль получит имя prog.
С помощью утилиты make может быть решено множество задач, связанных с программированием как на языках высокого уровня, так и на командных языках (например, на командном языке UNIX - csh), однако основное ее применение - учет взаимозависимостей между исходными текстами модулей в больших программных комплексах.
8.4. Библиотеки объектных модулей
При разработке программной системы объектные модули функций, входящих в ее состав, целесообразно размещать в библиотеках объектных модулей, а в командной строке вызова компилятора указывать эти библиотеки. Использование библиотек позволяет не перечислять непосредственно в командной строке все необходимые для построения исполняемой программы объектные модули. Компоновщик на этапе построения исполняемой программы будет выбирать из библиотеки только те объектные модули функций, которые необходимы.
ПОДГОТОВКА И ВЫПОЛНЕНИЕ
ПРОГРАММ
-
Схема подготовки программ
Упрощенная схема подготовки программ, существующая во многих операционных системах, изображена на рис. 8.1 (см. также §2.1, рис. 2.1).
Рис. 8.1. Упрощенная схема подготовки исполняемой программы
Текст программы, набранный в любом текстовом редакторе и сохраненный в файле в виде последовательности символов, называется исходным модулем. Имена файлов, содержащих тексты программ и функций на языке Си, обычно имеют расширение «с».
Исходные модули обрабатываются компилятором, в результате чего получается промежуточный модуль, называемый объектным. Объектный модуль состоит из двух основных частей: тела модуля, представляющего собой программу в кодах команд конкретной ЭВМ, и заголовка, содержащего внешние имена (имена переменных, используемых в данном модуле, но определенных в других модулях). Эта информация необходима для построения из набора объектных модулей программы или программной системы, готовой к выполнению.
Объектные модули обрабатываются компоновщиком, который строит исполняемую программу, содержащую только команды ЭВМ. В зависимости от операционной системы исполняемую программу могут называть исполняемым файлом, exe-модулем, загрузочным модулем и т. п. При построении исполняемой программы к объектным модулям, полученным из исходных модулей, подключаются объектные модули из одной или нескольких библиотек, содержащих, например, объектные модули функций ввода-вывода, вспомогательных библиотечных функций (обработка строк, массивов, выделение динамической памяти и т. д.).
Существование промежуточного объекта (модуля) в цепочке построения, готовой к выполнению программы, позволяет:
-
сделать систему программирования гибкой и удобной в эксплуатации за счет предварительной разработки библиотек объектных модулей, содержащих множество вспомогательных функций; -
разрабатывать и использовать собственные библиотеки объектных модулей, содержащие функции, общие для отдельных частей программной системы; -
при модификации программной системы перестраивать только части, подвергшиеся доработке.
На различных этапах разработки программы может применяться разная технология сборки готовой к выполнению программы, например:
-
главная функция и все подготовленные программистом вспомогательные функции находятся в одном текстовом файле; -
главная функция и вспомогательные функции находятся в разных текстовых файлах, но собираются в один исходный модуль с помощью препроцессорных команд #include; -
главная функция и вспомогательные функции находятся в разных текстовых файлах, транслируются отдельно, и исполняемая программа собирается компоновщиком из объектных модулей; -
вспомогательные функции транслируются отдельно, отлаживаются на тестовых примерах, и из них формируют личную библиотеку объектных модулей, которая применяется для сборки программ.
Даже небольшая программа обычно содержит значительное количество функций и текстов определений и описаний внешних (глобальных) объектов, размещенных в отдельных файлах.
Развитие любой программы приводит к тому, что в итоге ее структура становится сложной, и программисту трудно удержать в голове логическую схему этой структуры. Постоянно следить за файлами, которые требуют перекомпиляции после внесения изменений, становится невозможным.
Современные операционные системы и системы программирования предлагают пользователю средства, в той или иной степени решающие задачу автоматизации разработки программ.
В этой главе рассмотрим средства подготовки программ в операционных системах семейства как UNIX.
-
Подготовка программ
в операционной системе UNIX
В UNIX для документирования взаимосвязей между модулями и для автоматизации построения программной системы служит утилита make. Исходной информацией для утилиты make является описание взаимосвязей модулей, на основе которого утилита make собирает программу. При дальнейших модификациях текстов отдельных частей программы описание взаимосвязей модулей позволяет утилите make перестраивать при сборке программной системы только ту часть системы, которая подверглась модификации.
Схема подготовки исполняемой программы в UNIX приведена на рис. 8.2.
От традиционной для почти всех операционных систем схемы подготовки исполняемых программ схема на рис. 8.2 отличается тем, что в UNIX трансляция исходного модуля ведется на языке
Рис. 8.2. Схема подготовки исполняемой программы в UNIX: *.c - исходный модуль на языке Си;
*.a- модуль на ассемблере; *.o- объектный модуль; a.out- стандартное имя исполняемого модуля (исполняемой программы); cc- компилятор языка Си; as- компилятор языка ассемблера; ld- компоновщик (редактор связей)
ассемблера и исполняемый модуль, если не указано другого, имеет стандартное имя a.out. Выбор фиксированного имени объясняется тем, что UNIX в свое время создавалась для удобной разработки и отладки программ. В режиме отладки нет необходимости хранить промежуточные версии исполняемых программ и вполне можно называть их одним именем.
Компилятор Си позволяет за один вызов выполнить всю цепочку преобразования исходного модуля в исполняемую программу. Для задания последовательности преобразований в команде вызова компилятора сначала указываются ключи компилятора и затем параметры компоновщика.
Формат команды cc, вызывающей компилятор языка Си, предусматривает задание следующих параметров (в форматах команд операционных систем принято помещать необязательные элементы в квадратные скобки [ ]):
сс [-ключи] исходные_модули [ключи_компоновщика] [объектные_модули] [библиотеки]
где
□ ключи - однобуквенные параметры, задающие режимы работы компилятора. Перед каждым ключом должен стоять знак минус ('-'). После некоторых ключей могут указываться дополнительные параметры. Приведем некоторые (наиболее часто употребляемые) ключи команды сс:
-
-с - транслировать исходный модуль в объектный; -
-p - провести только препроцессорную обработку исходного модуля; -
-s - транслировать исходный модуль в модуль на языке ассемблера; -
-o имя_исполняемой_программы - при необходимости транслировать и задать отличное от стандартного «a.out» имя для исполняемой программы; -
исходные_модули - полные имена (с расширением «с») одного или нескольких исходных модулей; -
объектные_модули - полные имена (с расширением «о») тех модулей, которые будут использованы при построении исполняемой программы; -
ключи_компоновщика - задают режимы работы компоновщика (для нас представляет интерес ключ -l, определяющий имя библиотеки объектных модулей):
-1 библиотека_объектных_модулей
Примечание
Способ указания имени библиотеки объектных модулей объясняется ниже в разделе «Библиотеки объектных модулей».
Если программа состоит из одного исходного модуля с именем main.c, то для построения исполняемого модуля достаточно выполнить команду (% - «приглашение» от операционной системы): %cc main.c
Исходный модуль будет последовательно преобразован (см. рис. 8.2) в модуль на языке ассемблера, объектный модуль, исполняемый модуль. Исполняемый модуль получит стандартное имя a.out. При повторном вызове компилятора языка Си командой сс и указании в качестве параметра команды имени другого исходного модуля вновь полученный исполняемый модуль также будет иметь имя a.out, но будет соответствовать другому исходному (только что обработанному) модулю.
Для того чтобы определить произвольное имя исполняемого модуля, необходимо в команде вызова компилятора указать ключ -о и сразу за ним через пробел задать имя исполняемого модуля:
%cc -o begin main.c
Построение исполняемого модуля можно провести в два этапа с промежуточным получением объектного модуля:
%cc -c main.c
%cc -o begin main.o
В первой строке применен ключ -с, в результате чего процесс обработки исходного модуля прервется, когда будет получен объектный модуль (main.o).
Во второй строке определено имя исполняемого модуля begin и в качестве параметра команды сс указано имя объектного модуля (main.o), полученного на предыдущем этапе.
8.3. Утилита make
Утилита make позволяет документировать взаимосвязи между модулями и освобождает пользователя от рутинной работы по слежению за изменениями в модулях.
Утилита make при вызове обновляет (перестраивает) исполняемый модуль, причем транслируются только те функции, в исходные тексты которых были внесены изменения.
Исходными данными для утилиты make служит файл описаний зависимостей модулей. Описания зависимостей модулей и соответствующих действий хранятся в так называемом make-файле, который по умолчанию называется makefile или Makefile. В этом случае он может не указываться при вызове команды make. При выборе для make-файла (файла зависимостей) произвольного имени часто назначают имена, начинающиеся с заглавной буквы, так как при просмотре содержимого каталога (в UNIX для просмотра используется команда ls -1) они будут располагаться в верхней части списка модулей каталога, что облегчает поиск и распознавание make-файлов.
Приведем текст файла зависимостей модулей для иллюстративной программы, состоящей из следующих модулей: add_node.c, new_node.c, print.c. В простейшем случае make-файл будет выглядеть так:
tree: tree.o add_node.o new_node.o print.o
%cc -o tree tree.o add_node.o new_node.o print.o
В первой строке первым параметром перед символом ':' указывается имя так называемого целевого файла, а после символа ':' приводится список имен файлов, от которых зависит целевой файл. Эта строка информирует утилиту make о необходимости выполнить команду, записанную в следующей строке, если какой-либо из объектных модулей (файлы *.o) имеет более позднюю дату модификации, по сравнению с целевым файлом tree, являющимся в нашем примере исполняемым модулем иллюстративной программы.
Если какой-либо из исходных модулей на препроцессорном уровне включает файл с текстом части программы, то описание зависимостей файлов необходимо дополнить соответствующей строкой по следующему образцу:
prog.o a.o: def.h
Здесь указано, что объектные модули prog.o и a.o зависят от включаемого (директивой #include) файла def.h.
Помимо описаний зависимостей, утилита make использует в процессе своего выполнения набор так называемых встроенных правил.
Одно из основных правил: повторно должны быть откомпилированы лишь те исходные модули, дата последней модификации которых оказалась старше даты создания соответствующего им объектного модуля. Компилируются, конечно, и те исходные модули, для которых соответствующие объектные модули не существуют. Таким образом, утилита make осуществляет лишь те минимальные действия, без которых невозможно было бы получить новую версию целевого файла.
Формат файла описаний зависимостей модулей. Файл описаний зависимостей модулей представляет собой текстовый файл, содержащий последовательность строк, которые являются набором спецификаций взаимозависимостей, используемых утилитой make при ее выполнении. Спецификация взаимозависимостей имеет следующую структуру:
-
имя целевого файла; -
последовательность имен файлов, от которых зависит целевой файл; -
последовательность команд UNIX, которая должна быть выполнена, если дата последней модификации хотя бы одного из файлов, от которых зависит целевой файл, старше даты модификации целевого файла.
Формат спецификации взаимозависимостей следующий:
target1[ target2 . . . ]:[:][depend1 . . .][# . . .] [(tab)commands][#]
где (квадратные скобки означают необязательность элементов):
-
target ... - целевые файлы, имена которых разделяются пробелами; -
: (или ::) - разделитель - в первом случае (для ':') последующая последовательность команд UNIX (commands) должна содержаться в одной строке файла описаний, а во втором она может располагаться в нескольких строках; -
depend ... - последовательность имен файлов, от которых зависит целевой файл (разделяются пробелами); -
(tab) - символ «Табуляция», которым предваряются командные строки UNIX; -
commands - команды UNIX, с помощью которых должен быть получен целевой файл; -
# - признак начала комментария (комментарий - часть строки от символа '#' до конца строки).
Примечание
Если список имен файлов, от которых зависит целевой файл, не умещается на одной строке, для обозначения переноса части списка на другую строку можно воспользоваться символом '\', например:
tree: tree.o \
add_node.o \
new_node.o \ print.o команды UNIX
Формат команды make. Команда make имеет следующий формат: make [-f makefile][ключи][имена][макроопределения]
Квадратные скобки, выделяющие параметры, означают их необязательность. Параметры в команде отделяются друг от друга пробелами.
Первый параметр с ключом -f задает имя файла зависимостей модулей, если это имя отлично от makefile или Makefile.
Из множества ключей, определяющих режим работы утилиты make, упомянем следующие, необходимые для отладки make-файла:
-
-р - вывести в стандартный поток вывода полный список зависимостей модулей; -
-i - игнорировать коды возврата выполненных команд (позволяет отладить сложный make-файл); -
- n - вывести в стандартный поток вывода строки с командами UNIX, не выполняя их.
Параметр имена позволяет задавать имена целевых файлов.
Коротко остановимся на некоторых возможностях утилиты make, которые не используются в нашем примере.
Макроопределения. Утилита make позволяет использовать при записи спецификаций взаимозависимостей макроопределения. Это дает возможность добиться большей наглядности файла описаний взаимозависимостей и использовать один и тот же файл описаний для различных имен целевых файлов и файлов, от которых зависит целевой файл.
Макроопределения записываются в соответствии со следующим форматом:
имя_макроса = значение
где имя_макроса - имя макроса утилиты make; значение - строка символов, которая подставляется вместо конструкции $(имя_ма- кроса) при ее использовании в строках файла взаимозависимостей.
Пример макроопределения:
CC=cc
После такого макроопределения контекст вида $(CC) будет заменен в строках make-файла на сс.
Введем в качестве первой строки в приведенный выше файл описаний взаимозависимостей для целевого файла tree следующее макроопределение:
OBJECTS=tree.o add_node.o new_node.o print.o
Тогда позже в том же файле для указания объектных модулей, перечисленных справа от знака равенства, можно применять конструкцию $(OBJECTS).
Теперь файл взаимозависимостей для рассматриваемой программы будет выглядеть так:
OBJECTS=add_node.o new_node.o print.o
tree: tree.o $(OBJECTS)
cc -o tree tree.c $(OBJECTS)
Встроенные правила. В процессе выполнения команда make использует набор так называемых встроенных правил. Одним из подмножеств этого набора являются правила автоматического установления взаимосвязей между файлами по суффиксам их имен. Например, когда в команде make в качестве параметра задано имя файла с суффиксом '.c', автоматически выполняется вызов компилятора языка Си, который строит исполняемый модуль из исходного модуля, находящегося в заданном файле. Таблицу встроенных правил утилиты make, соответствующих конкретной реализации UNIX, можно найти в документации по операционной системе. Здесь стандартные встроенные правила мы рассматривать не будем.
Программист может изменить встроенное правило, для чего новый вариант правила необходимо включить в файл описаний зависимостей, то есть во входные данные для make.
Простейшее правило, описывающее процедуру подготовки исполняемого модуля из исходного модуля (расширение имени 'с', суффикс имени '.с'), будет выглядеть так:
.c:
cc -o $@ $*.c
где $@ - внутренний макрос утилиты make, предназначенный для спецификации полного имени целевого файла; $* - внутренний макрос, определяющий префикс имени файла.
Это правило, включенное в файл описаний зависимостей модулей, заменит внутреннее правило утилиты make для суффикса '.c'.
Если теперь ввести команду make с указанием имени целевого файла (исполняемой программы)
%make prog
то исходный файл prog.c будет скомпилирован, а исполняемый модуль получит имя prog.
С помощью утилиты make может быть решено множество задач, связанных с программированием как на языках высокого уровня, так и на командных языках (например, на командном языке UNIX - csh), однако основное ее применение - учет взаимозависимостей между исходными текстами модулей в больших программных комплексах.
8.4. Библиотеки объектных модулей
При разработке программной системы объектные модули функций, входящих в ее состав, целесообразно размещать в библиотеках объектных модулей, а в командной строке вызова компилятора указывать эти библиотеки. Использование библиотек позволяет не перечислять непосредственно в командной строке все необходимые для построения исполняемой программы объектные модули. Компоновщик на этапе построения исполняемой программы будет выбирать из библиотеки только те объектные модули функций, которые необходимы.