Файл: Конспект лекций по дисциплине прикладные компьютерные технологии Направление подготовки 09. 03. 01 Информатика и вычислительная техника.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 20.03.2024
Просмотров: 74
Скачиваний: 0
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.

К источникам больших данных относят:
-
Интернет — соцсети, блоги, СМИ, форумы, сайты, интернет вещей (IoT). -
Корпоративные данные — транзакционная деловая информация, архивы, базы данных. -
Показания устройств — датчиков, приборов, а также метеорологические данные, данные сотовой связи и т. д. -
При этом нельзя сказать, что есть отдельные виды больших данных — суть метода в том, что он объединяет самые различные типы данных и извлекает из них новую, ранее недоступную информацию.
Для корректного функционирования система больших данных должна быть основана на определенных принципах:
-
Горизонтальная масштабируемость. Поскольку данных может быть сколь угодно много – любая система, которая подразумевает обработку больших данных, должна быть расширяемой. В 2 раза вырос объём данных – в 2 раза увеличили количество железа в кластере и всё продолжило работать. -
Отказоустойчивость. Принцип горизонтальной масштабируемости подразумевает, что машин в кластере может быть много. Например, Hadoop-кластер Yahoo имеет более 42000 машин (по этой ссылке можно посмотреть размеры кластера в разных организациях). Это означает, что часть этих машин будет гарантированно выходить из строя. Методы работы с большими данными должны учитывать возможность таких сбоев и переживать их без каких-либо значимых последствий. -
Локальность данных. В больших распределённых системах данные распределены по большому количеству машин. Если данные физически находятся на одном сервере, а обрабатываются на другом – расходы на передачу данных могут превысить расходы на саму обработку. Поэтому одним из важнейших принципов проектирования BigData-решений является принцип локальности данных – по возможности обрабатываем данные на той же машине, на которой их храним.
Разница подходов
| Традиционная аналитика | Big data аналитика |
| Постепенный анализ небольших пакетов данных | Обработка сразу всего массива доступных данных |
| Редакция и сортировка данных перед обработкой | Данные обрабатываются в их исходном виде |
| Старт с гипотезы и ее тестирования относительно данных | Поиск корреляций по всем данным до получения искомой информации |
| Данные собираются, обрабатываются, хранятся и лишь затем анализируются | Анализ и обработка больших данных в реальном времени, по мере поступления |
Функции и задачи, связанные с Big Data
Когда говорят о Big Data, упоминают правило VVV — три признака или свойства, которыми большие данные должны обладать:
-
Volume — объем (данные измеряются по величине физического объема документов). -
Velocity — данные регулярно обновляются, что требует их постоянной обработки. -
Variety — разнообразные данные могут иметь неоднородные форматы, быть неструктурированными или структурированными частично.
В России под Big Data подразумевают также технологии обработки, а в мире — лишь сам объект исследования.
| Функция | Задача |
| Big Data — собственно массивы необработанных данных | Хранение и управление большими объемами постоянно обновляющейся информации. Объем данных в сотни терабайт или петабайт не позволяет легко хранить и управлять ими с помощью традиционных реляционных баз данных. |
| Data mining — процесс обработки и структуризации данных, этап аналитики для выявления закономерностей | Структурирование разнообразных сведений, поиск скрытых и неочевидных связей для приведения к единому знаменателю. Большинство всех данных Big Data являются неструктурированными. Т.е. как можно организовать текст, видео, изображения, и т.д.? |
| Machine learning — процесс машинного обучения на основе обнаруженных связей в процессе анализа | Аналитика и прогнозирование на основе обработанной и структурированной информации. Как анализировать неструктурированную информацию? Как на основе Big Data составлять простые отчеты, строить и внедрять углубленные прогностические модели? |

В 2007 году стал популярен новый тип машинного обучения — Deep learning (Глубокое обучение). Он позволил усовершенствовать нейронные сети до уровня ограниченного искусственного интеллекта. При обычном машинном обучении компьютер извлекал опыт через примеры программиста, а при Deep Learning система уже сама создает многоуровневые вычисления и делает выводы.
Хранение и управление Big Data
Big Data обычно хранятся и организуются в распределенных файловых системах.
В общих чертах, информация хранится на нескольких (иногда тысячах) жестких дисках, на стандартных компьютерах. Так называемая «карта» (map) отслеживает, где (на каком компьютере и/или диске) хранится конкретная часть информации.
Для обеспечения отказоустойчивости и надежности, каждую часть информации обычно сохраняют несколько раз, например – трижды. Так, например, предположим, что вы собрали индивидуальные транзакции в большой розничной сети магазинов. Подробная информация о каждой транзакции будет храниться на разных серверах и жестких дисках, а «карта» (map) индексирует, где именно хранятся сведения о соответствующей сделке.
С помощью стандартного оборудования и открытых программных средств для управления этой распределенной файловой системой (например, Hadoop), сравнительно легко можно реализовать надежные хранилища данных в масштабе петабайт.
Неструктурированная информация
Большая часть собранной информации в распределенной файловой системе состоит из неструктурированных данных, таких как текст, изображения, фотографии или видео.
Это имеет свои преимущества и недостатки. Преимущество состоит в том, что возможность хранения больших данных позволяет сохранять “все данные”, не беспокоясь о том, какая часть данных актуальна для последующего анализа и принятия решения. Недостатком является то, что в таких случаях для извлечения полезной информации требуется последующая обработка этих огромных массивов данных.
Хотя некоторые из этих операций могут быть простыми (например, простые подсчеты, и т.д.), другие требуют более сложных алгоритмов, которые должны быть специально разработаны для эффективной работы на распределенной файловой системе.
В то время как объем данных может расти в геометрической прогрессии, возможности извлекать информацию и действовать на основе этой информации, ограничены и будут асимптотически достигать предела. Важно, чтобы методы и процедуры для построения, обновления моделей, а также для автоматизации процесса принятия решений были разработаны наряду с системами хранения данных, чтобы гарантировать, что такие системы являются полезными и выгодными для предприятия.
Анализ Big Data
Это действительно большая проблема, связанная с анализом неструктурированных данных Big Data. Для упрощения анализа были разработан алгоритм map-reduce.
При анализе сотни терабайт или петабайт данных, не представляется возможным извлечь данные в какое-либо другое место для анализа. Процесс переноса данных по каналам на отдельный сервер или сервера (для параллельной обработки) займет слишком много времени и требует слишком большого трафика. Вместо этого, аналитические вычисления должны быть выполнены физически близко к месту, где хранятся данные.
MapReduce – это модель распределенной обработки данных, предложенная компанией Google для обработки больших объёмов данных на компьютерных кластерах. MapReduce неплохо иллюстрируется следующей картинкой (взято по ссылке):
M
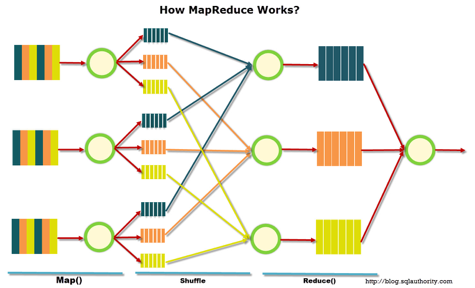 apReduce предполагает, что данные организованы в виде некоторых записей. Обработка данных происходит в 3 стадии:
apReduce предполагает, что данные организованы в виде некоторых записей. Обработка данных происходит в 3 стадии:-
Стадия Map. На этой стадии данные предобрабатываются при помощи функции map(), которую определяет пользователь. Работа этой стадии заключается в предобработке и фильтрации данных. Работа очень похожа на операцию map в функциональных языках программирования – пользовательская функция применяется к каждой входной записи. Функция map() примененная к одной входной записи и выдаёт множество пар ключ-значение. Множество – т.е. может выдать только одну запись, может не выдать ничего, а может выдать несколько пар ключ-значение. Что будет находится в ключе и в значении – решать пользователю, но ключ – очень важная вещь, так как данные с одним ключом в будущем попадут в один экземпляр функции reduce. -
Стадия Shuffle. Проходит незаметно для пользователя. В этой стадии вывод функции map «разбирается по корзинам» – каждая корзина соответствует одному ключу вывода стадии map. В дальнейшем эти корзины послужат входом для reduce. -
Стадия Reduce. Каждая «корзина» со значениями, сформированная на стадии shuffle, попадает на вход функции reduce(). Функция reduce задаётся пользователем и вычисляет финальный результат для отдельной «корзины». Множество всех значений, возвращённых функцией reduce(), является финальным результатом MapReduce-задачи.
Таким образом, скажем, для вычисления итоговой суммы, алгоритм будет параллельно вычислять промежуточные суммы в каждом из узлов распределенной файловой системы, и затем суммировать эти промежуточные значения.
Несколько дополнительных фактов про MapReduce:
1) Все запуски функции map работают независимо и могут работать параллельно, в том числе на разных машинах кластера.
2) Все запуски функции reduce работают независимо и могут работать параллельно, в том числе на разных машинах кластера.
3) Shuffle внутри себя представляет параллельную сортировку, поэтому также может работать на разных машинах кластера. Пункты 1-3 позволяют выполнить принцип горизонтальной масштабируемости.
4) Функция map, как правило, применяется на той же машине, на которой хранятся данные – это позволяет снизить передачу данных по сети (принцип локальности данных).
5) MapReduce – это всегда полное сканирование данных, никаких индексов нет. Это означает, что MapReduce плохо применим, когда ответ требуется очень быстро.
Для составления простых отчетов BI (Business Intelligence), существует множество продуктов с открытым кодом, позволяющих вычислять суммы, средние, пропорции и т.п. с помощью map-reduce. Таким образом, получить точные подсчеты и другие простые статистики для составления отчетов очень легко.
На первый взгляд может показаться, что построение прогностических моделей в распределенной файловой системой сложнее, однако это совсем не так. Рассмотрим предварительные этапы анализа данных:
Подготовка данных. Важно, что, несмотря на то, что наборы данных могут быть очень большими, информация, содержащаяся в них, имеет значительно меньшую размерность. Например, в то время как данные накапливаются ежесекундно или ежеминутно, многие параметры (температура газов и печей, потоки, положение заслонок и т.д.) остаются стабильными на больших интервалах времени. Иначе говоря, данные, записывающиеся каждую секунду, являются в основном повторениями одной и той же информации. Таким образом, необходимо проводить “умное” агрегирование данных, получая для моделирования и оптимизации данные, которые содержат только необходимую информацию о динамических изменениях, влияющих на эффективность работы электростанции и количество выбросов.
Классификация текстов и предварительная обработка данных. Большие наборы данных могут содержать гораздо меньше полезной информации. Для увеличения ценности их можно классифицировать и агрегировать. Существует множество инструментов для проведения такого агрегирования данных в распределенной файловой системе, что позволяет легко осуществлять данный аналитический процесс.