Файл: Конспект лекций по дисциплине прикладные компьютерные технологии Направление подготовки 09. 03. 01 Информатика и вычислительная техника.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 20.03.2024
Просмотров: 75
Скачиваний: 0
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.

Построение моделей. Часто задача состоит в том, чтобы быстро построить точные модели для данных, хранящихся в распределенной файловой системе. Существуют реализации map-reduce для различных алгоритмов data mining, прогностической аналитики, подходящих для масштабной параллельной обработки данных в распределенной файловой системе. Однако, именно из-за того, что вы обработали очень большое количество данных, уверенности, что итоговая модель является действительно более точной – нет. На самом деле, удобнее строить модели для небольших сегментов данных в распределенной файловой системе. Статистическая и математическая точность заключается в том, что модель линейной регрессии, включающая, например, 10 предикторов, основанных на правильно сделанной вероятностной выборке из 100 000 наблюдений, будет так же точна, как модель, построенная на 100 миллионах наблюдений. В вероятностной выборке каждый элемент совокупности имеет определенную, заранее заданную вероятность быть выбранным. Причем для каждого элемента совокупности вероятность попадания в выборку одинакова. В действительности, точность модели зависит от качества выборки (каждое наблюдение в популяции должно иметь известную вероятность выбора) и её размер связан со сложностью модели. Размер популяции не имеет значения. Именно по этой причине, например, выборка, состоящая всего из нескольких тысяч голосов, может позволить построить очень точные прогнозы реальных результатов голосования. Использование всего объема данных для сегментации и кластеризации позволит эффективно строить большое количество моделей для небольших кластеров. Например, можно ожидать, что модели, основанные на широкой сегментации (20-30 лет), будут менее точными, чем большое число моделей, построенных на более детальной сегментации (например, 20-21-летние студенты, проживающие в общежитии, и учащиеся на факультете бизнеса).
Таким образом, один из способов получения преимуществ Big Data заключается в том, чтобы использовать доступную информацию для построения большого количества моделей для большого числа сегментов и, затем, по соответствующей модели строить прогнозы. В предельном случае, каждый отдельный «человек» в большом хранилище данных клиентов может иметь свою собственную модель для прогнозирования будущих покупок.
Критика Big Data
-
Хранение Big Data не всегда приводит к получению выгоды. Хранение огромного количества данных, описывающих некоторые легко наблюдаемые события, не всегда приводит к выгодному понимаю реальности. Это в равной мере относится к анализу акций, каналов twitter, медицинских данных, данных CRM, или мониторингу комплекса оборудования для диагностического обслуживания. Например, достоверный список потенциальных покупателей товаров, наряду с демографической информацией, а также информацией о чистой стоимости товаров, могут быть гораздо более ценными для поставщиков, чем массивное хранилище данных о кликах на различных сайтах онлайн-магазинов. -
Скорость обновления данных и «актуальный» временной интервал. Может случиться, что необходимо построить модель на производстве, предсказывающую неполадки на одну секунду вперед на основе непрерывного потока данных для тысяч параметров. Однако если это требует, чтобы инженер два часа детализировал результат и «что-то делал», то такая система может быть бессмысленной. Для поставщиков домашней фурнитуры, было бы важнее получить “сигнал” за месяц или два перед тем, как осуществится покупка жилья, вместо информации в режиме реального времени уже после покупки, когда потенциальный клиент просматривает различные Интернет-сайты в поисках фурнитуры. В целом, следует начинать с четкого определения необходимых параметров и стратегии того, как добиться успехов в той или иной области. После этого уже будет очевиден необходимый временной интервал обновления данных, а, следовательно, и требования к оптимальному плану сбора данных, их хранению и анализу.
Применение Big Data
Активнее всего большие данные используют в финансовой и медицинской отраслях, высокотехнологичных и интернет-компаниях, а также в государственном секторе. Всех, кто имеет дело с большими данным, можно условно разделить на несколько групп:
-
Поставщики инфраструктуры — решают задачи хранения и предобработки данных. Например: IBM, Microsoft, Oracle, Sap и другие. -
Датамайнеры — разработчики алгоритмов, которые помогают заказчикам извлекать ценные сведения. Среди них: Yandex Data Factory, «Алгомост», Glowbyte Consulting, CleverData и др. -
Системные интеграторы — компании, которые внедряют системы анализа больших данных на стороне клиента. К примеру: «Форс», «Крок» и др. -
Потребители — компании, которые покупают программно-аппаратные комплексы и заказывают алгоритмы у консультантов. Это «Сбербанк», «Газпром», «МТС», «Мегафон» и другие компании из отраслей финансов, телекоммуникаций, ритейла. -
Разработчики готовых сервисов — предлагают готовые решения на основе доступа к большим данным. Они открывают возможности Big Data для широкого круга пользователей.

Основные поставщики больших данных в России — поисковые системы. Они имеют доступ к массивам данных, а кроме того, обладают достаточной технологической базой для создания новых сервисов:
-
Google. На рынке бизнес-аналитики с 2012 года, когда компания запустила Google BigQuery — облачный сервис для анализа Big Data в режиме реального времени. Через год его интегрировали в Google Analytics Premium — платную версию счетчика. Недавно Google представила Cloud Bigtable — масштабируемый, облачный сервис баз данных. -
«Яндекс». Большинство сервисов компании построено на анализе больших данных: поисковый алгоритм на основе нейросетей «Палех», машинный перевод, фильтрация спама, таргетинг в контекстной рекламе, предсказание пробок и погоды, распознавание речи и образов, управление беспилотными автомобилями.
Некоторое время в «Яндексе» существовало отдельное подразделение Yandex Data Factory, которое оказывало консультационные услуги крупным компаниям. Но впоследствии эта структура была внедрена в отдел поиска. -
Mail.Ru Group. Система веб-аналитики «Рейтинг Mail.Ru» — первый проект, который начал применять технологии обработки больших данных. Сейчас Big Data используется практически во всех сервисах компании — «Таргет.Mail.Ru», «Почта Mail.Ru», «Одноклассники», «Мой Мир», «Поиск Mail.Ru» и других. С помощью анализа больших данных Mail.Ru таргетирует рекламу, оптимизирует поиск, ускоряет работу техподдержки, фильтрует спам, изучает поведение пользователей и т. д. -
«Рамблер». Сначала медиахолдинг использовал большие данные только в поиске, а затем в компании появилось направление датамайнинга. «Рамблер» применяет технологии для персонализации контента, блокировки ботов и спама, обработки естественного языка.
Выгоды использования технологии в бизнесе:
-
Упрощается планирование. -
Увеличивается скорость запуска новых проектов. -
Повышаются шансы проекта на востребованность. -
Можно оценить степень удовлетворенности пользователей. -
Проще найти и привлечь целевую аудиторию. -
Ускоряется взаимодействие с клиентами и контрагентами. -
Оптимизируются интеграции в цепи поставок. -
Повышается качество клиентского сервиса, скорость взаимодействия. -
Повышается лояльность текущих клиентов.
Интерес к технологиям больших данных в России растет, но у Big Data есть как драйверы, так и ограничители.
| Драйверы | Ограничители |
| Высокий спрос на Big Data для повышения конкурентоспособности с помощью возможностей технологий | Необходимость обеспечивать безопасность и конфиденциальность данных |
| Развитие методов обработки медиафайлов на мировом уровне | Нехватка квалифицированных кадров |
| Реализация отраслевого плана по импортозамещению программного обеспечения | В большинстве российских компаний объем накопленных информационных ресурсов не достигает уровня Big Data |
| Тренд на использование услуг российских провайдеров и системных интеграторов | Новые технологии сложно внедрять в устоявшиеся информационные системы компаний |
| Создание технопарков, которые способствуют развитию информационных технологий | Высокая стоимость технологий |
| Государственная программа по внедрению грид-систем — виртуальных суперкомпьютеров, которые распространяются по кластерам и связываются сетью | Заморозка инвестиционных проектов в России и отток зарубежного капитала |
| Перенос на территорию России серверов, которые обрабатывают персональную информацию | Рост цен на импортную продукцию |
Общая информация о Hadoop
Hadoop – программный стек для работы с большими данными. Изначально Hadoop был, в первую очередь, инструментом для хранения данных и запуска MapReduce-задач, сейчас же Hadoop представляет собой большой стек технологий, так или иначе связанных с обработкой больших данных (не только при помощи MapReduce).
Основными (core) компонентами Hadoop являются:
-
Hadoop Distributed File System (HDFS) – распределённая файловая система, позволяющая хранить информацию практически неограниченного объёма. -
Hadoop YARN – фреймворк для управления ресурсами кластера и менеджмента задач, в том числе включает фреймворк MapReduce. -
Hadoop common
Также существует большое количество проектов непосредственно связанных с Hadoop, но не входящих в Hadoop core:
-
Hive – инструмент для SQL-like запросов над большими данными (превращает SQL-запросы в серию MapReduce–задач); -
Pig – язык программирования для анализа данных на высоком уровне. Одна строчка кода на этом языке может превратиться в последовательность MapReduce-задач; -
Hbase – колоночная база данных, реализующая парадигму BigTable; -
Cassandra – высокопроизводительная распределенная key-value база данных; -
ZooKeeper – сервис для распределённого хранения конфигурации и синхронизации изменений этой конфигурации; -
Mahout – библиотека и движок машинного обучения на больших данных.
Отдельно хотелось бы отметить проект Apache Spark, который представляет собой движок для распределённой обработки данных. Apache Spark обычно использует компоненты Hadoop, такие как HDFS и YARN для своей работы, при этом сам в последнее время стал популярнее, чем Hadoop.
Инструмент Hbase
Hbase — мощное средство для хранения и обновления данных в экосистеме hadoop. Hbase зародилась из концепции, которая была разработана в компании Google. Обычные файлы довольно неплохо подходят для пакетной обработки данных, с использованием парадигмы MapReduce. С другой стороны информацию хранящуюся в файлах довольно неудобно обновлять и файлы также лишены возможности произвольного доступа. Для быстрой и удобной работы с произвольным доступом есть класс nosql-систем типа key-value storage, таких как Aerospike, Redis, Couchbase, Memcached. Однако обычно в этих системах очень неудобна пакетная обработка данных. Hbase представляет из себя попытку объединения удобства пакетной обработки и удобства обновления и произвольного доступа.
Hbase — это распределенная, колоночно-ориентированная, мультиверсионная база типа «ключ-значение». Данные организованы в таблицы, проиндексированные первичным ключом, который в Hbase называется RowKey. Для каждого RowKey ключа может храниться неограниченны набор атрибутов (или колонок). Колонки организованны в группы колонок, называемые Column Family. Как правило, в одну Column Family объединяют колонки, для которых одинаковы паттерн использования и хранения. Для каждого аттрибута может храниться несколько различных версий. Разные версии имеют разный timestamp. Записи физически хранятся в отсортированном по RowKey порядке. При этом данные соответствующие разным Column Family хранятся отдельно, что позволяет при необходимости читать данные только из нужного семейства колонок.
При удалении определённого атрибута физически он сразу не удаляется, а лишь маркируется специальным флажком tombstone. Физическое удаление данных произойдет позже, при выполнении операции Major Compaction. Атрибуты, принадлежащие одной группе колонок и соответствующие одному ключу физически хранятся как отсортированный список. Любой атрибут может отсутствовать или присутствовать для каждого ключа, при этом если атрибут отсутствует — это не вызывает накладных расходов на хранение пустых значений.
С
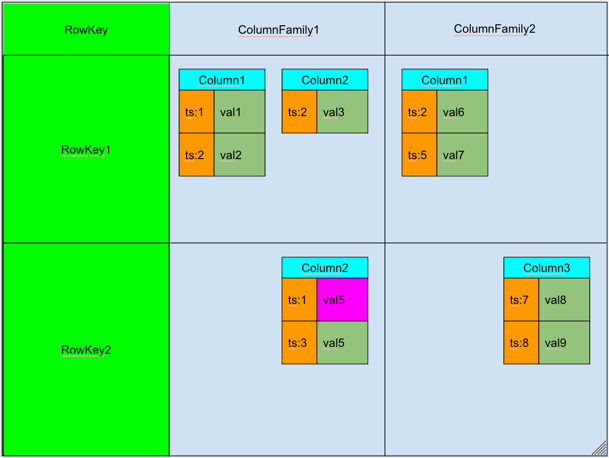 писок и названия групп колонок фиксирован и имеет четкую схему. На уровне группы колонок задаются такие параметры как time to live (TTL) и максимальное количество хранимых версий. Если разница между timestamp для определенно версии и текущим временем больше TTL — запись помечается к удалению. Если количество версий для определённого атрибута превысило максимальное количество версий — запись также помечается к удалению.
писок и названия групп колонок фиксирован и имеет четкую схему. На уровне группы колонок задаются такие параметры как time to live (TTL) и максимальное количество хранимых версий. Если разница между timestamp для определенно версии и текущим временем больше TTL — запись помечается к удалению. Если количество версий для определённого атрибута превысило максимальное количество версий — запись также помечается к удалению.