ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 03.05.2024
Просмотров: 9
Скачиваний: 0
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.

Доклад по дисциплине
«Информационно- коммуникационные технологии»»
Тема: «Хранилища данных»
Содержание
Введение…………………………………………………………………………...3
1. Технология информационных хранилищ…………………………………….4
2. Системы хранения……………………………………………………………...8
3. Расширение хранилища данных………………………………………………9
4. Архивирование информации из хранилища данных……………………….11
Заключение……………………………………………………………………….14
Список литературы………………………………………………………………15
Введение
Решение определённых задач, постройка информационных и компьютерных моделей, хранение информации связано с базами данных. База данных - это хранилище информации, объекты которой называют «элементами». Эти элементы объединены определёнными характеристиками, для большего удобства поиска информации. По сути, база данных - это обычное хранилище какой-либо информации. Базы данных разделяют на реляционные, иерархические, объектные, сетевые, функциональные. Иерархическая база данных - это база, в которой каждый элемент имеет связь только с одним элементом высшей категории. То есть, чтобы найти определённую информацию, пользователь должен будет просмотреть весь каталог данных, который ведёт к этой информации. Этот вид баз данных является самым простым. За иерархической базой данных следует сетевая. Сетевая база данных является расширенной иерархической базой данных. Отличие в том, что в эту «модификацию» добавили систему групп. Элементы здесь характеризуются не по одному, как в иерархической структуре, а по различным группам. Это значительно упростило поиск информации.
Реляционную базу данных нередко называют прорывом в создании баз данных. Информация в ней распределена совсем не так, как в прежних двух видах, а в простых таблицах. В «шапке» таблицы находятся характеристики, а на пересечении характеристик находятся элементы, которые ищет пользователь. Такая инновация действительно перевернула мир баз данных, ведь теперь вся нужная информация была прямо перед глазами, а не в десятках групп. Объектно-ориентированные базы данных. Такие базы данных разрабатывают сейчас и по сей день это — самый инновационный вид баз данных. Элементы в таких базах данных имеют совокупность характеристик, которые называют «состояние объекта» и индивидуальный программный код- «поведение объекта». При изменении состояния объекта, его поведение не меняется [1].
1. Технология информационных хранилищ
Одной из форм интеграции ИТ являются информационные хранилища. Технология информационных хранилищ – это разновидность интегрированной технологии, предназначенной для реализации процедур, методов и средств хранения и применения комплекса БД в решении задач пользователя. Обширные массивы данных можно хранить на одном или нескольких серверах. Эти массивы обычно называют информационными хранилищами. Информационное хранилище – это совокупность БД, содержащая единообразно представленную и согласованную информацию, максимально соответствующую концепции БД. Применяется также термин хранилище данных (от англ. Data Warehouse, DW) – это большая предметно-ориентированная информационная корпоративная БД, специально предназначенная для анализа бизнес-процессов с целью поддержки принятия решений (рис.1). В информационном хранилище в качестве первичного источника данных должны выступать БД систем управления фирмой, офисные документы, ресурсы Интернета, так как необходимо использовать все сведения, которые могут пригодиться для принятия решения [2]. Причем речь идет не только о внутренней для фирмы информации, но и о внешних данных, например макроэкономические показатели, конкурентная среда, демографические данные и т.п.
Следующим элементом схемы является семантический слой. Вне зависимости от того, каким образом будет анализироваться информация, необходимо, чтобы она была понятна ЛПР. Так как в большинстве случаев анализируемые данные располагаются в различных БД, а ЛПР не должно вникать в нюансы работы с СУБД, то требуется создать некий механизм, трансформирующий термины предметной области в вызовы механизмов доступа к БД. Эту задачу и выполняет семантический слой. Желательно, чтобы он был один для всех приложений анализа.
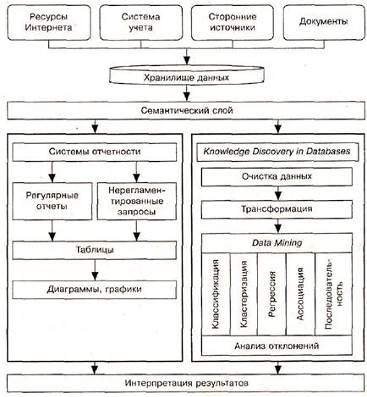
Рис. 1 Структура хранилища данных
Хранилище может быть сформировано как сеть хранения данных, которые формируются из множества разных внешних и внутренних источников. В любом случае это базы и банки данных, функционирующие под управлением распределенных СУБД. Нужным компонентом хранилищ является модуль для извлечения и «очистки» информации из разных источников. В некоторых случаях для «подпитки» хранилищ применяются так называемые OLTP-системы. OLTP (от англ. Online Transaction Processing – онлайновая обработка транзакций) представляет такой способ организации БД, при котором система работает с небольшими по размерам транзакциями. Но они идут большим потоком, и клиенту требуется от системы быстрое время ответа. В OLTP-технологии чаще всего используется фиксированный набор надежных и безопасных методов ввода, модификации, удаления данных и выпуска оперативной отчетности. Показателем эффективности является количество транзакций, выполняемых за секунду.
Хотя для построения систем отчетности можно применять различные подходы, самый распространенный на сегодня – это технология OLAP (от англ. OnlineAnalytical Processing – аналитическая обработка в реальном времени) – технология обработки информации, включающая составление и динамическую публикацию отчетов и других документов.
Наиболее эффективна организация хранилищ при условии реализации симбиоза OLTP и О LAP, когда используются достоинства первой и второй технологий. Первая базируется на реляционных БД, имеющих данные в отдельных хорошо нормализованных таблицах для быстрых транзакций, но сложные многотабличные запросы в ней выполняются медленно. Вторая относится к пространственным моделям БД и имеет способность быстрого поиска по сложным многотабличным запросам. OLAP делает быстрый снимок реляционной БД OLTP-системы и превращает ее в пространственную модель для запросов. Для сохранности электронных информационных ресурсов применяют специальные сети храпения данных, получившие название Storage Area Network (SAN), а в корпоративных сетях – специализированные Network Attached Storage (NAS-серверы), которые осуществляют совместимость, интеграцию и администрирование серверов общего назначения, а также хранение огромных массивов данных. В качестве информационных хранилищ в них используют RAID-массивы, CD-и DVD-библиотеки. Возможность современных СУБД организовывать накопление и оперативную обработку больших объемов данных способствовала развитию аналитических систем прогнозирования, идентификации объектов и состояний, оценки и выбора альтернативных решений, встроенных в разные системы, например, системы поддержки принятия решений. Подход построения хранилища данных для интеграции неоднородных источников данных принципиально отличается от подхода динамической интеграции разнородных БД. Строится новое крупное хранилище, управление данными в котором происходит по иным правилам, чем в исходных оперативных БД.
В основе концепции хранилища данных лежат две основные идеи.
1. Интеграция разъединенных детализированных данных, детализированных в том смысле, что они описывают некоторые конкретные факты, свойства, события в едином хранилище.
2. Разделение наборов данных и приложений, используемых для оперативной обработки и применяемых для решения задач анализа.
В общем случае информационные хранилища характеризуются как специальным образом администрируемая БД, обладающая следующими свойствами: предметной ориентацией; интегрированностью данных; инвариантностью во времени; неразрушаемостью – стабильностью информации; минимизацией избыточности информации.
Основными компонентами информационного хранилища являются: ПО промежуточного слоя – обеспечивает сетевой доступ и доступ к БД; транзакционные БД и внешние источники информации; уровень доступа к данным; загрузка и предварительная обработка; информационное хранилище; метаданные; уровень информационного доступа; уровень управления (администрирования).
Обычно при реализации хранилища могут возникать следующие проблемы:
1. Неоднородность программной среды.
2. Распределенный характер организации.
3. Повышенные требования к безопасности данных в соответствии с классификацией так называемой Оранжевой книги Министерства обороны США.
4. Необходимость наличия многоуровневых справочников метаданных.
5. Потребность в эффективном хранении и обработке очень больших объемов информации.
Реализация хранилищ данных имеет несколько вариантов.
1. Виртуальное хранилище данных.
2. Витрина данных (Data Mart).
3. Глобальное хранилище данных с многоуровневой архитектурой.
На первом уровне реализуется корпоративное хранилище данных на основе одной из развитых современных реляционных СУБД. Это хранилище интегрированных, в основном детализированных данных.
На втором уровне поддерживаются витрины данных на основе многомерной системы управления БД. Примером такой системы является Oracle ExpressServer. Такие СУБД почти идеально подходят для целей разработки OLAP-систем, но пока не позволяют хранить сверхбольшие объемы данных. Предельный размер многомерной БД составляет 10-40 Гб.
На третьем уровне находятся клиентские рабочие места конечных пользователей, на которых устанавливаются средства оперативного анализа данных [2].
2. Системы хранения
На хранение корпоративных данных компании тратят немалые средства, и желание оптимизировать свои расходы является вполне естественным. Различные данные имеют для компании разную ценность, и затраты на их хранение должны быть адекватными. При этом определение реальной ценности и востребованности данных является ключевым вопросом. Неверные оценки в лучшем случае сведут на нет все попытки сэкономить, а в худшем — приведут к значительным рискам.
В целом требования к хранению данных можно разделить на несколько категорий: уровень доступности (Availability); время восстановления доступа к информации после сбоя (Recovery Time Objective); «возраст» точки восстановления данных (Recovery Point Objective); период хранения (Retention Period) — чуть реже используемое требование по жизненному циклу данных.
В зависимости от того, к какому классу критичности относятся данные, для каждого из них разрабатываются свои схема и регламенты хранения, резервного копирования и восстановления. В результате часть данных может оказаться на флэш-накопителях системы хранения старшего уровня с возможностью непрерывного восстановления (Continuous Data Protection), а другая — в пассивном архиве на удаленном складе.
Однако нужно учесть, что с течением времени данные имеют особенность устаревать и переходить в другой класс критичности. Следовательно, к ним могут измениться требования по хранению, резервированию и восстановлению. Большинство задач по управлению их жизненным циклом успешно автоматизируются, причем как встроенными средствами систем хранения, так и специализированными программными средствами. Такие решения могут автоматически архивировать корпоративные данные и перемещать устаревшие, то есть редко используемые, экземпляры файлов, почтовых сообщений или элементов баз данных на более дешевые носители с сохранением доступа к ним.
3. Расширение хранилища данных
Традиционная ИТ-инфраструктура не позволяет вводить, администрировать и обрабатывать большие данные в разумные сроки. Она просто неспособна вместить данные в объеме от нескольких десятков терабайт до многих петабайт. Традиционно хранилища данных анализируют структурированные транзакционные данные, содержащиеся в реляционных базах данных. В них применяются ключевые показатели эффективности и основанные на моделях архитектуры.
До недавнего времени состав системы управления данными, который иллюстрируется на рисунке 2, был достаточно простым.
-
Системы оперативной обработки транзакций (OLTP) поддерживающие бизнес-процессы предприятия. -
Оперативные хранилища данных (ODS), накапливающие бизнес-транзакции для поддержки оперативной отчетности. -
Корпоративные хранилища данных (EDW), которые накапливают и преобразуют бизнес-транзакции для поддержки как оперативных, так и стратегических решений.
Обычно предприятия анализируют структурные источники данных, создаваемые в рамках организации. Каждый уровень выполняет определенную функцию.
-
Уровень сбора данных: состоит из компонентов для получения данных от систем-источников, таких как отдел кадров, финансовый отдел и бухгалтерия. -
Уровень интеграции данных: состоит из компонентов интеграции для передачи данных от источников на уровень хранилища данных в рамках архитектуры. -
Уровень хранилища данных: хранит данные с использованием реляционной модели для повышения производительности и интенсификации обработки запросов. -
Аналитический уровень: хранит данные в формате куба для упрощения анализа гипотетических вариантов пользователями. -
Уровень представления: приложения или порталы, предоставляющие доступ другому набору пользователей. Приложения и порталы потребляют данные посредством веб-страниц и портлетов, определенных в инструменте отчетности, или с помощью веб-сервисов.

