Файл: Help(topic), topic справка про topic help search("pattern"), pattern глобальный поиск pattern.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 06.05.2024
Просмотров: 14
Скачиваний: 0
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.

Помощь
help(topic), ?topic — справка про topic
help.search("pattern"), ??pattern — глобальный поиск pattern
help(package = ) — справка о заданном пакете
help.start() — запустить помощь в браузере
apropos(what) — имена объектов, которые соответствуют what
args(name) — аргументы команды name
example(topic) — примеры использования topic
Текущее окружение
ls() — список всех объектов
rm(x) — удалить объект
dir() — показать все файлы в текущей директории
getwd() — получить текущую директорию
setwd(dir) — поменять текущую директорию на dir
Общая работа с объектами
str(object) — внутренняя структура объекта object
summary(object) — общая информация об объекте object
dput(x) — получить представление объекта в R-синтаксисе
head(x) — посмотреть начальные строки объекта
tail(x) — посмотреть последние строки объекта
Ввод и вывод
library(package) — подключить пакет package
save(file, ...) — сохраняет указанные объекты в двочином XDR-формате, который не зависит от платформы
load() — загружает данные, сохранённые ранее с помощью команды save()
read.table — считывает таблицу данных и создаёт по ним data.frame
write.table — печатает объект, конвертируя его в data.frame
read.csv — считывает csv-файл
read.delim — считывание данных, разделённых знаками табуляции
save.image — сохраняет все объекты в файл
cat(..., file= , sep= ) — сохраняет аргументы, конкатенируя их через sep
sink(file) — выводит результаты выполнения других команд в файл в режиме реального времени до момента вызова этой же команды без аргументов
Создание объектов
from:to — генерирует последовательность чисел от from до to с шагом 1, например 1:3
с(...) — объединяет аргументы в вектор, например c(1, 2, 3)
seq(from, to, by = ) — генерирует последовательность числел от from до to с шагом by
seq(from, to, len = ) — генерирует последовательность числел от from до to длины len
rep(x, times) — повторяет x ровно times раз
list(...) — создаёт список объектов
data.frame(...) — создаёт фрейм данных
array(data, dims) — создаёт из data многомерные массив размерностей dim
matrix(data, nrow = , ncol = , byrow = ) — создаёт из data матрицу nrow на ncol, порядок заполнения определяется byrow
factor(x, levels = ) — создаёт из x фактор с уровнями levels
gl(n, k, length = n*k, labels = 1:n) — создаёт фактор из n уровней, каждый из которых повторяется k раз длины length с именами labels
rbind(...) — объединяет аргументы по строкам
cbind(...) — объединяет аргументы по столбцам
Индексирование
Векторы
x[n]
n-ый элемент
x[-n]
все элементы, кроме n-го
x[1:n]
первые n элементов
x[-(1:n)]
все элементы, кроме первых n
x[c(1,4,2)]
элементы с заданными индексами
x["name"]
элемент с заданным именем
x[x > 3]
все элементы, большие 3
x[x > 3 & x < 5]
все элементы между 3 и 5
x[x %in% c("a","and","the")]
все элементы из заданного множества
Списки
x[n]
список, состоящий из элемента n
x[[n]]
n-ый элемент списка
x[["name"]]
элемент списка с именем name
x$name
элемент списка с именем name
Матрицы
x[i, j]
элемент на пересечении i-ой строки и j-го столбца
x[i,]
i-ая строка
x[,j]
j-ый столбец
x[,c(1,3)]
заданное подмножество столбцов
x["name", ]
строка с именем name
Фреймы
x[["name"]]
столбец с именем name
x$name
столбец с именем name
Работа с переменными
as.array(x), as.data.frame(x), as.numeric(x), as.logical(x), as.complex(x), as.character(x) — преобразование переменной к заданному типу is.na(x), is.null(x), is.array(x), is.data.frame(x), is.numeric(x), is.complex(x), is.character(x) — проверка на то, что данный объект обладает указанным типом
length(x) — число элементов в x
dim(x) — размерности объекта x
dimnames(x) — имена размерностей объекта x
names(x) — имена объекта x
nrow(x) — число строк x
ncol(x) — число столбцов x
class(x) — класс объекта x
unclass(x) — удаляет атрибут класса у объекта x
attr(x,which) — атрибут which объекта x
attributes(obj) — список атрибутов объекта obj
Манипуляция данными
which.max(x) — индекс элемента с максимальным значением
which.min(x) — индекс элемента с минимальным значением
rev(x) — реверсирует порядок элементов
sort(x) — сортирует элементы объекта по возрастанию
cut(x,breaks) — делит вектор на равные интервалы
match(x, y) — ищет элементы x, которые есть в y
which(x == a) — возвращает порядковые элементы x, которые равны a
na.omit(x) — исключает отсутствующие значения объекта
na.fail(x) — бросает исключение, если объект содержит отсутствующие значения
unique(x) — исключает из объекта повторяющиеся элементы
table(x) — создаёт таблицу с количеством повторений каждого уникального элемента
subset(x, ...) — возвращает подмножество элемента, которое соответствует заданному условию
sample(x, size) — возвращает случайный набор размера size из элементов x
replace(x, list, values) — заменяет значения x c индексами из list значениями из values
append(x, values) — добавляет элементы values в вектор x
Математика
sin(x), cos(x), tan(x), asin(x), acos(x), atan(x), atan2(y, x), log(x), log(x, base), log10(x), exp(x) — элементарные математические функции
min(x), max(x) — минимальный и максимальный элементы объекта
range(x) — вектор из минимального и максимального элемента объекта
pmin(x, y), pmax(x, y) — возвращают вектор с минимальными (максимальными) для каждой пары x[i], y[i]
sum(x) — сумма элементов объекта
prod(x) — произведение элементов объекта
diff(x) — возвращает вектор из разниц между соседними элементами
mean(x) — среднее арифметическое элементов объекта
median(x) — медиана (средний элемент) объекта
weighted.mean(x, w) — средневзвешенное объекта x (w определяет веса)
round(x, n) — округляет x до n знаков после запятой
cumsum(x), cumprod(x), cummin(x), cummax(x) — кумулятивные суммы, произведения, минимумы и максимумы вектора x (i-ый элемент содержит статистику по элементам x[1:i])
union(x, y), intersect(x, y), setdiff(x,y), setequal(x,y), is.element(el,set) — операции над множествами: объединение, пересечение, разность, сравнение, принадлежность
Re(x), Im(x), Mod(x), Arg(x), Conj(x) — операции над комплексными числами: целая часть, мнимая часть, модуль, аргумент, сопряжённое число
fft(x), mvfft(x) — быстрое преобразование Фурье
choose(n, k) — количество сочетаний
rank(x) — ранжирует элементы объекта
Матрицы
%*% — матричное умножение
t(x) — транспонированная матрица
diag(x) — диагональ матрицы
solve(a, b) — решает систему уравнений a %*% x = b
solve(a) — обратная матрица
colSums, rowSums, colMeans, rowMeans — суммы и средние по столбцам и по строкам
Обработка данных
apply(X,INDEX,FUN=) — возвращает вектор, массив или список значений, полученных путем применения функции FUN к определенным элементам массива или матрицы x; подлежащие обработке элементы х указываются при помощи аргумента MARGIN;
lapply(X,FUN) — возвращает список той же длины, что и х; при этом значения в новом списке будут результатом применения функции FUN к элементам исходного объекта х
tapply(X,INDEX,FUN=) — применяет функцию FUN к каждой совокупности значений х, созданной в соответствии с уровнями определенного фактора; перечень факторов указывается при помощи аргумента INDEX
by(data,INDEX,FUN) — аналог tapply(), применяемый к таблицам данных
merge(a,b) — объединяет две таблицы данных (а и b) по общим столбцами или строкам
aggregate(x,by,FUN) — разбивает таблицу данных х на отдельные наборы данных, применяет к этим наборам определенную функцию FUN и возвращает результат в удобном для чтения формате
stack(x, ...) — преобразует данные, представленные в объекте х в виде отдельных столбцов, в таблицу данных
unstack(x, ...) — выполняет операцию, обратную действию функции stack()
reshape(x, ...) — преобразует таблицу данных из «широкого формата» (повторные измерения какой-либо величины записаны в отдельных столбцах таблицы) в таблицу "узкого формата" (повторные измерения идут одно под одним в пределах одного столбца)
Строки
print(x) — выводит на экран x
sprintf(fmt, ...) — форматирование текста в C-style (можно использовать %s, %.5f и т.п.)
format(x) — форматирует объект x так, чтобы он выглядел красиво при выводе на экран
paste(...) — конвертирует векторы в текстовые переменные и объединяет их в одно текстовое выражение
substr(x,start,stop) — получение подстроки
strsplit(x,split) — разбивает строку х на подстроки в соответствии с split
grep(pattern,x) (а также grepl, regexpr, gregexpr, regexec) — поиск по регулярному выражению
gsub(pattern,replacement,x) (а также sub) — замена по регулярному выражению
tolower(x) — привести строку к нижнему регистру
toupper(x) — привести строку к верхнему регистру
match(x,table), x %in% table — выполняет поиск элементов в векторе table, которые совпадают со значениями из вектора х
pmatch(x,table) — выполняет поиск элементов в векторе table, которые частично совпадают с элементами вектора х
nchar(x) — возвращает количество знаков в строке х
Дата и время
as.Date(s) — конвертирует вектор s в объект класса Date
as.POSIXct(s) — конвертирует вектор s в объект класса POSIXct
Рисование графиков
plot(x) — график x
plot(x, y) — график зависимости y от x
hist(x) — гистограмма
barplot(x) — столбчатая диаграмма
dotchart(x) — диаграмма Кливленда
pie(x) — круговая диаграмма
boxplot(x) — график типа "коробочки с усами"
sunflowerplot(x, y) — то же, что и plot(), однако точки с одинаковыми координатами изображаются в виде "ромашек", количество лепестков у которых пропорционально количеству таких точек
coplot(x˜y | z) — график зависимости y от x для каждого интервала значений z
interaction.plot(f1, f2, y) — если f1 и f2 — факторы, эта фукнция создаст график со средними значениями y в соответствии со значениями f1 (по оси х) и f2 (по оси у, разные кривые)
matplot(x, y) — график зависимости столбцов y от столбцов x
fourfoldplot(x) — изображает (в виде частей окружности) связь между двумя бинарными переменными в разных совокупностях
assocplot(x) — график Кохена-Френдли
mosaicplot(x) — мозаичный график остатков лог-линейной регрессии
pairs(x) — если х - матрица или таблица данных, эта функция изобразит диаграммы рассеяния для всех возможных пар переменных из х
plot.ts(x), ts.plot(x) — изображает временной ряд
qqnorm(x) — квантили
qqplot(x, y) — график зависимости квантилей y от квантилей х
contour(x, y, z) — выполняет интерполяцию данных и создает контурный график
filled.contour(x, y, z) — то же, что contour(), но заполняет области между контурами определёнными цветами
image(x, y, z) — изображает исходные данные в виде квадратов, цвет которых определяется значениями х и у
persp(x, y, z) — то же, что и image(), но в виде трехмерного графика
stars(x) — если x — матрица или таблица данных, изображает график в виде "звезд" так, что каждая строка представлена "звездой", а столбцы задают длину сегментов этих "звезд"
symbols(x, y, ...) — изображает различные символы в соответствии с координатами
termplot(mod.obj) — зображает частные эффекты переменных из регрессионной модели
Рисование графиков на низком уровне
points(x, y) — рисование точек
lines(x, y) — рисование линии
text(x, y, labels, ...) — добавление текстовой надписи
mtext(text, side=3, line=0, ...) — добавление текстовой надписи
segments(x0, y0, x1, y1) — рисование отрезка
arrows(x0, y0, x1, y1, angle= 30, code=2) — рисование стрелочки
abline(a,b) — рисование наклонной прямой
abline(h=y) — рисование вертикальной прямой
abline(v=x) — рисование горизонтальной прямой
abline(lm.obj) — рисование регрессионной прямой
rect(x1, y1, x2, y2) — рисование прямоугольника
polygon(x, y) — рисование многоугольника
legend(x, y, legend) — добавление легенды
title() — добавление заголовка
axis(side, vect) — добавление осей
rug(x) — рисование засечек на оси X
locator(n, type = "n", ...) — возвращает координаты на графике, в которые кликнул пользователь
Lattice-графика
xyplot(y˜x) — график зависимости у от х
barchart(y˜x) — столбчатая диаграмма
dotplot(y˜x) — диаграмма Кливленда
densityplot(˜x) — график плотности распределения значений х
histogram(˜x) — гистограмма значений х
bwplot(y˜x) — график типа "коробочки с усами"
qqmath(˜x) — аналог функции qqnorm()
stripplot(y˜x) — аналог функции stripplot(x)
qq(y˜x) — изображает квантили распределений х и у для визуального сравнения этих распределений; переменная х должна быть числовой, переменная у - числовой, текстовой, или фактором с двумя уровнями
splom(˜x) — матрица диаграмм рассеяния (аналог функции pairs())
levelplot(z˜xy|g1g2) — цветной график значений z, координаты которых заданы переменными х и у (очевидно, что x, y и z должны иметь одинаковую длину); g1, g2... (если присутствуют) — факторы или числовые переменные, чьи значения автоматически разбиваются на равномерные отрезки
wireframe(z˜xy|g1g2) — функция для построения трехмерных диаграмм рассеяния и плоскостей; z, x и у - числовые векторы; g1, g2... (если присутствуют) - факторы или числовые переменные, чьи значения автоматически разбиваются на равномерные отрезки
cloud(z˜xy|g1g2) — трёхмерная диаграмма рассеяния
Оптимизация и подбор параметров
optim(par, fn, method = ) — оптимизация общего назначения
nlm(f,p) — минимизация функции f алгоритмом Ньютона
lm(formula) — подгонка линейной модели
glm(formula,family=) — подгонка обобщённой линейной модели
nls(formula) — нелинейный метод наименьших квадратов
approx(x,y=) — линейная интерполяция
spline(x,y=) — интерполяция кубическими сплайнами
loess(formula) — подгонка полиномиальной поверхности
predict(fit,...) — построение прогнозов
coef(fit) — расчётные коэффициенты
Статистика
sd(x) — стандартное отклонение
var(x) — дисперсия
cor(x) — корреляционная матрица
var(x, y) — ковариация между x и y
cor(x, y) — линейная корреляция между x и y
aov(formula) — дисперсионный анализ
anova(fit,...) — дисперсионный анализ для подогнанных моделей fit
density(x) — ядерные плотности вероятностей
binom.test() — точный тест простой гипотезы о вероятности успеха в испытаниях Бернулли
pairwise.t.test() — попарные сравнения нескольки независимых или зависимых выборок
prop.test() — проверка гипотезы о том, что частоты какого-либо признака равны во всех анализируемых группах
t.test() — тест Стьюдента
Распределения
rnorm(n, mean=0, sd=1) — нормальное распределение
rexp(n, rate=1) — экспоненциальное распределение
rgamma(n, shape, scale=1) — гамма-распределение
rpois(n, lambda) — распределение Пуассона
rweibull(n, shape, scale=1) — распределение Вейбулла
rcauchy(n, location=0, scale=1) — распределение Коши
rbeta(n, shape1, shape2) — бета-распределение
rt(n, df) — распределение Стьюдента
rf(n, df1, df2) — распределение Фишера
rchisq(n, df) — распределение Пирсона
rbinom(n, size, prob) — биномиальное распределение
rgeom(n, prob) — геометрическое распределение
rhyper(nn, m, n, k) — гипергеометрическое распределение
rlogis(n, location=0, scale=1) — логистическое распределение
rlnorm(n, meanlog=0, sdlog=1) — логнормальное распределение
rnbinom(n, size, prob) — отрицательное биномиальное распределение
runif(n, min=0, max=1) — равномерное распределение
Программирование
Работа с функциями:
function(arglist) { expr } — создание пользовательской функции
return(value) — возвращение значения
do.call(funname, args) — вызывает функцию по имени
Условные операторы:
if(cond) expr
if(cond) cons.expr else alt.expr
ifelse(test, yes, no)
Циклы:
for(var in seq) expr
while(cond) expr
repeat expr
break — остановка цикла
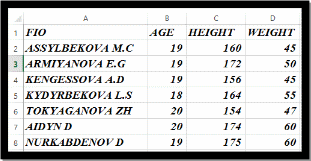
№ 1 Лабораторная работа
> FIO < - c("Assylbekova.M.C","Armiyanova.E.G ","Kengessova.A.D","Kydyrbekova.L.S","Aidyn.D","Toktaganova.Zh","Nurkabdenov.D")
> FIO
[1] "Assylbekova.M.C" "Armiyanova.E.G " "Kengessova.A.D" "Kydyrbekova.L.S"
[5] "Aidyn.D" "Toktaganova.Zh" "Nurkabdenov.D"
> AGE <- sample(2,7, replace = T)+17
> AGE
[1] 18 18 18 19 18 19 19
> AGE <- c (19,18,18,18,20,20,18)
> AGE
[1] 19 18 18 18 20 20 18
> HEIGHT <- c (160,175,152,162,174,150,175)
> HEIGHT
[1] 160 175 152 162 174 150 175
> df <- cbind (FIO, AGE, HEIGHT)
> df
FIO AGE HEIGHT
[1,] "Assylbekova.M.C" "19" "160"
[2,] "Armiyanova.E.G " "18" "175"
[3,] "Kengessova.A.D" "18" "152"
[4,] "Kydyrbekova.L.S" "18" "162"
[5,] "Aidyn.D" "20" "174"
[6,] "Toktaganova.Zh" "20" "150"
[7,] "Nurkabdenov.D" "18" "175"
> dd <- data.frame (FIO, AGE , HEIGHT)
> dd
FIO AGE HEIGHT
1 Assylbekova.M.C 19 160
2 Armiyanova.E.G 18 175
3 Kengessova.A.D 18 152
4 Kydyrbekova.L.S 18 162
5 Aidyn.D 20 174
6 Toktaganova.Zh 20 150
7 Nurkabdenov.D 18 175
> save.image("C:\\Users\\Molya\\Documents\\spisok gruppy")
> Weight <- c (45,65,50,55,60,45,60)
> Weight
[1] 45 65 50 55 60 45 60
> dd <- cbind (Weight)
> dd
Weight
[1,] 45
[2,] 65
[3,] 50
[4,] 55
[5,] 60
[6,] 45
[7,] 60
> dd <- data.frame (FIO, AGE , HEIGHT)
> dd
FIO AGE HEIGHT
1 Assylbekova.M.C 19 160
2 Armiyanova.E.G 18 175
3 Kengessova.A.D 18 152
4 Kydyrbekova.L.S 18 162
5 Aidyn.D 20 174
6 Toktaganova.Zh 20 150
7 Nurkabdenov.D 18 175
> dd <- cbind (dd, Weight)
> dd
FIO AGE HEIGHT Weight
1 Assylbekova.M.C 19 160 45
2 Armiyanova.E.G 18 175 65
3 Kengessova.A.D 18 152 50
4 Kydyrbekova.L.S 18 162 55
5 Aidyn.D 20 174 60
6 Toktaganova.Zh 20 150 45
7 Nurkabdenov.D 18 175 60
> mean (dd$AGE )
[1] 18.71429
> mean (dd$HEIGHT)
[1] 164
> mean (dd$Weight)
[1] 54.28571
> max(dd$AGE )
[1] 20
> min (dd$AGE)
[1] 18
> var (dd$Weight)
[1] 61.90476
>nrow(FIO)
>ncol(dd)
> save.image("C:\\Users\\Molya\\Documents\\sps")
№ 2 Лабораторная работа
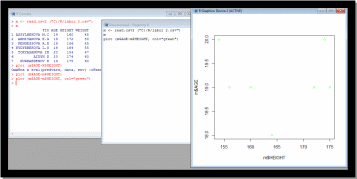
Создала таблицу в эксель потом сохранила с расширением csv (MS DOS).
Открыла эту таблицу на языке R
m <-read.csv2 (“C:/R/labor 2”)

Управляющие параметры функции PLOT()
Функция plot() имеет большое количество управляющих параметров, которые позволяют осуществлять очень тонкую настройку внешнего вида графика.
Plot (m$AGE
m$HEIGHT) (Строем график)

Plot (m$AGE
m$HEIGHT, col= “green”) потом задала красный цвет
Параметр type
Параметр type позволяет изменять внешний вид точек на графике. Он принимает одно из следующих текстовых значений:
"p" - точки (points; используется по умолчанию)
"l" - линии (lines)
"b" - изображаются и точки, и линии (both points and lines)
"o" - точки изображаются поверх линий (points over lines)
"h" - гистограмма (histogram)
"s" - ступенчатая кривая (steps)
"n" - данные не отображаются (no points)
plot (m$AGE
m$HEIGHT, col="green", type="o") изменила тип на о
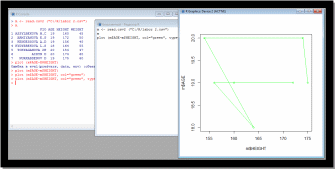
Параметры xlim и ylim
Эти два параметра контролирут размах значений на каждой из осей графика. По умолчанию они оба принимают значение NULL - в этом случае размах выбирается программой автоматически. Для отмены автоматических настроек соответствующему параметру необходимо присвоить значение в виде числового вектора, содержащего минимальное и максимальное значения, которые должны отображаться на оси.
plot (m$AGE
m$HEIGHT, col="green", type="o",xlim=c(18,175)) // x=18,y=175

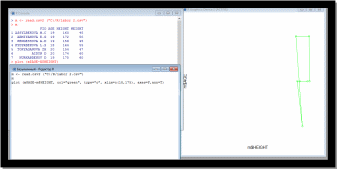
Параметры axes и ann
Эти два параметра контролируют отображение осей и их названий соответственно. Каждый из них может принимать два значения - TRUE или FALSE
plot (m$AGE
m$HEIGHT, col="green", type="o",axes=F,ann=T)
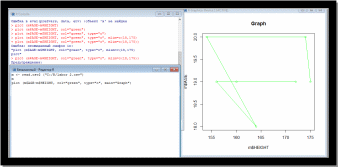
Параметр main
Аргумент main служит для создания названия графика. По умолчанию название размещается в верхней части рисунка:
plot (m$AGE
m$HEIGHT, col="green", type="o",main= “Graph”)
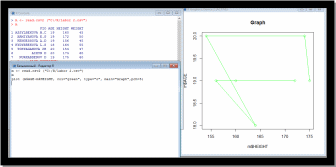
Параметр PCH
PCH-числовой аргумент, который имеет от 0 до 25 имеет разные фигуры.
Например:1-круглый,2-триугольник plot (m$AGE
m$HEIGHT, col="green", type="o", pch=5)//я выбрала 5-ромбик
Параметр CEX
Управляет размером шрифта и символов; следующие параметры имеют аналогичное
действие в отношении: чисел на координатных осях - cex.axis,меток осей - cex.lab, основного заголовка графика - cex.main, и подзаголовка - cex.sub
я увеличила размер ромбиков до 4 раза больше
plot (m$AGE
m$HEIGHT, col="green", type="o",pch=5,cex=4)
Изменить цвет маркера:
m<-4
plot(1:m,pch=CIRCLE<-16,cex=1:9,col=1:7)
Базовые графические возможности R: гистограммы
Гистограмма явлется важным инструментом статистики, позволяющим наглядно представить распределение значений анализируемой переменной. В системе R для построения гистограмм служит функция hist().
Hist(m$AGE)

Прежде всего, важно обратить внимание на размер шага, используемого для разбиения данных на классы при построении гистограммы. В приведенном выше примере программа автоматически разбила значения переменной Xна классы с шагом 5. Однако такое грубое разбиение может замаскировать истинные свойства анализируемой совокупности. Для более детального изучения этих свойств следует выбрать более дробное деление данных на классы (т.е. использовать меньший шаг). Сделать это позволяет аргумент breaks (разломы) функции hist():
hist(m$AGE, breaks = 20)

По умолчанию функция hist() отображает по оси ординат частоты встречаемости для каждого класса значений X. Такое поведение функции можно изменить, придав аргументу freq (от frequency - частота) значение FALSE. В этом случае ось ординат будет отражать плотность вероятности каждого класса так, что суммарна площадь под гистограммой составит 1:
hist(m$AGE, breaks = 20,freq=F)

Выбран светло-голубой цвет столбцов ("lightblue").
hist(m$AGE, breaks = 20,freq=F, col="lightblue")  Гистограммы (или в добавок к ней) в таких случаях стоит воспользоваться кривой плотности вероятности. Оценка плотности вероятности выполняется при помощи функции density(), которую можно применить в качестве аргумента функции plot() для графического изображения результата:
Гистограммы (или в добавок к ней) в таких случаях стоит воспользоваться кривой плотности вероятности. Оценка плотности вероятности выполняется при помощи функции density(), которую можно применить в качестве аргумента функции plot() для графического изображения результата:
plot(density(m$AGE))

Гладкость получаемой кривой контролируется при помощи аргумента bw (от bandwidth - полоса пропускания)
plot(density(m$AGE,bw=0.8))

Для полноты картины гистограмму можно совместить с кривой плотности вероятности. При этом сначала необходимо построить саму гистограмму, а затем добавить к ней кривую плотности при помощи функции lines()
hist((m$AGE), breaks = 10, freq = FALSE, col = "lightblue",xlab = "peremennaya x",ylab = "Plotnost veroyatnosti", main = "Histogaramm with Density")
lines(density(m$AGE), col = "red", lwd = 2)

№3 Лабораторная работа
barplot(x) — столбчатая диаграмма
dotchart(x) — диаграмма Кливленда
pie(x) — круговая диаграмма
boxplot(x) — график типа "коробочки с усами"
sunflowerplot(x, y) — то же, что и plot(), однако точки с одинаковыми координатами изображаются в виде "ромашек", количество лепестков у которых пропорционально количеству таких точек
coplot(x˜y | z) — график зависимости y от x для каждого интервала значений z
interaction.plot(f1, f2, y) — если f1 и f2 — факторы, эта фукнция создаст график со средними значениями y в соответствии со значениями f1 (по оси х) и f2 (по оси у, разные кривые)
matplot(x, y) — график зависимости столбцов y от столбцов x
fourfoldplot(x) — изображает (в виде частей окружности) связь между двумя бинарными переменными в разных совокупностях
assocplot(x) — график Кохена-Френдли
mosaicplot(x) — мозаичный график остатков лог-линейной регрессии
pairs(x) — если х - матрица или таблица данных, эта функция изобразит диаграммы рассеяния для всех возможных пар переменных из х
plot.ts(x), ts.plot(x) — изображает временной ряд
qqnorm(x) — квантили
qqplot(x, y) — график зависимости квантилей y от квантилей х
contour(x, y, z) — выполняет интерполяцию данных и создает контурный график
filled.contour(x, y, z) — то же, что contour(), но заполняет области между контурами определёнными цветами
image(x, y, z) — изображает исходные данные в виде квадратов, цвет которых определяется значениями х и у
persp(x, y, z) — то же, что и image(), но в виде трехмерного графика
stars(x) — если x — матрица или таблица данных, изображает график в виде "звезд" так, что каждая строка представлена "звездой", а столбцы задают длину сегментов этих "звезд"
symbols(x, y, ...) — изображает различные символы в соответствии с координатами
termplot(mod.obj) — зображает частные эффекты переменных из регрессионной модели
1.Столбчатая диаграмма barplot()
m <- read.csv2 ("C:/R/lab.csv")
m
counts <-table(m$AGE,m$HEIGHT)
barplot(table(cut(m$HEIGHT, b=3)))
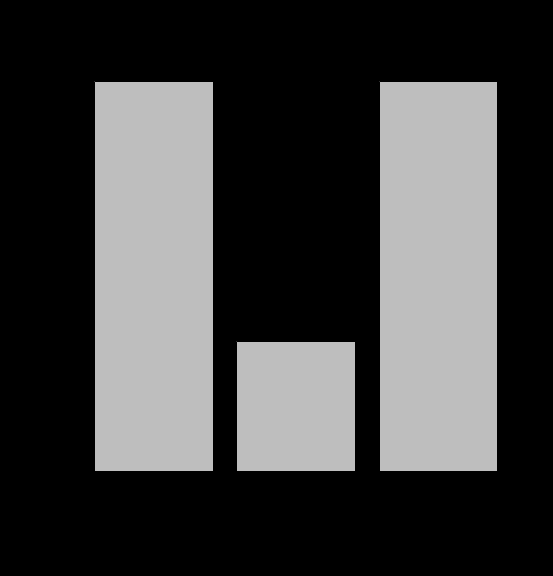
2. Круговая диаграмма pie()
language <-c("Chinese","English","Spanish","Arabian","Hindi","Russian","Portugal","French","Bengali","Malaian")
sum <- c(1030,840,517,490,380,290,250,220,210,210)
pie(sum, labels=language,main = "The most common languages of the world (million)")
3.Curve
Рисует кривую, соответствующую функции по интервалу [from, to]. Curve может также отображать выражение в переменной xname, по умолчанию x,
plot(sin)
plot(sin(1:10))
curve(sin(x),0,10)
curve(cos(x),add=T)
curve(sin(x),0,10)
curve(cos(x),add=T,col="violet")
 curve(3*x^2,from=1,to=10,n=100,xlab="xvalve",ylab="yvalve",col="blue",lwd=2,main="Plot of (3*x^2))
curve(3*x^2,from=1,to=10,n=100,xlab="xvalve",ylab="yvalve",col="blue",lwd=2,main="Plot of (3*x^2))

4. Apply
apply - Когда вы хотите применить функцию к строкам или столбцам матрицы (и более высоким размерным аналогам.
lapply - Если вы хотите применить функцию к каждому элементу списка по очереди и получить список обратно. Это рабочая лошадка многих других функций приложения. Откиньте свой код, и вы часто найдете lapplyпод ним.
x <- list(a =1, b =1:3, c =10:100)
lapply(x, FUN = length)
$a
[1]1
$b
[1]3
$c
[1]91
sapply - Если вы хотите применить функцию к каждому элементу списка по очереди, но вам нужен вектор назад, а не список. Если вы обнаружите, что печатаете unlist(lapply(...)), остановитесь и рассмотрите sapply.
x <- list(a =1, b =1:3, c =10:100)
sapply(x, FUN = length)
a b c
1391
vapply - Когда вы хотите использовать, sapplyно, возможно, вам нужно будет выжать еще больше скорости из вашего кода. Ибо vapply, вы в основном даете R пример того, что будет возвращать ваша функция, что может сэкономить некоторое время, чтобы вернуть возвращаемые значения в один атомный вектор.
x <- list(a =1, b =1:3, c =10:100).
vapply(x, FUN = length, FUN.VALUE =0)
a b c
1391
mapply - если у вас есть несколько структур данных (например, векторы, списки), и вы хотите применить функцию к 1-му элементам каждого из них, а затем по 2-му элементам каждого и т. д., принуждение результата к вектору / массиву, как в sapply, Это многомерность в том смысле, что ваша функция должна принимать несколько аргументов.
mapply(sum,1:5,1:5,1:5)[1]3691215#To do rep(1,4), rep(2,3), etc.
mapply(rep,1:4,4:1)[[1]][1]1111[[2]][1]222[[3]][1]33[[4]][1]4
rapply - если вы хотите применить функцию к каждому элементу вложенной структуры списка, рекурсивно. Чтобы дать вам некоторое представление о том, как необычно rapply, я забыл об этом, когда сначала отправлял этот ответ! Очевидно, я уверен, что многие используют его, поэтому YMMV.
l <- list(a = list(a1 ="Boo", b1 =2, c1 ="Eeek"),
b =3, c ="Yikes",
d = list(a2 =1, b2 = list(a3 ="Hey", b3 =5)))#Result is named vector, coerced to character
rapply(l,myFun)#Result is a nested list like l, with values altered
rapply(l, myFun, how ="replace"
tapply - Если вы хотите применить функцию к подмножествам вектора, а подмножества определяются каким-либо другим вектором, обычно фактором.
tapply(x, y, sum)
a b c d e
1026425874
5 . Function
angle <- function(x,y){
dot.prod <- x%*%y
norm.x <- sqrt(sum(x^2))
norm.y <- sqrt(sum(y^2))
theta <- dot.prod / (norm.x * norm.y)
as.numeric(theta)
}
x <- c(2,1,3)
y <- c(1,2,4)
angle(x,y)
Классификация
install.packages ("rattle")
install.packages ("klaR")
library (rattle)
library (rpart.plot)
library (RColorBrewer)
names <- c ("kazakh", "russian", "german", "masai" , " tutsi", "chinaman")
curlyhair <- c(F,F,F,T,T,F)
lightskin <- c(F,T,T,F,F,F)
hasheightsmall <- c(T,F,F,F,F,T)
class <- c("Mongolian", "European","European", "Negroid", "Negroid","Mongolian" )
people <- data.frame (names, curlyhair, lightskin, class,hasheightsmall)
people$curlyhair <- as.factor (people$curlyhair)
people$lightskin <- as.factor (people$lightskin)
people$hasheightsmall <- as.factor (people$hasheightsmall)
tree <- rpart (class
curlyhair+lightskin+hasheightsmall, data=people, method = "class", minsplit=2)
Помощь
help(topic), ?topic — справка про topic
help.search("pattern"), ??pattern — глобальный поиск pattern
help(package = ) — справка о заданном пакете
help.start() — запустить помощь в браузере
apropos(what) — имена объектов, которые соответствуют what
args(name) — аргументы команды name
example(topic) — примеры использования topic
Текущее окружение
ls() — список всех объектов
rm(x) — удалить объект
dir() — показать все файлы в текущей директории
getwd() — получить текущую директорию
setwd(dir) — поменять текущую директорию на dir
Общая работа с объектами
str(object) — внутренняя структура объекта object
summary(object) — общая информация об объекте object
dput(x) — получить представление объекта в R-синтаксисе
head(x) — посмотреть начальные строки объекта
tail(x) — посмотреть последние строки объекта
Ввод и вывод
library(package) — подключить пакет package
save(file, ...) — сохраняет указанные объекты в двочином XDR-формате, который не зависит от платформы
load() — загружает данные, сохранённые ранее с помощью команды save()
read.table — считывает таблицу данных и создаёт по ним data.frame
write.table — печатает объект, конвертируя его в data.frame
read.csv — считывает csv-файл
read.delim — считывание данных, разделённых знаками табуляции
save.image — сохраняет все объекты в файл
cat(..., file= , sep= ) — сохраняет аргументы, конкатенируя их через sep
sink(file) — выводит результаты выполнения других команд в файл в режиме реального времени до момента вызова этой же команды без аргументов
Создание объектов
from:to — генерирует последовательность чисел от from до to с шагом 1, например 1:3
с(...) — объединяет аргументы в вектор, например c(1, 2, 3)
seq(from, to, by = ) — генерирует последовательность числел от from до to с шагом by
seq(from, to, len = ) — генерирует последовательность числел от from до to длины len
rep(x, times) — повторяет x ровно times раз
list(...) — создаёт список объектов
data.frame(...) — создаёт фрейм данных
array(data, dims) — создаёт из data многомерные массив размерностей dim
matrix(data, nrow = , ncol = , byrow = ) — создаёт из data матрицу nrow на ncol, порядок заполнения определяется byrow
factor(x, levels = ) — создаёт из x фактор с уровнями levels
gl(n, k, length = n*k, labels = 1:n) — создаёт фактор из n уровней, каждый из которых повторяется k раз длины length с именами labels
rbind(...) — объединяет аргументы по строкам
cbind(...) — объединяет аргументы по столбцам
Индексирование
Векторы
x[n]
n-ый элемент
x[-n]
все элементы, кроме n-го
x[1:n]
первые n элементов
x[-(1:n)]
все элементы, кроме первых n
x[c(1,4,2)]
элементы с заданными индексами
x["name"]
элемент с заданным именем
x[x > 3]
все элементы, большие 3
x[x > 3 & x < 5]
все элементы между 3 и 5
x[x %in% c("a","and","the")]
все элементы из заданного множества
Списки
x[n]
список, состоящий из элемента n
x[[n]]
n-ый элемент списка
x[["name"]]
элемент списка с именем name
x$name
элемент списка с именем name
Матрицы
x[i, j]
элемент на пересечении i-ой строки и j-го столбца
x[i,]
i-ая строка
x[,j]
j-ый столбец
x[,c(1,3)]
заданное подмножество столбцов
x["name", ]
строка с именем name
Фреймы
x[["name"]]
столбец с именем name
x$name
столбец с именем name
Работа с переменными
as.array(x), as.data.frame(x), as.numeric(x), as.logical(x), as.complex(x), as.character(x) — преобразование переменной к заданному типу is.na(x), is.null(x), is.array(x), is.data.frame(x), is.numeric(x), is.complex(x), is.character(x) — проверка на то, что данный объект обладает указанным типом
length(x) — число элементов в x
dim(x) — размерности объекта x
dimnames(x) — имена размерностей объекта x
names(x) — имена объекта x
nrow(x) — число строк x
ncol(x) — число столбцов x
class(x) — класс объекта x
unclass(x) — удаляет атрибут класса у объекта x
attr(x,which) — атрибут which объекта x
attributes(obj) — список атрибутов объекта obj
Манипуляция данными
which.max(x) — индекс элемента с максимальным значением
which.min(x) — индекс элемента с минимальным значением
rev(x) — реверсирует порядок элементов
sort(x) — сортирует элементы объекта по возрастанию
cut(x,breaks) — делит вектор на равные интервалы
match(x, y) — ищет элементы x, которые есть в y
which(x == a) — возвращает порядковые элементы x, которые равны a
na.omit(x) — исключает отсутствующие значения объекта
na.fail(x) — бросает исключение, если объект содержит отсутствующие значения
unique(x) — исключает из объекта повторяющиеся элементы
table(x) — создаёт таблицу с количеством повторений каждого уникального элемента
subset(x, ...) — возвращает подмножество элемента, которое соответствует заданному условию
sample(x, size) — возвращает случайный набор размера size из элементов x
replace(x, list, values) — заменяет значения x c индексами из list значениями из values
append(x, values) — добавляет элементы values в вектор x
Математика
sin(x), cos(x), tan(x), asin(x), acos(x), atan(x), atan2(y, x), log(x), log(x, base), log10(x), exp(x) — элементарные математические функции
min(x), max(x) — минимальный и максимальный элементы объекта
range(x) — вектор из минимального и максимального элемента объекта
pmin(x, y), pmax(x, y) — возвращают вектор с минимальными (максимальными) для каждой пары x[i], y[i]
sum(x) — сумма элементов объекта
prod(x) — произведение элементов объекта
diff(x) — возвращает вектор из разниц между соседними элементами
mean(x) — среднее арифметическое элементов объекта
median(x) — медиана (средний элемент) объекта
weighted.mean(x, w) — средневзвешенное объекта x (w определяет веса)
round(x, n) — округляет x до n знаков после запятой
cumsum(x), cumprod(x), cummin(x), cummax(x) — кумулятивные суммы, произведения, минимумы и максимумы вектора x (i-ый элемент содержит статистику по элементам x[1:i])
union(x, y), intersect(x, y), setdiff(x,y), setequal(x,y), is.element(el,set) — операции над множествами: объединение, пересечение, разность, сравнение, принадлежность
Re(x), Im(x), Mod(x), Arg(x), Conj(x) — операции над комплексными числами: целая часть, мнимая часть, модуль, аргумент, сопряжённое число
fft(x), mvfft(x) — быстрое преобразование Фурье
choose(n, k) — количество сочетаний
rank(x) — ранжирует элементы объекта
Матрицы
%*% — матричное умножение
t(x) — транспонированная матрица
diag(x) — диагональ матрицы
solve(a, b) — решает систему уравнений a %*% x = b
solve(a) — обратная матрица
colSums, rowSums, colMeans, rowMeans — суммы и средние по столбцам и по строкам
Обработка данных
apply(X,INDEX,FUN=) — возвращает вектор, массив или список значений, полученных путем применения функции FUN к определенным элементам массива или матрицы x; подлежащие обработке элементы х указываются при помощи аргумента MARGIN;
lapply(X,FUN) — возвращает список той же длины, что и х; при этом значения в новом списке будут результатом применения функции FUN к элементам исходного объекта х
tapply(X,INDEX,FUN=) — применяет функцию FUN к каждой совокупности значений х, созданной в соответствии с уровнями определенного фактора; перечень факторов указывается при помощи аргумента INDEX
by(data,INDEX,FUN) — аналог tapply(), применяемый к таблицам данных
merge(a,b) — объединяет две таблицы данных (а и b) по общим столбцами или строкам
aggregate(x,by,FUN) — разбивает таблицу данных х на отдельные наборы данных, применяет к этим наборам определенную функцию FUN и возвращает результат в удобном для чтения формате
stack(x, ...) — преобразует данные, представленные в объекте х в виде отдельных столбцов, в таблицу данных
unstack(x, ...) — выполняет операцию, обратную действию функции stack()
reshape(x, ...) — преобразует таблицу данных из «широкого формата» (повторные измерения какой-либо величины записаны в отдельных столбцах таблицы) в таблицу "узкого формата" (повторные измерения идут одно под одним в пределах одного столбца)
Строки
print(x) — выводит на экран x
sprintf(fmt, ...) — форматирование текста в C-style (можно использовать %s, %.5f и т.п.)
format(x) — форматирует объект x так, чтобы он выглядел красиво при выводе на экран
paste(...) — конвертирует векторы в текстовые переменные и объединяет их в одно текстовое выражение
substr(x,start,stop) — получение подстроки
strsplit(x,split) — разбивает строку х на подстроки в соответствии с split
grep(pattern,x) (а также grepl, regexpr, gregexpr, regexec) — поиск по регулярному выражению
gsub(pattern,replacement,x) (а также sub) — замена по регулярному выражению
tolower(x) — привести строку к нижнему регистру
toupper(x) — привести строку к верхнему регистру
match(x,table), x %in% table — выполняет поиск элементов в векторе table, которые совпадают со значениями из вектора х
pmatch(x,table) — выполняет поиск элементов в векторе table, которые частично совпадают с элементами вектора х
nchar(x) — возвращает количество знаков в строке х
Дата и время
as.Date(s) — конвертирует вектор s в объект класса Date
as.POSIXct(s) — конвертирует вектор s в объект класса POSIXct
Рисование графиков
plot(x) — график x
plot(x, y) — график зависимости y от x
hist(x) — гистограмма
barplot(x) — столбчатая диаграмма
dotchart(x) — диаграмма Кливленда
pie(x) — круговая диаграмма
boxplot(x) — график типа "коробочки с усами"
sunflowerplot(x, y) — то же, что и plot(), однако точки с одинаковыми координатами изображаются в виде "ромашек", количество лепестков у которых пропорционально количеству таких точек
coplot(x˜y | z) — график зависимости y от x для каждого интервала значений z
interaction.plot(f1, f2, y) — если f1 и f2 — факторы, эта фукнция создаст график со средними значениями y в соответствии со значениями f1 (по оси х) и f2 (по оси у, разные кривые)
matplot(x, y) — график зависимости столбцов y от столбцов x
fourfoldplot(x) — изображает (в виде частей окружности) связь между двумя бинарными переменными в разных совокупностях
assocplot(x) — график Кохена-Френдли
mosaicplot(x) — мозаичный график остатков лог-линейной регрессии
pairs(x) — если х - матрица или таблица данных, эта функция изобразит диаграммы рассеяния для всех возможных пар переменных из х
plot.ts(x), ts.plot(x) — изображает временной ряд
qqnorm(x) — квантили
qqplot(x, y) — график зависимости квантилей y от квантилей х
contour(x, y, z) — выполняет интерполяцию данных и создает контурный график
filled.contour(x, y, z) — то же, что contour(), но заполняет области между контурами определёнными цветами
image(x, y, z) — изображает исходные данные в виде квадратов, цвет которых определяется значениями х и у
persp(x, y, z) — то же, что и image(), но в виде трехмерного графика
stars(x) — если x — матрица или таблица данных, изображает график в виде "звезд" так, что каждая строка представлена "звездой", а столбцы задают длину сегментов этих "звезд"
symbols(x, y, ...) — изображает различные символы в соответствии с координатами
termplot(mod.obj) — зображает частные эффекты переменных из регрессионной модели
Рисование графиков на низком уровне
points(x, y) — рисование точек
lines(x, y) — рисование линии
text(x, y, labels, ...) — добавление текстовой надписи
mtext(text, side=3, line=0, ...) — добавление текстовой надписи
segments(x0, y0, x1, y1) — рисование отрезка
arrows(x0, y0, x1, y1, angle= 30, code=2) — рисование стрелочки
abline(a,b) — рисование наклонной прямой
abline(h=y) — рисование вертикальной прямой
abline(v=x) — рисование горизонтальной прямой
abline(lm.obj) — рисование регрессионной прямой
rect(x1, y1, x2, y2) — рисование прямоугольника
polygon(x, y) — рисование многоугольника
legend(x, y, legend) — добавление легенды
title() — добавление заголовка
axis(side, vect) — добавление осей
rug(x) — рисование засечек на оси X
locator(n, type = "n", ...) — возвращает координаты на графике, в которые кликнул пользователь
Lattice-графика
xyplot(y˜x) — график зависимости у от х
barchart(y˜x) — столбчатая диаграмма
dotplot(y˜x) — диаграмма Кливленда
densityplot(˜x) — график плотности распределения значений х
histogram(˜x) — гистограмма значений х
bwplot(y˜x) — график типа "коробочки с усами"
qqmath(˜x) — аналог функции qqnorm()
stripplot(y˜x) — аналог функции stripplot(x)
qq(y˜x) — изображает квантили распределений х и у для визуального сравнения этих распределений; переменная х должна быть числовой, переменная у - числовой, текстовой, или фактором с двумя уровнями
splom(˜x) — матрица диаграмм рассеяния (аналог функции pairs())
levelplot(z˜xy|g1g2) — цветной график значений z, координаты которых заданы переменными х и у (очевидно, что x, y и z должны иметь одинаковую длину); g1, g2... (если присутствуют) — факторы или числовые переменные, чьи значения автоматически разбиваются на равномерные отрезки
wireframe(z˜xy|g1g2) — функция для построения трехмерных диаграмм рассеяния и плоскостей; z, x и у - числовые векторы; g1, g2... (если присутствуют) - факторы или числовые переменные, чьи значения автоматически разбиваются на равномерные отрезки
cloud(z˜xy|g1g2) — трёхмерная диаграмма рассеяния
Оптимизация и подбор параметров
optim(par, fn, method = ) — оптимизация общего назначения
nlm(f,p) — минимизация функции f алгоритмом Ньютона
lm(formula) — подгонка линейной модели
glm(formula,family=) — подгонка обобщённой линейной модели
nls(formula) — нелинейный метод наименьших квадратов
approx(x,y=) — линейная интерполяция
spline(x,y=) — интерполяция кубическими сплайнами
loess(formula) — подгонка полиномиальной поверхности
predict(fit,...) — построение прогнозов
coef(fit) — расчётные коэффициенты
Статистика
sd(x) — стандартное отклонение
var(x) — дисперсия
cor(x) — корреляционная матрица
var(x, y) — ковариация между x и y
cor(x, y) — линейная корреляция между x и y
aov(formula) — дисперсионный анализ
anova(fit,...) — дисперсионный анализ для подогнанных моделей fit
density(x) — ядерные плотности вероятностей
binom.test() — точный тест простой гипотезы о вероятности успеха в испытаниях Бернулли
pairwise.t.test() — попарные сравнения нескольки независимых или зависимых выборок
prop.test() — проверка гипотезы о том, что частоты какого-либо признака равны во всех анализируемых группах
t.test() — тест Стьюдента
Распределения
rnorm(n, mean=0, sd=1) — нормальное распределение
rexp(n, rate=1) — экспоненциальное распределение
rgamma(n, shape, scale=1) — гамма-распределение
rpois(n, lambda) — распределение Пуассона
rweibull(n, shape, scale=1) — распределение Вейбулла
rcauchy(n, location=0, scale=1) — распределение Коши
rbeta(n, shape1, shape2) — бета-распределение
rt(n, df) — распределение Стьюдента
rf(n, df1, df2) — распределение Фишера
rchisq(n, df) — распределение Пирсона
rbinom(n, size, prob) — биномиальное распределение
rgeom(n, prob) — геометрическое распределение
rhyper(nn, m, n, k) — гипергеометрическое распределение
rlogis(n, location=0, scale=1) — логистическое распределение
rlnorm(n, meanlog=0, sdlog=1) — логнормальное распределение
rnbinom(n, size, prob) — отрицательное биномиальное распределение
runif(n, min=0, max=1) — равномерное распределение
Программирование
Работа с функциями:
function(arglist) { expr } — создание пользовательской функции
return(value) — возвращение значения
do.call(funname, args) — вызывает функцию по имени
Условные операторы:
if(cond) expr
if(cond) cons.expr else alt.expr
ifelse(test, yes, no)
Циклы:
for(var in seq) expr
while(cond) expr
repeat expr
break — остановка цикла
№ 1 Лабораторная работа
> FIO < - c("Assylbekova.M.C","Armiyanova.E.G ","Kengessova.A.D","Kydyrbekova.L.S","Aidyn.D","Toktaganova.Zh","Nurkabdenov.D")
> FIO
[1] "Assylbekova.M.C" "Armiyanova.E.G " "Kengessova.A.D" "Kydyrbekova.L.S"
[5] "Aidyn.D" "Toktaganova.Zh" "Nurkabdenov.D"
> AGE <- sample(2,7, replace = T)+17
> AGE
[1] 18 18 18 19 18 19 19
> AGE <- c (19,18,18,18,20,20,18)
> AGE
[1] 19 18 18 18 20 20 18
> HEIGHT <- c (160,175,152,162,174,150,175)
> HEIGHT
[1] 160 175 152 162 174 150 175
> df <- cbind (FIO, AGE, HEIGHT)
> df
FIO AGE HEIGHT
[1,] "Assylbekova.M.C" "19" "160"
[2,] "Armiyanova.E.G " "18" "175"
[3,] "Kengessova.A.D" "18" "152"
[4,] "Kydyrbekova.L.S" "18" "162"
[5,] "Aidyn.D" "20" "174"
[6,] "Toktaganova.Zh" "20" "150"
[7,] "Nurkabdenov.D" "18" "175"
> dd <- data.frame (FIO, AGE , HEIGHT)
> dd
FIO AGE HEIGHT
1 Assylbekova.M.C 19 160
2 Armiyanova.E.G 18 175
3 Kengessova.A.D 18 152
4 Kydyrbekova.L.S 18 162
5 Aidyn.D 20 174
6 Toktaganova.Zh 20 150
7 Nurkabdenov.D 18 175
> save.image("C:\\Users\\Molya\\Documents\\spisok gruppy")
> Weight <- c (45,65,50,55,60,45,60)
> Weight
[1] 45 65 50 55 60 45 60
> dd <- cbind (Weight)
> dd
Weight
[1,] 45
[2,] 65
[3,] 50
[4,] 55
[5,] 60
[6,] 45
[7,] 60
> dd <- data.frame (FIO, AGE , HEIGHT)
> dd
FIO AGE HEIGHT
1 Assylbekova.M.C 19 160
2 Armiyanova.E.G 18 175
3 Kengessova.A.D 18 152
4 Kydyrbekova.L.S 18 162
5 Aidyn.D 20 174
6 Toktaganova.Zh 20 150
7 Nurkabdenov.D 18 175
> dd <- cbind (dd, Weight)
> dd
FIO AGE HEIGHT Weight
1 Assylbekova.M.C 19 160 45
2 Armiyanova.E.G 18 175 65
3 Kengessova.A.D 18 152 50
4 Kydyrbekova.L.S 18 162 55
5 Aidyn.D 20 174 60
6 Toktaganova.Zh 20 150 45
7 Nurkabdenov.D 18 175 60
> mean (dd$AGE )
[1] 18.71429
> mean (dd$HEIGHT)
[1] 164
> mean (dd$Weight)
[1] 54.28571
> max(dd$AGE )
[1] 20
> min (dd$AGE)
[1] 18
> var (dd$Weight)
[1] 61.90476
>nrow(FIO)
>ncol(dd)
> save.image("C:\\Users\\Molya\\Documents\\sps")
№ 2 Лабораторная работа
Создала таблицу в эксель потом сохранила с расширением csv (MS DOS).
Открыла эту таблицу на языке R
m <-read.csv2 (“C:/R/labor 2”)
Управляющие параметры функции PLOT()
Функция plot() имеет большое количество управляющих параметров, которые позволяют осуществлять очень тонкую настройку внешнего вида графика.
Plot (m$AGE
m$HEIGHT) (Строем график)
Plot (m$AGE
m$HEIGHT, col= “green”) потом задала красный цвет
Параметр type
Параметр type позволяет изменять внешний вид точек на графике. Он принимает одно из следующих текстовых значений:
"p" - точки (points; используется по умолчанию)
"l" - линии (lines)
"b" - изображаются и точки, и линии (both points and lines)
"o" - точки изображаются поверх линий (points over lines)
"h" - гистограмма (histogram)
"s" - ступенчатая кривая (steps)
"n" - данные не отображаются (no points)
plot (m$AGE
m$HEIGHT, col="green", type="o") изменила тип на о
Параметры xlim и ylim
Эти два параметра контролирут размах значений на каждой из осей графика. По умолчанию они оба принимают значение NULL - в этом случае размах выбирается программой автоматически. Для отмены автоматических настроек соответствующему параметру необходимо присвоить значение в виде числового вектора, содержащего минимальное и максимальное значения, которые должны отображаться на оси.
plot (m$AGE
m$HEIGHT, col="green", type="o",xlim=c(18,175)) // x=18,y=175
Параметры axes и ann
Эти два параметра контролируют отображение осей и их названий соответственно. Каждый из них может принимать два значения - TRUE или FALSE
plot (m$AGE
m$HEIGHT, col="green", type="o",axes=F,ann=T)
Параметр main
Аргумент main служит для создания названия графика. По умолчанию название размещается в верхней части рисунка:
plot (m$AGE
m$HEIGHT, col="green", type="o",main= “Graph”)
Параметр PCH
PCH-числовой аргумент, который имеет от 0 до 25 имеет разные фигуры.
Например:1-круглый,2-триугольник plot (m$AGE
m$HEIGHT, col="green", type="o", pch=5)//я выбрала 5-ромбик
Помощь
help(topic), ?topic — справка про topic
help.search("pattern"), ??pattern — глобальный поиск pattern
help(package = ) — справка о заданном пакете
help.start() — запустить помощь в браузере
apropos(what) — имена объектов, которые соответствуют what
args(name) — аргументы команды name
example(topic) — примеры использования topic
Текущее окружение
ls() — список всех объектов
rm(x) — удалить объект
dir() — показать все файлы в текущей директории
getwd() — получить текущую директорию
setwd(dir) — поменять текущую директорию на dir
Общая работа с объектами
str(object) — внутренняя структура объекта object
summary(object) — общая информация об объекте object
dput(x) — получить представление объекта в R-синтаксисе
head(x) — посмотреть начальные строки объекта
tail(x) — посмотреть последние строки объекта
Ввод и вывод
library(package) — подключить пакет package
save(file, ...) — сохраняет указанные объекты в двочином XDR-формате, который не зависит от платформы
load() — загружает данные, сохранённые ранее с помощью команды save()
read.table — считывает таблицу данных и создаёт по ним data.frame
write.table — печатает объект, конвертируя его в data.frame
read.csv — считывает csv-файл
read.delim — считывание данных, разделённых знаками табуляции
save.image — сохраняет все объекты в файл
cat(..., file= , sep= ) — сохраняет аргументы, конкатенируя их через sep
sink(file) — выводит результаты выполнения других команд в файл в режиме реального времени до момента вызова этой же команды без аргументов
Создание объектов
from:to — генерирует последовательность чисел от from до to с шагом 1, например 1:3
с(...) — объединяет аргументы в вектор, например c(1, 2, 3)
seq(from, to, by = ) — генерирует последовательность числел от from до to с шагом by
seq(from, to, len = ) — генерирует последовательность числел от from до to длины len
rep(x, times) — повторяет x ровно times раз
list(...) — создаёт список объектов
data.frame(...) — создаёт фрейм данных
array(data, dims) — создаёт из data многомерные массив размерностей dim
matrix(data, nrow = , ncol = , byrow = ) — создаёт из data матрицу nrow на ncol, порядок заполнения определяется byrow
factor(x, levels = ) — создаёт из x фактор с уровнями levels
gl(n, k, length = n*k, labels = 1:n) — создаёт фактор из n уровней, каждый из которых повторяется k раз длины length с именами labels
rbind(...) — объединяет аргументы по строкам
cbind(...) — объединяет аргументы по столбцам
Индексирование
Векторы
x[n]
n-ый элемент
x[-n]
все элементы, кроме n-го
x[1:n]
первые n элементов
x[-(1:n)]
все элементы, кроме первых n
x[c(1,4,2)]
элементы с заданными индексами
x["name"]
элемент с заданным именем
x[x > 3]
все элементы, большие 3
x[x > 3 & x < 5]
все элементы между 3 и 5
x[x %in% c("a","and","the")]
все элементы из заданного множества
Списки
x[n]
список, состоящий из элемента n
x[[n]]
n-ый элемент списка
x[["name"]]
элемент списка с именем name
x$name
элемент списка с именем name
Матрицы
x[i, j]
элемент на пересечении i-ой строки и j-го столбца
x[i,]
i-ая строка
x[,j]
j-ый столбец
x[,c(1,3)]
заданное подмножество столбцов
x["name", ]
строка с именем name
Фреймы
x[["name"]]
столбец с именем name
x$name
столбец с именем name
Работа с переменными
as.array(x), as.data.frame(x), as.numeric(x), as.logical(x), as.complex(x), as.character(x) — преобразование переменной к заданному типу is.na(x), is.null(x), is.array(x), is.data.frame(x), is.numeric(x), is.complex(x), is.character(x) — проверка на то, что данный объект обладает указанным типом
length(x) — число элементов в x
dim(x) — размерности объекта x
dimnames(x) — имена размерностей объекта x
names(x) — имена объекта x
nrow(x) — число строк x
ncol(x) — число столбцов x
class(x) — класс объекта x
unclass(x) — удаляет атрибут класса у объекта x
attr(x,which) — атрибут which объекта x
attributes(obj) — список атрибутов объекта obj
Манипуляция данными
which.max(x) — индекс элемента с максимальным значением
which.min(x) — индекс элемента с минимальным значением
rev(x) — реверсирует порядок элементов
sort(x) — сортирует элементы объекта по возрастанию
cut(x,breaks) — делит вектор на равные интервалы
match(x, y) — ищет элементы x, которые есть в y
which(x == a) — возвращает порядковые элементы x, которые равны a
na.omit(x) — исключает отсутствующие значения объекта
na.fail(x) — бросает исключение, если объект содержит отсутствующие значения
unique(x) — исключает из объекта повторяющиеся элементы
table(x) — создаёт таблицу с количеством повторений каждого уникального элемента
subset(x, ...) — возвращает подмножество элемента, которое соответствует заданному условию
sample(x, size) — возвращает случайный набор размера size из элементов x
replace(x, list, values) — заменяет значения x c индексами из list значениями из values
append(x, values) — добавляет элементы values в вектор x
Математика
sin(x), cos(x), tan(x), asin(x), acos(x), atan(x), atan2(y, x), log(x), log(x, base), log10(x), exp(x) — элементарные математические функции
min(x), max(x) — минимальный и максимальный элементы объекта
range(x) — вектор из минимального и максимального элемента объекта
pmin(x, y), pmax(x, y) — возвращают вектор с минимальными (максимальными) для каждой пары x[i], y[i]
sum(x) — сумма элементов объекта
prod(x) — произведение элементов объекта
diff(x) — возвращает вектор из разниц между соседними элементами
mean(x) — среднее арифметическое элементов объекта
median(x) — медиана (средний элемент) объекта
weighted.mean(x, w) — средневзвешенное объекта x (w определяет веса)
round(x, n) — округляет x до n знаков после запятой
cumsum(x), cumprod(x), cummin(x), cummax(x) — кумулятивные суммы, произведения, минимумы и максимумы вектора x (i-ый элемент содержит статистику по элементам x[1:i])
union(x, y), intersect(x, y), setdiff(x,y), setequal(x,y), is.element(el,set) — операции над множествами: объединение, пересечение, разность, сравнение, принадлежность
Re(x), Im(x), Mod(x), Arg(x), Conj(x) — операции над комплексными числами: целая часть, мнимая часть, модуль, аргумент, сопряжённое число
fft(x), mvfft(x) — быстрое преобразование Фурье
choose(n, k) — количество сочетаний
rank(x) — ранжирует элементы объекта
Матрицы
%*% — матричное умножение
t(x) — транспонированная матрица
diag(x) — диагональ матрицы
solve(a, b) — решает систему уравнений a %*% x = b
solve(a) — обратная матрица
colSums, rowSums, colMeans, rowMeans — суммы и средние по столбцам и по строкам
Обработка данных
apply(X,INDEX,FUN=) — возвращает вектор, массив или список значений, полученных путем применения функции FUN к определенным элементам массива или матрицы x; подлежащие обработке элементы х указываются при помощи аргумента MARGIN;
lapply(X,FUN) — возвращает список той же длины, что и х; при этом значения в новом списке будут результатом применения функции FUN к элементам исходного объекта х
tapply(X,INDEX,FUN=) — применяет функцию FUN к каждой совокупности значений х, созданной в соответствии с уровнями определенного фактора; перечень факторов указывается при помощи аргумента INDEX
by(data,INDEX,FUN) — аналог tapply(), применяемый к таблицам данных
merge(a,b) — объединяет две таблицы данных (а и b) по общим столбцами или строкам
aggregate(x,by,FUN) — разбивает таблицу данных х на отдельные наборы данных, применяет к этим наборам определенную функцию FUN и возвращает результат в удобном для чтения формате
stack(x, ...) — преобразует данные, представленные в объекте х в виде отдельных столбцов, в таблицу данных
unstack(x, ...) — выполняет операцию, обратную действию функции stack()
reshape(x, ...) — преобразует таблицу данных из «широкого формата» (повторные измерения какой-либо величины записаны в отдельных столбцах таблицы) в таблицу "узкого формата" (повторные измерения идут одно под одним в пределах одного столбца)
Строки
print(x) — выводит на экран x
sprintf(fmt, ...) — форматирование текста в C-style (можно использовать %s, %.5f и т.п.)
format(x) — форматирует объект x так, чтобы он выглядел красиво при выводе на экран
paste(...) — конвертирует векторы в текстовые переменные и объединяет их в одно текстовое выражение
substr(x,start,stop) — получение подстроки
strsplit(x,split) — разбивает строку х на подстроки в соответствии с split
grep(pattern,x) (а также grepl, regexpr, gregexpr, regexec) — поиск по регулярному выражению
gsub(pattern,replacement,x) (а также sub) — замена по регулярному выражению
tolower(x) — привести строку к нижнему регистру
toupper(x) — привести строку к верхнему регистру
match(x,table), x %in% table — выполняет поиск элементов в векторе table, которые совпадают со значениями из вектора х
pmatch(x,table) — выполняет поиск элементов в векторе table, которые частично совпадают с элементами вектора х
nchar(x) — возвращает количество знаков в строке х
Дата и время
as.Date(s) — конвертирует вектор s в объект класса Date
as.POSIXct(s) — конвертирует вектор s в объект класса POSIXct
Рисование графиков
plot(x) — график x
plot(x, y) — график зависимости y от x
hist(x) — гистограмма
barplot(x) — столбчатая диаграмма
dotchart(x) — диаграмма Кливленда
pie(x) — круговая диаграмма
boxplot(x) — график типа "коробочки с усами"
sunflowerplot(x, y) — то же, что и plot(), однако точки с одинаковыми координатами изображаются в виде "ромашек", количество лепестков у которых пропорционально количеству таких точек
coplot(x˜y | z) — график зависимости y от x для каждого интервала значений z
interaction.plot(f1, f2, y) — если f1 и f2 — факторы, эта фукнция создаст график со средними значениями y в соответствии со значениями f1 (по оси х) и f2 (по оси у, разные кривые)
matplot(x, y) — график зависимости столбцов y от столбцов x
fourfoldplot(x) — изображает (в виде частей окружности) связь между двумя бинарными переменными в разных совокупностях
assocplot(x) — график Кохена-Френдли
mosaicplot(x) — мозаичный график остатков лог-линейной регрессии
pairs(x) — если х - матрица или таблица данных, эта функция изобразит диаграммы рассеяния для всех возможных пар переменных из х
plot.ts(x), ts.plot(x) — изображает временной ряд
qqnorm(x) — квантили
qqplot(x, y) — график зависимости квантилей y от квантилей х
contour(x, y, z) — выполняет интерполяцию данных и создает контурный график
filled.contour(x, y, z) — то же, что contour(), но заполняет области между контурами определёнными цветами
image(x, y, z) — изображает исходные данные в виде квадратов, цвет которых определяется значениями х и у
persp(x, y, z) — то же, что и image(), но в виде трехмерного графика
stars(x) — если x — матрица или таблица данных, изображает график в виде "звезд" так, что каждая строка представлена "звездой", а столбцы задают длину сегментов этих "звезд"
symbols(x, y, ...) — изображает различные символы в соответствии с координатами
termplot(mod.obj) — зображает частные эффекты переменных из регрессионной модели
Рисование графиков на низком уровне
points(x, y) — рисование точек
lines(x, y) — рисование линии
text(x, y, labels, ...) — добавление текстовой надписи
mtext(text, side=3, line=0, ...) — добавление текстовой надписи
segments(x0, y0, x1, y1) — рисование отрезка
arrows(x0, y0, x1, y1, angle= 30, code=2) — рисование стрелочки
abline(a,b) — рисование наклонной прямой
abline(h=y) — рисование вертикальной прямой
abline(v=x) — рисование горизонтальной прямой
abline(lm.obj) — рисование регрессионной прямой
rect(x1, y1, x2, y2) — рисование прямоугольника
polygon(x, y) — рисование многоугольника
legend(x, y, legend) — добавление легенды
title() — добавление заголовка
axis(side, vect) — добавление осей
rug(x) — рисование засечек на оси X
locator(n, type = "n", ...) — возвращает координаты на графике, в которые кликнул пользователь
Lattice-графика
xyplot(y˜x) — график зависимости у от х
barchart(y˜x) — столбчатая диаграмма
dotplot(y˜x) — диаграмма Кливленда
densityplot(˜x) — график плотности распределения значений х
histogram(˜x) — гистограмма значений х
bwplot(y˜x) — график типа "коробочки с усами"
qqmath(˜x) — аналог функции qqnorm()
stripplot(y˜x) — аналог функции stripplot(x)
qq(y˜x) — изображает квантили распределений х и у для визуального сравнения этих распределений; переменная х должна быть числовой, переменная у - числовой, текстовой, или фактором с двумя уровнями
splom(˜x) — матрица диаграмм рассеяния (аналог функции pairs())
levelplot(z˜xy|g1g2) — цветной график значений z, координаты которых заданы переменными х и у (очевидно, что x, y и z должны иметь одинаковую длину); g1, g2... (если присутствуют) — факторы или числовые переменные, чьи значения автоматически разбиваются на равномерные отрезки
wireframe(z˜xy|g1g2) — функция для построения трехмерных диаграмм рассеяния и плоскостей; z, x и у - числовые векторы; g1, g2... (если присутствуют) - факторы или числовые переменные, чьи значения автоматически разбиваются на равномерные отрезки
cloud(z˜xy|g1g2) — трёхмерная диаграмма рассеяния
Оптимизация и подбор параметров
optim(par, fn, method = ) — оптимизация общего назначения
nlm(f,p) — минимизация функции f алгоритмом Ньютона
lm(formula) — подгонка линейной модели
glm(formula,family=) — подгонка обобщённой линейной модели
nls(formula) — нелинейный метод наименьших квадратов
approx(x,y=) — линейная интерполяция
spline(x,y=) — интерполяция кубическими сплайнами
loess(formula) — подгонка полиномиальной поверхности
predict(fit,...) — построение прогнозов
coef(fit) — расчётные коэффициенты
Статистика
sd(x) — стандартное отклонение
var(x) — дисперсия
cor(x) — корреляционная матрица
var(x, y) — ковариация между x и y
cor(x, y) — линейная корреляция между x и y
aov(formula) — дисперсионный анализ
anova(fit,...) — дисперсионный анализ для подогнанных моделей fit
density(x) — ядерные плотности вероятностей
binom.test() — точный тест простой гипотезы о вероятности успеха в испытаниях Бернулли
pairwise.t.test() — попарные сравнения нескольки независимых или зависимых выборок
prop.test() — проверка гипотезы о том, что частоты какого-либо признака равны во всех анализируемых группах
t.test() — тест Стьюдента
Распределения
rnorm(n, mean=0, sd=1) — нормальное распределение
rexp(n, rate=1) — экспоненциальное распределение
rgamma(n, shape, scale=1) — гамма-распределение
rpois(n, lambda) — распределение Пуассона
rweibull(n, shape, scale=1) — распределение Вейбулла
rcauchy(n, location=0, scale=1) — распределение Коши
rbeta(n, shape1, shape2) — бета-распределение
rt(n, df) — распределение Стьюдента
rf(n, df1, df2) — распределение Фишера
rchisq(n, df) — распределение Пирсона
rbinom(n, size, prob) — биномиальное распределение
rgeom(n, prob) — геометрическое распределение
rhyper(nn, m, n, k) — гипергеометрическое распределение
rlogis(n, location=0, scale=1) — логистическое распределение
rlnorm(n, meanlog=0, sdlog=1) — логнормальное распределение
rnbinom(n, size, prob) — отрицательное биномиальное распределение
runif(n, min=0, max=1) — равномерное распределение
Программирование
Работа с функциями:
function(arglist) { expr } — создание пользовательской функции
return(value) — возвращение значения
do.call(funname, args) — вызывает функцию по имени
Условные операторы:
if(cond) expr
if(cond) cons.expr else alt.expr
ifelse(test, yes, no)
Циклы:
for(var in seq) expr
while(cond) expr
repeat expr
break — остановка цикла
№ 1 Лабораторная работа
> FIO < - c("Assylbekova.M.C","Armiyanova.E.G ","Kengessova.A.D","Kydyrbekova.L.S","Aidyn.D","Toktaganova.Zh","Nurkabdenov.D")
> FIO
[1] "Assylbekova.M.C" "Armiyanova.E.G " "Kengessova.A.D" "Kydyrbekova.L.S"
[5] "Aidyn.D" "Toktaganova.Zh" "Nurkabdenov.D"
> AGE <- sample(2,7, replace = T)+17
> AGE
[1] 18 18 18 19 18 19 19
> AGE <- c (19,18,18,18,20,20,18)
> AGE
[1] 19 18 18 18 20 20 18
> HEIGHT <- c (160,175,152,162,174,150,175)
> HEIGHT
[1] 160 175 152 162 174 150 175
> df <- cbind (FIO, AGE, HEIGHT)
> df
FIO AGE HEIGHT
[1,] "Assylbekova.M.C" "19" "160"
[2,] "Armiyanova.E.G " "18" "175"
[3,] "Kengessova.A.D" "18" "152"
[4,] "Kydyrbekova.L.S" "18" "162"
[5,] "Aidyn.D" "20" "174"
[6,] "Toktaganova.Zh" "20" "150"
[7,] "Nurkabdenov.D" "18" "175"
> dd <- data.frame (FIO, AGE , HEIGHT)
> dd
FIO AGE HEIGHT
1 Assylbekova.M.C 19 160
2 Armiyanova.E.G 18 175
3 Kengessova.A.D 18 152
4 Kydyrbekova.L.S 18 162
5 Aidyn.D 20 174
6 Toktaganova.Zh 20 150
7 Nurkabdenov.D 18 175
> save.image("C:\\Users\\Molya\\Documents\\spisok gruppy")
> Weight <- c (45,65,50,55,60,45,60)
> Weight
[1] 45 65 50 55 60 45 60
> dd <- cbind (Weight)
> dd
Weight
[1,] 45
[2,] 65
[3,] 50
[4,] 55
[5,] 60
[6,] 45
[7,] 60
> dd <- data.frame (FIO, AGE , HEIGHT)
> dd
FIO AGE HEIGHT
1 Assylbekova.M.C 19 160
2 Armiyanova.E.G 18 175
3 Kengessova.A.D 18 152
4 Kydyrbekova.L.S 18 162
5 Aidyn.D 20 174
6 Toktaganova.Zh 20 150
7 Nurkabdenov.D 18 175
> dd <- cbind (dd, Weight)
> dd
FIO AGE HEIGHT Weight
1 Assylbekova.M.C 19 160 45
2 Armiyanova.E.G 18 175 65
3 Kengessova.A.D 18 152 50
4 Kydyrbekova.L.S 18 162 55
5 Aidyn.D 20 174 60
6 Toktaganova.Zh 20 150 45
7 Nurkabdenov.D 18 175 60
> mean (dd$AGE )
[1] 18.71429
> mean (dd$HEIGHT)
[1] 164
> mean (dd$Weight)
[1] 54.28571
> max(dd$AGE )
[1] 20
> min (dd$AGE)
[1] 18
> var (dd$Weight)
[1] 61.90476
>nrow(FIO)
>ncol(dd)
> save.image("C:\\Users\\Molya\\Documents\\sps")
№ 2 Лабораторная работа
Создала таблицу в эксель потом сохранила с расширением csv (MS DOS).
Открыла эту таблицу на языке R
m <-read.csv2 (“C:/R/labor 2”)
Управляющие параметры функции PLOT()
Функция plot() имеет большое количество управляющих параметров, которые позволяют осуществлять очень тонкую настройку внешнего вида графика.
Plot (m$AGE
m$HEIGHT) (Строем график)
Plot (m$AGE
m$HEIGHT, col= “green”) потом задала красный цвет
Параметр type
Параметр type позволяет изменять внешний вид точек на графике. Он принимает одно из следующих текстовых значений:
"p" - точки (points; используется по умолчанию)
"l" - линии (lines)
"b" - изображаются и точки, и линии (both points and lines)
"o" - точки изображаются поверх линий (points over lines)
"h" - гистограмма (histogram)
"s" - ступенчатая кривая (steps)
"n" - данные не отображаются (no points)
plot (m$AGE
m$HEIGHT, col="green", type="o") изменила тип на о
Параметры xlim и ylim
Эти два параметра контролирут размах значений на каждой из осей графика. По умолчанию они оба принимают значение NULL - в этом случае размах выбирается программой автоматически. Для отмены автоматических настроек соответствующему параметру необходимо присвоить значение в виде числового вектора, содержащего минимальное и максимальное значения, которые должны отображаться на оси.
plot (m$AGE
m$HEIGHT, col="green", type="o",xlim=c(18,175)) // x=18,y=175
Параметры axes и ann
Эти два параметра контролируют отображение осей и их названий соответственно. Каждый из них может принимать два значения - TRUE или FALSE
plot (m$AGE
m$HEIGHT, col="green", type="o",axes=F,ann=T)
Помощь
help(topic), ?topic — справка про topic
help.search("pattern"), ??pattern — глобальный поиск pattern
help(package = ) — справка о заданном пакете
help.start() — запустить помощь в браузере
apropos(what) — имена объектов, которые соответствуют what
args(name) — аргументы команды name
example(topic) — примеры использования topic
Текущее окружение
ls() — список всех объектов
rm(x) — удалить объект
dir() — показать все файлы в текущей директории
getwd() — получить текущую директорию
setwd(dir) — поменять текущую директорию на dir
Общая работа с объектами
str(object) — внутренняя структура объекта object
summary(object) — общая информация об объекте object
dput(x) — получить представление объекта в R-синтаксисе
head(x) — посмотреть начальные строки объекта
tail(x) — посмотреть последние строки объекта
Ввод и вывод
library(package) — подключить пакет package
save(file, ...) — сохраняет указанные объекты в двочином XDR-формате, который не зависит от платформы
load() — загружает данные, сохранённые ранее с помощью команды save()
read.table — считывает таблицу данных и создаёт по ним data.frame
write.table — печатает объект, конвертируя его в data.frame
read.csv — считывает csv-файл
read.delim — считывание данных, разделённых знаками табуляции
save.image — сохраняет все объекты в файл
cat(..., file= , sep= ) — сохраняет аргументы, конкатенируя их через sep
sink(file) — выводит результаты выполнения других команд в файл в режиме реального времени до момента вызова этой же команды без аргументов
Создание объектов
from:to — генерирует последовательность чисел от from до to с шагом 1, например 1:3
с(...) — объединяет аргументы в вектор, например c(1, 2, 3)
seq(from, to, by = ) — генерирует последовательность числел от from до to с шагом by
seq(from, to, len = ) — генерирует последовательность числел от from до to длины len
rep(x, times) — повторяет x ровно times раз
list(...) — создаёт список объектов
data.frame(...) — создаёт фрейм данных
array(data, dims) — создаёт из data многомерные массив размерностей dim
matrix(data, nrow = , ncol = , byrow = ) — создаёт из data матрицу nrow на ncol, порядок заполнения определяется byrow
factor(x, levels = ) — создаёт из x фактор с уровнями levels
gl(n, k, length = n*k, labels = 1:n) — создаёт фактор из n уровней, каждый из которых повторяется k раз длины length с именами labels
rbind(...) — объединяет аргументы по строкам
cbind(...) — объединяет аргументы по столбцам
Индексирование
Векторы
x[n]
n-ый элемент
x[-n]
все элементы, кроме n-го
x[1:n]
первые n элементов
x[-(1:n)]
все элементы, кроме первых n
x[c(1,4,2)]
элементы с заданными индексами
x["name"]
элемент с заданным именем
x[x > 3]
все элементы, большие 3
x[x > 3 & x < 5]
все элементы между 3 и 5
x[x %in% c("a","and","the")]
все элементы из заданного множества
Списки
x[n]
список, состоящий из элемента n
x[[n]]
n-ый элемент списка
x[["name"]]
элемент списка с именем name
x$name
элемент списка с именем name
Матрицы
x[i, j]
элемент на пересечении i-ой строки и j-го столбца
x[i,]
i-ая строка
x[,j]
j-ый столбец
x[,c(1,3)]
заданное подмножество столбцов
x["name", ]
строка с именем name
Фреймы
x[["name"]]
столбец с именем name
x$name
столбец с именем name
Работа с переменными
as.array(x), as.data.frame(x), as.numeric(x), as.logical(x), as.complex(x), as.character(x) — преобразование переменной к заданному типу is.na(x), is.null(x), is.array(x), is.data.frame(x), is.numeric(x), is.complex(x), is.character(x) — проверка на то, что данный объект обладает указанным типом
length(x) — число элементов в x
dim(x) — размерности объекта x
dimnames(x) — имена размерностей объекта x
names(x) — имена объекта x
nrow(x) — число строк x
ncol(x) — число столбцов x
class(x) — класс объекта x
unclass(x) — удаляет атрибут класса у объекта x
attr(x,which) — атрибут which объекта x
attributes(obj) — список атрибутов объекта obj
Манипуляция данными
which.max(x) — индекс элемента с максимальным значением
which.min(x) — индекс элемента с минимальным значением
rev(x) — реверсирует порядок элементов
sort(x) — сортирует элементы объекта по возрастанию
cut(x,breaks) — делит вектор на равные интервалы
match(x, y) — ищет элементы x, которые есть в y
which(x == a) — возвращает порядковые элементы x, которые равны a
na.omit(x) — исключает отсутствующие значения объекта
na.fail(x) — бросает исключение, если объект содержит отсутствующие значения
unique(x) — исключает из объекта повторяющиеся элементы
table(x) — создаёт таблицу с количеством повторений каждого уникального элемента
subset(x, ...) — возвращает подмножество элемента, которое соответствует заданному условию
sample(x, size) — возвращает случайный набор размера size из элементов x
replace(x, list, values) — заменяет значения x c индексами из list значениями из values
append(x, values) — добавляет элементы values в вектор x
Математика
sin(x), cos(x), tan(x), asin(x), acos(x), atan(x), atan2(y, x), log(x), log(x, base), log10(x), exp(x) — элементарные математические функции
min(x), max(x) — минимальный и максимальный элементы объекта
range(x) — вектор из минимального и максимального элемента объекта
pmin(x, y), pmax(x, y) — возвращают вектор с минимальными (максимальными) для каждой пары x[i], y[i]
sum(x) — сумма элементов объекта
prod(x) — произведение элементов объекта
diff(x) — возвращает вектор из разниц между соседними элементами
mean(x) — среднее арифметическое элементов объекта
median(x) — медиана (средний элемент) объекта
weighted.mean(x, w) — средневзвешенное объекта x (w определяет веса)
round(x, n) — округляет x до n знаков после запятой
cumsum(x), cumprod(x), cummin(x), cummax(x) — кумулятивные суммы, произведения, минимумы и максимумы вектора x (i-ый элемент содержит статистику по элементам x[1:i])
union(x, y), intersect(x, y), setdiff(x,y), setequal(x,y), is.element(el,set) — операции над множествами: объединение, пересечение, разность, сравнение, принадлежность
Re(x), Im(x), Mod(x), Arg(x), Conj(x) — операции над комплексными числами: целая часть, мнимая часть, модуль, аргумент, сопряжённое число
fft(x), mvfft(x) — быстрое преобразование Фурье
choose(n, k) — количество сочетаний
rank(x) — ранжирует элементы объекта
Матрицы
%*% — матричное умножение
t(x) — транспонированная матрица
diag(x) — диагональ матрицы
solve(a, b) — решает систему уравнений a %*% x = b
solve(a) — обратная матрица
colSums, rowSums, colMeans, rowMeans — суммы и средние по столбцам и по строкам
Обработка данных
apply(X,INDEX,FUN=) — возвращает вектор, массив или список значений, полученных путем применения функции FUN к определенным элементам массива или матрицы x; подлежащие обработке элементы х указываются при помощи аргумента MARGIN;
lapply(X,FUN) — возвращает список той же длины, что и х; при этом значения в новом списке будут результатом применения функции FUN к элементам исходного объекта х
tapply(X,INDEX,FUN=) — применяет функцию FUN к каждой совокупности значений х, созданной в соответствии с уровнями определенного фактора; перечень факторов указывается при помощи аргумента INDEX
by(data,INDEX,FUN) — аналог tapply(), применяемый к таблицам данных
merge(a,b) — объединяет две таблицы данных (а и b) по общим столбцами или строкам
aggregate(x,by,FUN) — разбивает таблицу данных х на отдельные наборы данных, применяет к этим наборам определенную функцию FUN и возвращает результат в удобном для чтения формате
stack(x, ...) — преобразует данные, представленные в объекте х в виде отдельных столбцов, в таблицу данных
unstack(x, ...) — выполняет операцию, обратную действию функции stack()
reshape(x, ...) — преобразует таблицу данных из «широкого формата» (повторные измерения какой-либо величины записаны в отдельных столбцах таблицы) в таблицу "узкого формата" (повторные измерения идут одно под одним в пределах одного столбца)
Строки
print(x) — выводит на экран x
sprintf(fmt, ...) — форматирование текста в C-style (можно использовать %s, %.5f и т.п.)
format(x) — форматирует объект x так, чтобы он выглядел красиво при выводе на экран
paste(...) — конвертирует векторы в текстовые переменные и объединяет их в одно текстовое выражение
substr(x,start,stop) — получение подстроки
strsplit(x,split) — разбивает строку х на подстроки в соответствии с split
grep(pattern,x) (а также grepl, regexpr, gregexpr, regexec) — поиск по регулярному выражению
gsub(pattern,replacement,x) (а также sub) — замена по регулярному выражению
tolower(x) — привести строку к нижнему регистру
toupper(x) — привести строку к верхнему регистру
match(x,table), x %in% table — выполняет поиск элементов в векторе table, которые совпадают со значениями из вектора х
pmatch(x,table) — выполняет поиск элементов в векторе table, которые частично совпадают с элементами вектора х
nchar(x) — возвращает количество знаков в строке х
Дата и время
as.Date(s) — конвертирует вектор s в объект класса Date
as.POSIXct(s) — конвертирует вектор s в объект класса POSIXct
Рисование графиков
plot(x) — график x
plot(x, y) — график зависимости y от x
hist(x) — гистограмма
barplot(x) — столбчатая диаграмма
dotchart(x) — диаграмма Кливленда
pie(x) — круговая диаграмма
boxplot(x) — график типа "коробочки с усами"
sunflowerplot(x, y) — то же, что и plot(), однако точки с одинаковыми координатами изображаются в виде "ромашек", количество лепестков у которых пропорционально количеству таких точек
coplot(x˜y | z) — график зависимости y от x для каждого интервала значений z
interaction.plot(f1, f2, y) — если f1 и f2 — факторы, эта фукнция создаст график со средними значениями y в соответствии со значениями f1 (по оси х) и f2 (по оси у, разные кривые)
matplot(x, y) — график зависимости столбцов y от столбцов x
fourfoldplot(x) — изображает (в виде частей окружности) связь между двумя бинарными переменными в разных совокупностях
assocplot(x) — график Кохена-Френдли
mosaicplot(x) — мозаичный график остатков лог-линейной регрессии
pairs(x) — если х - матрица или таблица данных, эта функция изобразит диаграммы рассеяния для всех возможных пар переменных из х
plot.ts(x), ts.plot(x) — изображает временной ряд
qqnorm(x) — квантили
qqplot(x, y) — график зависимости квантилей y от квантилей х
contour(x, y, z) — выполняет интерполяцию данных и создает контурный график
filled.contour(x, y, z) — то же, что contour(), но заполняет области между контурами определёнными цветами
image(x, y, z) — изображает исходные данные в виде квадратов, цвет которых определяется значениями х и у
persp(x, y, z) — то же, что и image(), но в виде трехмерного графика
stars(x) — если x — матрица или таблица данных, изображает график в виде "звезд" так, что каждая строка представлена "звездой", а столбцы задают длину сегментов этих "звезд"
symbols(x, y, ...) — изображает различные символы в соответствии с координатами
termplot(mod.obj) — зображает частные эффекты переменных из регрессионной модели
Рисование графиков на низком уровне
points(x, y) — рисование точек
lines(x, y) — рисование линии
text(x, y, labels, ...) — добавление текстовой надписи
mtext(text, side=3, line=0, ...) — добавление текстовой надписи
segments(x0, y0, x1, y1) — рисование отрезка
arrows(x0, y0, x1, y1, angle= 30, code=2) — рисование стрелочки
abline(a,b) — рисование наклонной прямой
abline(h=y) — рисование вертикальной прямой
abline(v=x) — рисование горизонтальной прямой
abline(lm.obj) — рисование регрессионной прямой
rect(x1, y1, x2, y2) — рисование прямоугольника
polygon(x, y) — рисование многоугольника
legend(x, y, legend) — добавление легенды
title() — добавление заголовка
axis(side, vect) — добавление осей
rug(x) — рисование засечек на оси X
locator(n, type = "n", ...) — возвращает координаты на графике, в которые кликнул пользователь
Lattice-графика
xyplot(y˜x) — график зависимости у от х
barchart(y˜x) — столбчатая диаграмма
dotplot(y˜x) — диаграмма Кливленда
densityplot(˜x) — график плотности распределения значений х
histogram(˜x) — гистограмма значений х
bwplot(y˜x) — график типа "коробочки с усами"
qqmath(˜x) — аналог функции qqnorm()
stripplot(y˜x) — аналог функции stripplot(x)
qq(y˜x) — изображает квантили распределений х и у для визуального сравнения этих распределений; переменная х должна быть числовой, переменная у - числовой, текстовой, или фактором с двумя уровнями
splom(˜x) — матрица диаграмм рассеяния (аналог функции pairs())
levelplot(z˜xy|g1g2) — цветной график значений z, координаты которых заданы переменными х и у (очевидно, что x, y и z должны иметь одинаковую длину); g1, g2... (если присутствуют) — факторы или числовые переменные, чьи значения автоматически разбиваются на равномерные отрезки
wireframe(z˜xy|g1g2) — функция для построения трехмерных диаграмм рассеяния и плоскостей; z, x и у - числовые векторы; g1, g2... (если присутствуют) - факторы или числовые переменные, чьи значения автоматически разбиваются на равномерные отрезки
cloud(z˜xy|g1g2) — трёхмерная диаграмма рассеяния
Оптимизация и подбор параметров
optim(par, fn, method = ) — оптимизация общего назначения
nlm(f,p) — минимизация функции f алгоритмом Ньютона
lm(formula) — подгонка линейной модели
glm(formula,family=) — подгонка обобщённой линейной модели
nls(formula) — нелинейный метод наименьших квадратов
approx(x,y=) — линейная интерполяция
spline(x,y=) — интерполяция кубическими сплайнами
loess(formula) — подгонка полиномиальной поверхности
predict(fit,...) — построение прогнозов
coef(fit) — расчётные коэффициенты
Статистика
sd(x) — стандартное отклонение
var(x) — дисперсия
cor(x) — корреляционная матрица
var(x, y) — ковариация между x и y
cor(x, y) — линейная корреляция между x и y
aov(formula) — дисперсионный анализ
anova(fit,...) — дисперсионный анализ для подогнанных моделей fit
density(x) — ядерные плотности вероятностей
binom.test() — точный тест простой гипотезы о вероятности успеха в испытаниях Бернулли
pairwise.t.test() — попарные сравнения нескольки независимых или зависимых выборок
prop.test() — проверка гипотезы о том, что частоты какого-либо признака равны во всех анализируемых группах
t.test() — тест Стьюдента
Распределения
rnorm(n, mean=0, sd=1) — нормальное распределение
rexp(n, rate=1) — экспоненциальное распределение
rgamma(n, shape, scale=1) — гамма-распределение
rpois(n, lambda) — распределение Пуассона
rweibull(n, shape, scale=1) — распределение Вейбулла
rcauchy(n, location=0, scale=1) — распределение Коши
rbeta(n, shape1, shape2) — бета-распределение
rt(n, df) — распределение Стьюдента
rf(n, df1, df2) — распределение Фишера
rchisq(n, df) — распределение Пирсона
rbinom(n, size, prob) — биномиальное распределение
rgeom(n, prob) — геометрическое распределение
rhyper(nn, m, n, k) — гипергеометрическое распределение
rlogis(n, location=0, scale=1) — логистическое распределение
rlnorm(n, meanlog=0, sdlog=1) — логнормальное распределение
rnbinom(n, size, prob) — отрицательное биномиальное распределение
runif(n, min=0, max=1) — равномерное распределение
Программирование
Работа с функциями:
function(arglist) { expr } — создание пользовательской функции
return(value) — возвращение значения
do.call(funname, args) — вызывает функцию по имени
Условные операторы:
if(cond) expr
if(cond) cons.expr else alt.expr
ifelse(test, yes, no)
Циклы:
for(var in seq) expr
while(cond) expr
repeat expr
break — остановка цикла
№ 1 Лабораторная работа
> FIO < - c("Assylbekova.M.C","Armiyanova.E.G ","Kengessova.A.D","Kydyrbekova.L.S","Aidyn.D","Toktaganova.Zh","Nurkabdenov.D")
> FIO
[1] "Assylbekova.M.C" "Armiyanova.E.G " "Kengessova.A.D" "Kydyrbekova.L.S"
[5] "Aidyn.D" "Toktaganova.Zh" "Nurkabdenov.D"
> AGE <- sample(2,7, replace = T)+17
> AGE
[1] 18 18 18 19 18 19 19
> AGE <- c (19,18,18,18,20,20,18)
> AGE
[1] 19 18 18 18 20 20 18
> HEIGHT <- c (160,175,152,162,174,150,175)
> HEIGHT
[1] 160 175 152 162 174 150 175
> df <- cbind (FIO, AGE, HEIGHT)
> df
FIO AGE HEIGHT
[1,] "Assylbekova.M.C" "19" "160"
[2,] "Armiyanova.E.G " "18" "175"
[3,] "Kengessova.A.D" "18" "152"
[4,] "Kydyrbekova.L.S" "18" "162"
[5,] "Aidyn.D" "20" "174"
[6,] "Toktaganova.Zh" "20" "150"
[7,] "Nurkabdenov.D" "18" "175"
> dd <- data.frame (FIO, AGE , HEIGHT)
> dd
FIO AGE HEIGHT
1 Assylbekova.M.C 19 160
2 Armiyanova.E.G 18 175
3 Kengessova.A.D 18 152
4 Kydyrbekova.L.S 18 162
5 Aidyn.D 20 174
6 Toktaganova.Zh 20 150
7 Nurkabdenov.D 18 175
> save.image("C:\\Users\\Molya\\Documents\\spisok gruppy")
> Weight <- c (45,65,50,55,60,45,60)
> Weight
[1] 45 65 50 55 60 45 60
> dd <- cbind (Weight)
> dd
Weight
[1,] 45
[2,] 65
[3,] 50
[4,] 55
[5,] 60
[6,] 45
[7,] 60
> dd <- data.frame (FIO, AGE , HEIGHT)
> dd
FIO AGE HEIGHT
1 Assylbekova.M.C 19 160
2 Armiyanova.E.G 18 175
3 Kengessova.A.D 18 152
4 Kydyrbekova.L.S 18 162
5 Aidyn.D 20 174
6 Toktaganova.Zh 20 150
7 Nurkabdenov.D 18 175
> dd <- cbind (dd, Weight)
> dd
FIO AGE HEIGHT Weight
1 Assylbekova.M.C 19 160 45
2 Armiyanova.E.G 18 175 65
3 Kengessova.A.D 18 152 50
4 Kydyrbekova.L.S 18 162 55
5 Aidyn.D 20 174 60
6 Toktaganova.Zh 20 150 45
7 Nurkabdenov.D 18 175 60
> mean (dd$AGE )
[1] 18.71429
> mean (dd$HEIGHT)
[1] 164
> mean (dd$Weight)
[1] 54.28571
> max(dd$AGE )
[1] 20
> min (dd$AGE)
[1] 18
> var (dd$Weight)
[1] 61.90476
>nrow(FIO)
>ncol(dd)
> save.image("C:\\Users\\Molya\\Documents\\sps")
№ 2 Лабораторная работа
Создала таблицу в эксель потом сохранила с расширением csv (MS DOS).
Открыла эту таблицу на языке R
m <-read.csv2 (“C:/R/labor 2”)
Управляющие параметры функции PLOT()
Функция plot() имеет большое количество управляющих параметров, которые позволяют осуществлять очень тонкую настройку внешнего вида графика.
Plot (m$AGE
m$HEIGHT) (Строем график)
Plot (m$AGE
m$HEIGHT, col= “green”) потом задала красный цвет
Параметр type
Параметр type позволяет изменять внешний вид точек на графике. Он принимает одно из следующих текстовых значений:
"p" - точки (points; используется по умолчанию)
"l" - линии (lines)
"b" - изображаются и точки, и линии (both points and lines)
"o" - точки изображаются поверх линий (points over lines)
"h" - гистограмма (histogram)
"s" - ступенчатая кривая (steps)
"n" - данные не отображаются (no points)
plot (m$AGE
m$HEIGHT, col="green", type="o") изменила тип на о
Помощь
help(topic), ?topic — справка про topic
help.search("pattern"), ??pattern — глобальный поиск pattern
help(package = ) — справка о заданном пакете
help.start() — запустить помощь в браузере
apropos(what) — имена объектов, которые соответствуют what
args(name) — аргументы команды name
example(topic) — примеры использования topic
Текущее окружение
ls() — список всех объектов
rm(x) — удалить объект
dir() — показать все файлы в текущей директории
getwd() — получить текущую директорию
setwd(dir) — поменять текущую директорию на dir
Общая работа с объектами
str(object) — внутренняя структура объекта object
summary(object) — общая информация об объекте object
dput(x) — получить представление объекта в R-синтаксисе
head(x) — посмотреть начальные строки объекта
tail(x) — посмотреть последние строки объекта
Ввод и вывод
library(package) — подключить пакет package
save(file, ...) — сохраняет указанные объекты в двочином XDR-формате, который не зависит от платформы
load() — загружает данные, сохранённые ранее с помощью команды save()
read.table — считывает таблицу данных и создаёт по ним data.frame
write.table — печатает объект, конвертируя его в data.frame
read.csv — считывает csv-файл
read.delim — считывание данных, разделённых знаками табуляции
save.image — сохраняет все объекты в файл
cat(..., file= , sep= ) — сохраняет аргументы, конкатенируя их через sep
sink(file) — выводит результаты выполнения других команд в файл в режиме реального времени до момента вызова этой же команды без аргументов
Создание объектов
from:to — генерирует последовательность чисел от from до to с шагом 1, например 1:3
с(...) — объединяет аргументы в вектор, например c(1, 2, 3)
seq(from, to, by = ) — генерирует последовательность числел от from до to с шагом by
seq(from, to, len = ) — генерирует последовательность числел от from до to длины len
rep(x, times) — повторяет x ровно times раз
list(...) — создаёт список объектов
data.frame(...) — создаёт фрейм данных
array(data, dims) — создаёт из data многомерные массив размерностей dim
matrix(data, nrow = , ncol = , byrow = ) — создаёт из data матрицу nrow на ncol, порядок заполнения определяется byrow
factor(x, levels = ) — создаёт из x фактор с уровнями levels
gl(n, k, length = n*k, labels = 1:n) — создаёт фактор из n уровней, каждый из которых повторяется k раз длины length с именами labels
rbind(...) — объединяет аргументы по строкам
cbind(...) — объединяет аргументы по столбцам
Индексирование
Векторы
x[n]
n-ый элемент
x[-n]
все элементы, кроме n-го
x[1:n]
первые n элементов
x[-(1:n)]
все элементы, кроме первых n
x[c(1,4,2)]
элементы с заданными индексами
x["name"]
элемент с заданным именем
x[x > 3]
все элементы, большие 3
x[x > 3 & x < 5]
все элементы между 3 и 5
x[x %in% c("a","and","the")]
все элементы из заданного множества
Списки
x[n]
список, состоящий из элемента n
x[[n]]
n-ый элемент списка
x[["name"]]
элемент списка с именем name
x$name
элемент списка с именем name
Матрицы
x[i, j]
элемент на пересечении i-ой строки и j-го столбца
x[i,]
i-ая строка
x[,j]
j-ый столбец
x[,c(1,3)]
заданное подмножество столбцов
x["name", ]
строка с именем name
Фреймы
x[["name"]]
столбец с именем name
x$name
столбец с именем name
Работа с переменными
as.array(x), as.data.frame(x), as.numeric(x), as.logical(x), as.complex(x), as.character(x) — преобразование переменной к заданному типу is.na(x), is.null(x), is.array(x), is.data.frame(x), is.numeric(x), is.complex(x), is.character(x) — проверка на то, что данный объект обладает указанным типом
length(x) — число элементов в x
dim(x) — размерности объекта x
dimnames(x) — имена размерностей объекта x
names(x) — имена объекта x
nrow(x) — число строк x
ncol(x) — число столбцов x
class(x) — класс объекта x
unclass(x) — удаляет атрибут класса у объекта x
attr(x,which) — атрибут which объекта x
attributes(obj) — список атрибутов объекта obj
Манипуляция данными
which.max(x) — индекс элемента с максимальным значением
which.min(x) — индекс элемента с минимальным значением
rev(x) — реверсирует порядок элементов
sort(x) — сортирует элементы объекта по возрастанию
cut(x,breaks) — делит вектор на равные интервалы
match(x, y) — ищет элементы x, которые есть в y
which(x == a) — возвращает порядковые элементы x, которые равны a
na.omit(x) — исключает отсутствующие значения объекта
na.fail(x) — бросает исключение, если объект содержит отсутствующие значения
unique(x) — исключает из объекта повторяющиеся элементы
table(x) — создаёт таблицу с количеством повторений каждого уникального элемента
subset(x, ...) — возвращает подмножество элемента, которое соответствует заданному условию
sample(x, size) — возвращает случайный набор размера size из элементов x
replace(x, list, values) — заменяет значения x c индексами из list значениями из values
append(x, values) — добавляет элементы values в вектор x
Математика
sin(x), cos(x), tan(x), asin(x), acos(x), atan(x), atan2(y, x), log(x), log(x, base), log10(x), exp(x) — элементарные математические функции
min(x), max(x) — минимальный и максимальный элементы объекта
range(x) — вектор из минимального и максимального элемента объекта
pmin(x, y), pmax(x, y) — возвращают вектор с минимальными (максимальными) для каждой пары x[i], y[i]
sum(x) — сумма элементов объекта
prod(x) — произведение элементов объекта
diff(x) — возвращает вектор из разниц между соседними элементами
mean(x) — среднее арифметическое элементов объекта
median(x) — медиана (средний элемент) объекта
weighted.mean(x, w) — средневзвешенное объекта x (w определяет веса)
round(x, n) — округляет x до n знаков после запятой
cumsum(x), cumprod(x), cummin(x), cummax(x) — кумулятивные суммы, произведения, минимумы и максимумы вектора x (i-ый элемент содержит статистику по элементам x[1:i])
union(x, y), intersect(x, y), setdiff(x,y), setequal(x,y), is.element(el,set) — операции над множествами: объединение, пересечение, разность, сравнение, принадлежность
Re(x), Im(x), Mod(x), Arg(x), Conj(x) — операции над комплексными числами: целая часть, мнимая часть, модуль, аргумент, сопряжённое число
fft(x), mvfft(x) — быстрое преобразование Фурье
choose(n, k) — количество сочетаний
rank(x) — ранжирует элементы объекта
Матрицы
%*% — матричное умножение
t(x) — транспонированная матрица
diag(x) — диагональ матрицы
solve(a, b) — решает систему уравнений a %*% x = b
solve(a) — обратная матрица
colSums, rowSums, colMeans, rowMeans — суммы и средние по столбцам и по строкам
Обработка данных
apply(X,INDEX,FUN=) — возвращает вектор, массив или список значений, полученных путем применения функции FUN к определенным элементам массива или матрицы x; подлежащие обработке элементы х указываются при помощи аргумента MARGIN;
lapply(X,FUN) — возвращает список той же длины, что и х; при этом значения в новом списке будут результатом применения функции FUN к элементам исходного объекта х
tapply(X,INDEX,FUN=) — применяет функцию FUN к каждой совокупности значений х, созданной в соответствии с уровнями определенного фактора; перечень факторов указывается при помощи аргумента INDEX
by(data,INDEX,FUN) — аналог tapply(), применяемый к таблицам данных
merge(a,b) — объединяет две таблицы данных (а и b) по общим столбцами или строкам
aggregate(x,by,FUN) — разбивает таблицу данных х на отдельные наборы данных, применяет к этим наборам определенную функцию FUN и возвращает результат в удобном для чтения формате
stack(x, ...) — преобразует данные, представленные в объекте х в виде отдельных столбцов, в таблицу данных
unstack(x, ...) — выполняет операцию, обратную действию функции stack()
reshape(x, ...) — преобразует таблицу данных из «широкого формата» (повторные измерения какой-либо величины записаны в отдельных столбцах таблицы) в таблицу "узкого формата" (повторные измерения идут одно под одним в пределах одного столбца)
Строки
print(x) — выводит на экран x
sprintf(fmt, ...) — форматирование текста в C-style (можно использовать %s, %.5f и т.п.)
format(x) — форматирует объект x так, чтобы он выглядел красиво при выводе на экран
paste(...) — конвертирует векторы в текстовые переменные и объединяет их в одно текстовое выражение
substr(x,start,stop) — получение подстроки
strsplit(x,split) — разбивает строку х на подстроки в соответствии с split
grep(pattern,x) (а также grepl, regexpr, gregexpr, regexec) — поиск по регулярному выражению
gsub(pattern,replacement,x) (а также sub) — замена по регулярному выражению
tolower(x) — привести строку к нижнему регистру
toupper(x) — привести строку к верхнему регистру
match(x,table), x %in% table — выполняет поиск элементов в векторе table, которые совпадают со значениями из вектора х
pmatch(x,table) — выполняет поиск элементов в векторе table, которые частично совпадают с элементами вектора х
nchar(x) — возвращает количество знаков в строке х
Дата и время
as.Date(s) — конвертирует вектор s в объект класса Date
as.POSIXct(s) — конвертирует вектор s в объект класса POSIXct
Рисование графиков
plot(x) — график x
plot(x, y) — график зависимости y от x
hist(x) — гистограмма
barplot(x) — столбчатая диаграмма
dotchart(x) — диаграмма Кливленда
pie(x) — круговая диаграмма
boxplot(x) — график типа "коробочки с усами"
sunflowerplot(x, y) — то же, что и plot(), однако точки с одинаковыми координатами изображаются в виде "ромашек", количество лепестков у которых пропорционально количеству таких точек
coplot(x˜y | z) — график зависимости y от x для каждого интервала значений z
interaction.plot(f1, f2, y) — если f1 и f2 — факторы, эта фукнция создаст график со средними значениями y в соответствии со значениями f1 (по оси х) и f2 (по оси у, разные кривые)
matplot(x, y) — график зависимости столбцов y от столбцов x
fourfoldplot(x) — изображает (в виде частей окружности) связь между двумя бинарными переменными в разных совокупностях
assocplot(x) — график Кохена-Френдли
mosaicplot(x) — мозаичный график остатков лог-линейной регрессии
pairs(x) — если х - матрица или таблица данных, эта функция изобразит диаграммы рассеяния для всех возможных пар переменных из х
plot.ts(x), ts.plot(x) — изображает временной ряд
qqnorm(x) — квантили
qqplot(x, y) — график зависимости квантилей y от квантилей х
contour(x, y, z) — выполняет интерполяцию данных и создает контурный график
filled.contour(x, y, z) — то же, что contour(), но заполняет области между контурами определёнными цветами
image(x, y, z) — изображает исходные данные в виде квадратов, цвет которых определяется значениями х и у
persp(x, y, z) — то же, что и image(), но в виде трехмерного графика
stars(x) — если x — матрица или таблица данных, изображает график в виде "звезд" так, что каждая строка представлена "звездой", а столбцы задают длину сегментов этих "звезд"
symbols(x, y, ...) — изображает различные символы в соответствии с координатами
termplot(mod.obj) — зображает частные эффекты переменных из регрессионной модели
Рисование графиков на низком уровне
points(x, y) — рисование точек
lines(x, y) — рисование линии
text(x, y, labels, ...) — добавление текстовой надписи
mtext(text, side=3, line=0, ...) — добавление текстовой надписи
segments(x0, y0, x1, y1) — рисование отрезка
arrows(x0, y0, x1, y1, angle= 30, code=2) — рисование стрелочки
abline(a,b) — рисование наклонной прямой
abline(h=y) — рисование вертикальной прямой
abline(v=x) — рисование горизонтальной прямой
abline(lm.obj) — рисование регрессионной прямой
rect(x1, y1, x2, y2) — рисование прямоугольника
polygon(x, y) — рисование многоугольника
legend(x, y, legend) — добавление легенды
title() — добавление заголовка
axis(side, vect) — добавление осей
rug(x) — рисование засечек на оси X
locator(n, type = "n", ...) — возвращает координаты на графике, в которые кликнул пользователь
Lattice-графика
xyplot(y˜x) — график зависимости у от х
barchart(y˜x) — столбчатая диаграмма
dotplot(y˜x) — диаграмма Кливленда
densityplot(˜x) — график плотности распределения значений х
histogram(˜x) — гистограмма значений х
bwplot(y˜x) — график типа "коробочки с усами"
qqmath(˜x) — аналог функции qqnorm()
stripplot(y˜x) — аналог функции stripplot(x)
qq(y˜x) — изображает квантили распределений х и у для визуального сравнения этих распределений; переменная х должна быть числовой, переменная у - числовой, текстовой, или фактором с двумя уровнями
splom(˜x) — матрица диаграмм рассеяния (аналог функции pairs())
levelplot(z˜xy|g1g2) — цветной график значений z, координаты которых заданы переменными х и у (очевидно, что x, y и z должны иметь одинаковую длину); g1, g2... (если присутствуют) — факторы или числовые переменные, чьи значения автоматически разбиваются на равномерные отрезки
wireframe(z˜xy|g1g2) — функция для построения трехмерных диаграмм рассеяния и плоскостей; z, x и у - числовые векторы; g1, g2... (если присутствуют) - факторы или числовые переменные, чьи значения автоматически разбиваются на равномерные отрезки
cloud(z˜xy|g1g2) — трёхмерная диаграмма рассеяния
Оптимизация и подбор параметров
optim(par, fn, method = ) — оптимизация общего назначения
nlm(f,p) — минимизация функции f алгоритмом Ньютона
lm(formula) — подгонка линейной модели
glm(formula,family=) — подгонка обобщённой линейной модели
nls(formula) — нелинейный метод наименьших квадратов
approx(x,y=) — линейная интерполяция
spline(x,y=) — интерполяция кубическими сплайнами
loess(formula) — подгонка полиномиальной поверхности
predict(fit,...) — построение прогнозов
coef(fit) — расчётные коэффициенты
Статистика
sd(x) — стандартное отклонение
var(x) — дисперсия
cor(x) — корреляционная матрица
var(x, y) — ковариация между x и y
cor(x, y) — линейная корреляция между x и y
aov(formula) — дисперсионный анализ
anova(fit,...) — дисперсионный анализ для подогнанных моделей fit
density(x) — ядерные плотности вероятностей
binom.test() — точный тест простой гипотезы о вероятности успеха в испытаниях Бернулли
pairwise.t.test() — попарные сравнения нескольки независимых или зависимых выборок
prop.test() — проверка гипотезы о том, что частоты какого-либо признака равны во всех анализируемых группах
t.test() — тест Стьюдента
Распределения
rnorm(n, mean=0, sd=1) — нормальное распределение
rexp(n, rate=1) — экспоненциальное распределение
rgamma(n, shape, scale=1) — гамма-распределение
rpois(n, lambda) — распределение Пуассона
rweibull(n, shape, scale=1) — распределение Вейбулла
rcauchy(n, location=0, scale=1) — распределение Коши
rbeta(n, shape1, shape2) — бета-распределение
rt(n, df) — распределение Стьюдента
rf(n, df1, df2) — распределение Фишера
rchisq(n, df) — распределение Пирсона
rbinom(n, size, prob) — биномиальное распределение
rgeom(n, prob) — геометрическое распределение
rhyper(nn, m, n, k) — гипергеометрическое распределение
rlogis(n, location=0, scale=1) — логистическое распределение
rlnorm(n, meanlog=0, sdlog=1) — логнормальное распределение
rnbinom(n, size, prob) — отрицательное биномиальное распределение
runif(n, min=0, max=1) — равномерное распределение
Программирование
Работа с функциями:
function(arglist) { expr } — создание пользовательской функции
return(value) — возвращение значения
do.call(funname, args) — вызывает функцию по имени
Условные операторы:
if(cond) expr
if(cond) cons.expr else alt.expr
ifelse(test, yes, no)
Циклы:
for(var in seq) expr
while(cond) expr
repeat expr
break — остановка цикла
№ 1 Лабораторная работа
> FIO < - c("Assylbekova.M.C","Armiyanova.E.G ","Kengessova.A.D","Kydyrbekova.L.S","Aidyn.D","Toktaganova.Zh","Nurkabdenov.D")
> FIO
[1] "Assylbekova.M.C" "Armiyanova.E.G " "Kengessova.A.D" "Kydyrbekova.L.S"
[5] "Aidyn.D" "Toktaganova.Zh" "Nurkabdenov.D"
> AGE <- sample(2,7, replace = T)+17
> AGE
[1] 18 18 18 19 18 19 19
> AGE <- c (19,18,18,18,20,20,18)
> AGE
[1] 19 18 18 18 20 20 18
> HEIGHT <- c (160,175,152,162,174,150,175)
> HEIGHT
[1] 160 175 152 162 174 150 175
> df <- cbind (FIO, AGE, HEIGHT)
> df
FIO AGE HEIGHT
[1,] "Assylbekova.M.C" "19" "160"
[2,] "Armiyanova.E.G " "18" "175"
[3,] "Kengessova.A.D" "18" "152"
[4,] "Kydyrbekova.L.S" "18" "162"
[5,] "Aidyn.D" "20" "174"
[6,] "Toktaganova.Zh" "20" "150"
[7,] "Nurkabdenov.D" "18" "175"
> dd <- data.frame (FIO, AGE , HEIGHT)
> dd
FIO AGE HEIGHT
1 Assylbekova.M.C 19 160
2 Armiyanova.E.G 18 175
3 Kengessova.A.D 18 152
4 Kydyrbekova.L.S 18 162
5 Aidyn.D 20 174
6 Toktaganova.Zh 20 150
7 Nurkabdenov.D 18 175
> save.image("C:\\Users\\Molya\\Documents\\spisok gruppy")
> Weight <- c (45,65,50,55,60,45,60)
> Weight
[1] 45 65 50 55 60 45 60
> dd <- cbind (Weight)
> dd
Weight
[1,] 45
[2,] 65
[3,] 50
[4,] 55
[5,] 60
[6,] 45
[7,] 60
> dd <- data.frame (FIO, AGE , HEIGHT)
> dd
FIO AGE HEIGHT
1 Assylbekova.M.C 19 160
2 Armiyanova.E.G 18 175
3 Kengessova.A.D 18 152
4 Kydyrbekova.L.S 18 162
5 Aidyn.D 20 174
6 Toktaganova.Zh 20 150
7 Nurkabdenov.D 18 175
> dd <- cbind (dd, Weight)
> dd
FIO AGE HEIGHT Weight
1 Assylbekova.M.C 19 160 45
2 Armiyanova.E.G 18 175 65
3 Kengessova.A.D 18 152 50
4 Kydyrbekova.L.S 18 162 55
5 Aidyn.D 20 174 60
6 Toktaganova.Zh 20 150 45
7 Nurkabdenov.D 18 175 60
> mean (dd$AGE )
[1] 18.71429
> mean (dd$HEIGHT)
[1] 164
> mean (dd$Weight)
[1] 54.28571
> max(dd$AGE )
[1] 20
> min (dd$AGE)
[1] 18
> var (dd$Weight)
[1] 61.90476
>nrow(FIO)
>ncol(dd)
> save.image("C:\\Users\\Molya\\Documents\\sps")
№ 2 Лабораторная работа
Создала таблицу в эксель потом сохранила с расширением csv (MS DOS).
Открыла эту таблицу на языке R
m <-read.csv2 (“C:/R/labor 2”)
Управляющие параметры функции PLOT()
Функция plot() имеет большое количество управляющих параметров, которые позволяют осуществлять очень тонкую настройку внешнего вида графика.
Plot (m$AGE
m$HEIGHT) (Строем график) Plot (m$AGE
Параметры xlim и ylim
Эти два параметра контролирут размах значений на каждой из осей графика. По умолчанию они оба принимают значение NULL - в этом случае размах выбирается программой автоматически. Для отмены автоматических настроек соответствующему параметру необходимо присвоить значение в виде числового вектора, содержащего минимальное и максимальное значения, которые должны отображаться на оси.
plot (m$AGE
Параметр main
Аргумент main служит для создания названия графика. По умолчанию название размещается в верхней части рисунка:
plot (m$AGE
Параметр CEX
Управляет размером шрифта и символов; следующие параметры имеют аналогичное
действие в отношении: чисел на координатных осях - cex.axis,меток осей - cex.lab, основного заголовка графика - cex.main, и подзаголовка - cex.sub
я увеличила размер ромбиков до 4 раза больше
plot (m$AGE
fancyRpartPlot (tree)
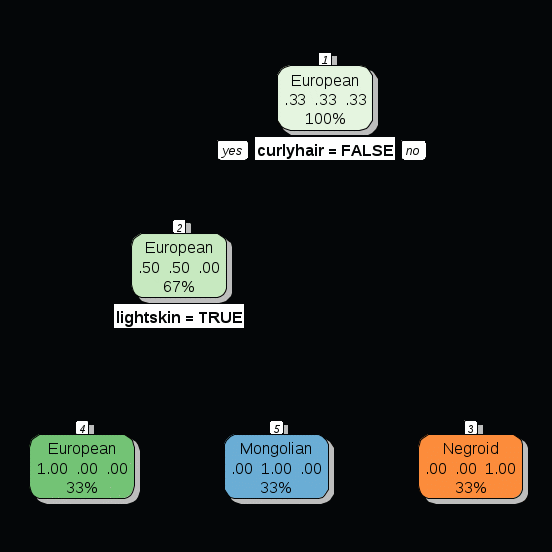
Предсказание
newpeople <- data.frame (names=c ("portugalian","mongo"), curlyhair=c (F,T),lightskin=c(T,F))
newpeople$curlyhair <- as.factor (newpeople$curlyhair)
newpeople$lightskin <- as.factor (newpeople$lightskin)
predict (tree,newpeople, type = "class")
Результат:
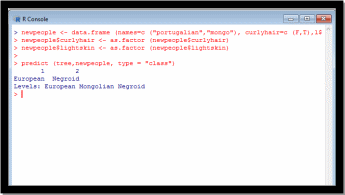
Карта
install.packages ("ggmap")
install.packages ("mapproj")
library(ggmap)
library(mapproj)
map <- get_map(location = 'UAE', zoom = 6)
ggmap(map)
dat <- read.table(text = "
location lat long
Dubai 25.25278 55.36444
Abu-Dabi 24.46667 54.3667
Al-Ain 24.12 55.44
Shardja 25.2100 55.2330
Adjman 25.2358 55.2847
", header = TRUE)
map <- get_map(
location = "UAE" # google search string
, zoom = 4 # larger is closer
, maptype = "watercolor" # map type
)
p <- ggmap(map)
p <- p + geom_point(data = dat, aes(x = long, y = lat, shape = location, colour = location)
, size = 5)
p <- p + geom_text(data = dat, aes(x = long, y = lat, label = location), hjust = -0.2)
# legend positioning, removing grid and axis labeling
p <- p + theme( legend.position = "none" # remove legend
, panel.grid.major = element_blank()
, panel.grid.minor = element_blank()
, axis.text = element_blank()
, axis.title = element_blank()
, axis.ticks = element_blank()
)
p <- p + labs(title = "UAE locations")
print(p)