Файл: Московский технический университет связи и информатики.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 06.02.2024
Просмотров: 14
Скачиваний: 0
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.

Министерство цифрового развития, связи и массовых коммуникаций Российской Федерации
Ордена Трудового Красного Знамени
федеральное государственное бюджетное образовательное учреждение высшего образования
МОСКОВСКИЙ ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ СВЯЗИ И ИНФОРМАТИКИ
Кафедра «Теории вероятности и прикладной математики»
Нечеткая логика
Индивидуальное домашнее задание 1
Построение функции принадлежности методом попарных сравнений
Выполнил(а):
студент(ка) группы
ФИО
Проверила:
ФИО
Москва, 2022
Задание:
-
Выбрать нечеткую переменную. -
Выбрать не менее пяти значений переменной. -
Построить матрицу попарных сравнений. -
Найти функцию принадлежности с использованием упрощенной процедуры Саати. -
Вычислить соотношение согласованности. Значение не должно превышать 10%.
Ход работы:
Выберем нечеткую переменную – способ (вид транспорта), которым гражданин будет добираться из дома до работы.
Выберем пять критериев (пять значений переменных), которые гражданин должен учитывать при выборе вида транспорта (личный автомобиль, автобусы или метро):
-
Удобство: Легко ли добраться до транспортных средств? (Есть ли парковка рядом с квартирами? Находится ли автобусная станция рядом с пунктом назначения? и т.д.) -
Комфорт: Чувствуют ли люди себя комфортно, когда они находятся в транспорте? -
Расходы: Тратят ли люди много денег на транспорт (билеты, топливо и т.д.)? -
Время: Тратят ли транспортные средства впустую / экономят время (низкая скорость, пробки и т. д.)? -
Экология: Оказывают ли транспортные средства какое-либо негативное воздействие на окружающую среду?
Попарные сравнения используются для выявления предпочтений людей по этим пяти критериям, когда они выбирают способы транспортировки.
Форма матрицы попарных сравнений приведена в таблице 1.
Респонденты должны перебирать эти критерии от синих клеток к зеленым клеткам (т.е. является ли элемент в синей ячейке более важным, менее важным или равным элементу в зеленой ячейке). Только оранжевые клетки должны быть заполнены. Белые клетки представляют собой рецептрические значения связанных оранжевых клеток. Серые клетки все пусты, потому что, например, «удобство» не может быть более или менее важным, чем оно само.
В ячейке, помеченной буквой "А" (в таблице 1 ниже), респонденту необходимо будет решить, является ли неудобство более важным, столь же важным или менее важным, чем комфорт. Таким образом, они думают, что удобство немного важнее комфорта, они поставят число, такое как 3 или 4 в ячейке. Однако, если они думают, что удобство немного менее важно, чем комфорт, они будут ставить такие цифры, как 1/3 или 1/4.
Респонденты заполняют оранжевые ячейки, сравнивая важность синего столбца с зеленой строкой, а не наоборот.
Таблица 1
Матрица попарных сравнений
| Критерии | Удобство | Комфорт | Расходы | Время | Экология |
| Удобство | | А | | | |
| Комфорт | | | | | |
| Расходы | | | | | |
| Время | | | | | |
| Экология | | | | | |
Следующим шагом является оценка главного собственного вектора попарной матрицы. Во-первых, мы использовали геометрические средние вычисления для объединения четырех отдельных матриц попарного сравнения
, собранных у четырех респондентов.
То есть элементы в каждой строке в каждой отдельной матрице умножаются друг на друга, и это матрица произведения. Затем берем n-й корень матрицы произведения элементов строки (где n – количество элементов в строке). Далее, разделив их на сумму столбцов, числа нормализуются. Затем, путем дальнейшего вычисления, получим принципиальный собственный вектор попарной матрицы сравнения. Это вектор приоритетов в шкалах соотношений и это всего лишь весовые коэффициенты для критериев (процедура Саати).
Кроме того, подход AHP имеет тест на согласованность. Попарные сравнения считаются достаточно последовательными, если соответствующий коэффициент согласованности (CR) составляет менее 10%.
Во-первых, оценивается индекс согласованности (CI), добавив столбцы в попарную матрицу сравнения и умножив полученный вектор на вектор приоритетов (т.е. аппроксимированный собственный вектор), полученный ранее. Это дает приближение собственного значения Maximum, обозначаемого
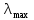 . Затем значение CI вычисляется по формуле: CI = ( - n)/(n - 1), где n – число критериев в матрице.
. Затем значение CI вычисляется по формуле: CI = ( - n)/(n - 1), где n – число критериев в матрице.Затем коэффициент согласованности CR получается путем деления значения CI на индекс случайной согласованности (RI), как указано в таблице 2.
Таблица 2
Ссылочная таблица индекса случайной согласованности
| Количество критериев | РЕ |
| 1 | 0 |
| 2 | 0 |
| 3 | 0,58 |
| 4 | 0,9 |
| 5 | 1,12 |
| 6 | 1,24 |
| 7 | 1,32 |
| 8 | 1,41 |
| 9 | 1,45 |
| 10 | 1,49 |
| 11 | 1,51 |
Все расчеты и результаты приведены в Excel – файле, а также ниже:
| Эксперты | Удобство | Комфорт | Расходы | Время | Экология | ИТОГО | |||||
| Вес | Результат | Вес | Результат | Вес | Результат | Вес | Результат | Вес | Результат | ||
| Респондент №1 | 0,407 | 0,477 | 0,260 | 0,463 | 0,145 | 0,581 | 0,099 | 0,541 | 0,089 | 0,564 | 0,503 |
| Респондент №2 | 0,407 | 0,158 | 0,260 | 0,273 | 0,145 | 0,250 | 0,099 | 0,260 | 0,089 | 0,255 | 0,220 |
| Респондент №3 | 0,407 | 0,233 | 0,260 | 0,169 | 0,145 | 0,125 | 0,099 | 0,140 | 0,089 | 0,131 | 0,182 |
| Респондент №4 | 0,407 | 0,132 | 0,260 | 0,096 | 0,145 | 0,043 | 0,099 | 0,059 | 0,089 | 0,050 | 0,095 |
| Priortization Matrix | Удобство | Комфорт | Расходы | Время | Экология | | Удобство | Комфорт | Расходы | Время | Экология | | |
| Удобство | 1 | 2 | 3 | 7 | 2 | | 0,4038 | 0,4762 | 0,4286 | 0,56 | 0,1667 | | 0,407 |
| Комфорт | 0,5 | 1 | 2 | 2 | 5 | | 0,2019 | 0,2381 | 0,2857 | 0,16 | 0,4167 | | 0,260 |
| Расходы | 0,3333 | 0,5 | 1 | 2 | 2 | | 0,1346 | 0,119 | 0,1429 | 0,16 | 0,1667 | | 0,145 |
| Время | 0,1429 | 0,5 | 0,5 | 1 | 2 | | 0,0577 | 0,119 | 0,0714 | 0,08 | 0,1667 | | 0,099 |
| Экология | 0,5 | 0,2 | 0,5 | 0,5 | 1 | | 0,2019 | 0,0476 | 0,0714 | 0,04 | 0,0833 | | 0,089 |
| | 2,4762 | 4,2 | 7 | 12,5 | 12 | | 1,000 | 1,000 | 1,000 | 1,000 | 1,000 | | 1,000 |
| Удобство | Респондент №1 | Респондент №2 | Респондент №3 | Респондент №4 | | | Респондент №1 | Респондент №2 | Респондент №3 | Респондент №4 | | | |
| Респондент №1 | 1 | 3 | 5 | 2 | | | 0,4918 | 0,4 | 0,7317 | 0,2857 | | | 0,477 |
| Респондент №2 | 0,3333 | 1 | 0,3333 | 2 | | | 0,1639 | 0,1333 | 0,0488 | 0,2857 | | | 0,158 |
| Респондент №3 | 0,2 | 3 | 1 | 2 | | | 0,0984 | 0,4 | 0,1463 | 0,2857 | | | 0,233 |
| Респондент №4 | 0,5 | 0,5 | 0,5 | 1 | | | 0,2459 | 0,0667 | 0,0732 | 0,1429 | | | 0,132 |
| | 2,0333 | 7,5 | 6,8333 | 7 | | | 1,000 | 1,000 | 1,000 | 1,000 | | | 1,000 |

