Файл: Литература по курсу аос (по всем вопросам должен быть представлен краткий рукописный конспект в общей тетради).docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 08.02.2024
Просмотров: 90
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.

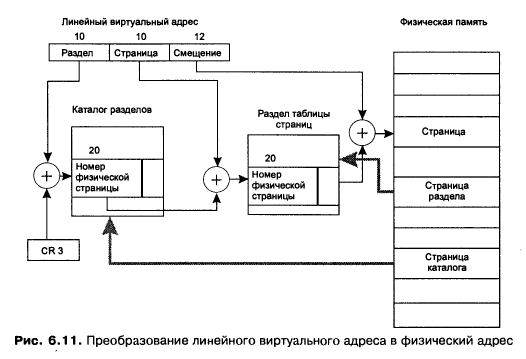
Номер виртуальной страницы (20 разрядов) – делится на номер раздела и номер страницы в разделе. Ну и дальше все преобразуется как описано в страничном механизме.
Трансляция адреса. Буфер ассоциативной трансляции (TLB).
Для ускорения преобразования адресов в блоке управления страницами используется ассоциативная память, где кэшируется 32 дескриптора активно используемых страниц. Это позволяет по номеру витруальной страницы быстро извлекать номер физической страницы без обращения к таблицам разделов и страниц.
Буфер ассоциативной трансляции (англ. Translation lookaside buffer, TLB) — это специализированный кэш центрального процессора, используемый для ускорения трансляции адреса виртуальной памяти в адрес физической памяти. TLB используется всеми современными процессорами с поддержкой страничной организации памяти. TLB содержит фиксированный набор записей (от 8 до 4096) и является ассоциативной памятью. Каждая запись содержит соответствие адреса страницы виртуальной памяти адресу физической памяти. Если адрес отсутствует в TLB, процессор обходит таблицы страниц и сохраняет полученный адрес в TLB, что занимает в 10—60 раз больше времени, чем получение адреса из записи, уже закешированной TLB. Вероятность промаха TLB невысока и составляет в среднем от 0,01 % до 1 %.
В современных процессорах может быть реализовано несколько уровней TLB с разной скоростью работы и размером. Самый верхний уровень TLB будет содержать небольшое количество записей, но будет работать с очень высокой скоростью, вплоть до нескольких тактов. Последующие уровни становятся медленнее, но, вместе с тем и больше.
Иногда верхний уровень TLB разделяется на 2 буфера, один для страниц, содержащих исполняемый код, и другой — для обрабатываемых данных.
-
Иерархия запоминающих устройств и кэширование данных. Принципы работы кэш - памяти. Детерминированный и случайный способы отображения основной памяти на кэш. Проблема согласования данных. Схемы выполнения запросов в схемах с двухуровневой кэш памятью.
Иерархия запоминающих устройств:
Память часто называют «узким местом» фон-Неймановских ВМ из-за ее серьезного отставания по быстродействию от процессоров, причем, разрыв этот неуклонно увеличивается.
Так, если производительность процессоров возрастает вдвое примерно каждые 1,5 года, то для микросхем памяти прирост быстродействия не превышает 9% в год (удвоение за 10 лет), что выражается в увеличении разрыва в быстродействии между процессором и памятью приблизительна на 50% в год.
При создании системы памяти постоянно приходится решать задачу обеспечения требуемой емкости и высокого быстродействия за приемлемую цену. Наиболее эффективным решением является создание иерархической памяти. Иерархическая память состоит из ЗУ различных типов (см. рисунок ниже), которые, в зависимости от характеристик, относят к определенному уровню иерархии.
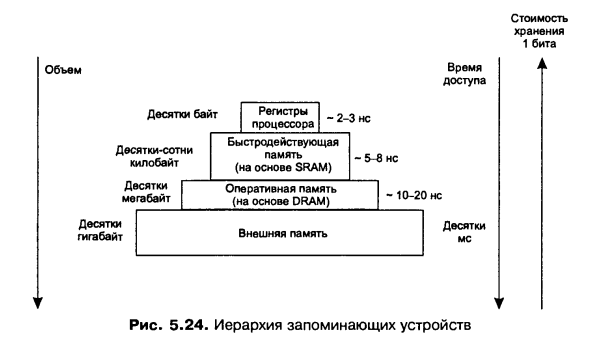
Более высокий уровень меньше по емкости, быстрее и имеет большую стоимость в пересчете на бит, чем более низкий уровень. Уровни иерархии взаимосвязаны: все данные на одном уровне могут быть также найдены на более низком уровне, и все данные на этом более низком уровне могут быть найдены на следующем нижележащем уровне и т. д.
Фундамент пирамиды – внешняя память (жесткий и гибкий магнитный диск, магнитные ленты, оптические диски, флэшки):
-
Объем – десятки и сотни гигабайт -
Время доступа – десятки миллисекунд
Оперативная память:
-
Объем – гигабайты -
Время доступа – 10-20 наносекунд -
Реализуется на относительно медленной динамической памяти DRAM
Быстродействующая память (ее же называют Кэш??)
-
На основе статической памяти SRAM -
Объем – десятки-сотни килобайт -
Время доступа – до 8 наносек
Регистры процессора
-
Объем – десятки байт -
Время доступа – 2-3 наносекунды (определяется быстродействием процессора)
Кэширование данных
Чем быстрее память, тем она дороже. Но нам хотелось бы быструю и недорогую память. Для этого есть компромиссное решение – кэширование.
Кэширование – это способ совместного функционирования двух типов запоминающих устройств, отличающихся временем доступа и стоимостью хранения данных. При кэшировании за счет копирования наиболее часто использующихся фрагментов информации из медленного ЗУ в быстрое достигается уменьшение времени доступа к данным, но при этом экономится быстродействующая память.
При этом КЭШем называют не только способ организации памяти, но и само быстрое ЗУ, куда производится копирование информации. Более медленное ЗУ называют основной памятью.

Кэширование – универсальный метод, пригодный для ускорения доступа к:
- оперативной памяти – роль КЭШа выполняет быстрая память
- к данным, хранящимся на диске – роль КЭШа выполняют буферы в оперативной памяти
- к другим видам ЗУ.
Виртуальная память по сути – тоже разновидность кэширования, где оперативная память выступает в роли КЭШа по отношению к диску. Правда здесь цель – не ускорение доступа, а увеличение объема и подмена оперативной памяти.
Принципы работы кэш - памяти.
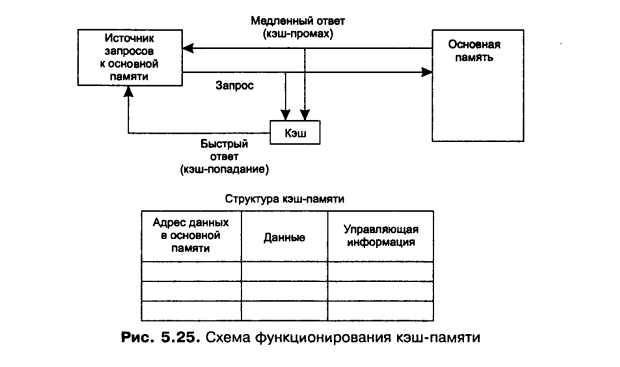
Рассмотрим одну из возможных схем работы кэш-памяти для понимания принципов ее работы:
В кэш памяти содержатся ЗАПИСИ обо всех загруженных в нее элементах.
Каждая запись включает:
-
Данные -
Адрес этих данных в основной памяти -
Дополнительная инфа (признак модификации, признак действительности данных)
Процесс обращается к основной памяти:
-
ОС просматривает содержимое КЭШа, нет ли нужных данных там. -
КЭШ-память не адресуема, поиск идет по адресу данных в оперативной памяти
-
Если данные есть – кэш попадание, данные считываются из КЭШа и передаются запросившему. -
Если данных нет – кэш-промах, ОС идет в основную память и добывает данные оттуда.
При оценке эффективности кэш-памяти обычно используют следующие характеристики:
• коэффициент попаданий (hit rate) — отношение числа обращений к памяти, при которых произошло попадание, к общему числу обращений к ЗУ данного уровня иерархии;
• коэффициент промахов (miss rate) — отношение числа обращений к памяти, при
которых имел место промах; к общему числу обращений к ЗУ данного уровня иерархии;
• время обращения при попадании (hit time) — время, необходимое для поиска
нужной информации в памяти верхнего уровня (включая выяснение, является ли обращение попаданием), плюс время на фактическое считывание данных;
• потери на промах (miss penalty) — время, требуемое для замены блока в памяти более высокого уровня на блок с нужными данными, расположенный в ЗУ следующего (более низкого) уровня. Потери на промах включают в себя:
-
время доступа (access time) — время обращения к первому слову блока при промахе -
время пересылки (transfer time) — дополнительное время для пересылки оставшихся слов блока.
Время доступа обусловлено задержкой памяти более низкого уровня, в то время как время пересылки связано с полосой пропускания канала между ЗУ двух смежных уровней.
От чего зависит эффективность кэширования? От вероятности попаданий в кэш.
Использование кэш-памяти имеет смысл только при высокой вероятности кэш-попаданий, т.к. иначе это только дополнительные расходы времени на поиск в КЭШе.
Вероятность кэш-попаданий зависит от:
- объема КЭШа
- объема кэшируемой памяти
- алгоритма замещения данных в КЭШе
- особенностей выполняемой программы
- времени ее работы
- и тд
Но в большинстве реализаций процент кэш-попаданий высокий, более 90%. Круть.
Это достигается за счет того, что данные обладают свойствами пространственной и временной локальности.
-
Временная локальность – если произошло обращение к какому-то адресу, то с большой вероятностью скоро по нему снова обратятся -
Пространственная локальность – если произошло обращение к какому-то адресу, то скоро произойдет обращение по соседним адресам.
В соответствии с принципом временной локальности, в Кэше сохраняют недавно просмотренные данные, а в соответствии с принципом пространственной локальности, в кэш считывается не один элемент информации, а целый блок данных или целый массив, если идет обработка массива.
Проблема согласования данных.
Существование двух копий данных – в КЭШе и оперативной памяти – порождает проблему согласования данных.
-
Вытеснение данных из КЭШа
-
Если данные не были изменены, то нужно просто сбросить бит действительности -
Если данные были изменены, то нужно скопировать их в основную память
-
Если во время нахождения данных в КЭШе были изменены данные в основной памяти – копия в КЭШе становится недостоверной.
Есть 2 варианта решения проблемы:
-
Сквозная запись – при каждой записи в основную память просматривается кэш. Если элемент найден в КЭШе, переписываются обе копии, если нет – только то, что в основной памяти -
Обратная запись – при каждой записи в основную память просматривается кэш. Если элемент найден в КЭШе, переписывается только копия в КЭШе, если нет – то, что в основной памяти.
В некоторых алгоритмах замещения предусмотрена первоочередная выгрузка модифицированных, грязных данных. Также модифицированные данные могут выгружаться не только, когда нужно освободить кэш, но и в фоновом режиме, когда ОС больше нечем заняться.
Детерминированный и случайный способы отображения основной памяти на кэш.
Работа с КЭШем (алгоритм поиска, алгоритм замещения) напрямую зависит от способа отображения основной памяти на кэш.
Способы бывают разные, но основное требование к отображению – ПРОЗРАЧНОСТЬ. То есть правило отображения основной памяти на кэш не должно зависеть от работы программ и пользователей, должно быть постоянным.
Широко распространены 2 основные схемы отображения:
- случайное
- детерминированное
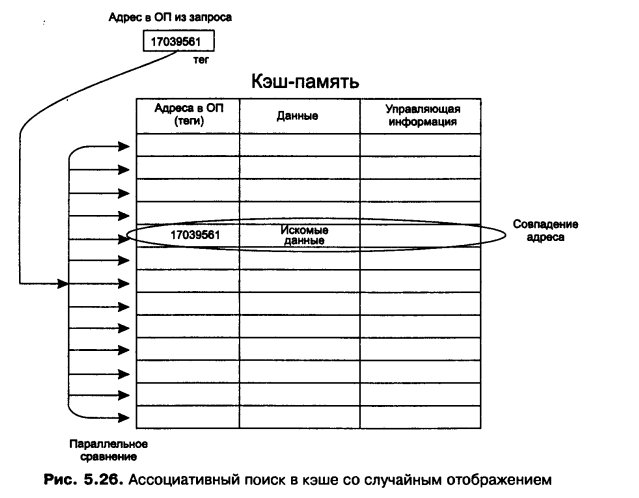
Случайное отображение
Элемент ОП может быть размещен в ЛЮБОМ месте КЭШа.
Данные помещаются вместе в адресом в ОП, и поиск осуществляется по этому адресу.
Схемы поиска:
-
Простой перебор (неэффективно) -
Ассоциативный поиск (сравнение выполняется не последовательно с каждой записью КЭШа, а параллельно, сразу со всеми записями). Признак, по которому идет сравнение, называется ТЭГ. В данном случае – это адрес элемента в оперативной памяти.
Ассоциативный поиск стоит дорого.
Такая память используется только для обеспечения высокого процента попадания достаточно небольшого объема памяти.
Особенности КЭШа со случайным отображением:
-
Вытеснение старых записей осуществляется только когда кэш-память заполнена и больше нет места -
Выбор данных на выгрузку идет среди всех записей КЭШа (по стандартным принципам, как страницы из виртуальной памяти)
Детерминированный способ отображения
Любой элемент кэш памяти отображается в одно и то же место КЭШа.
КЭШ память делится на строки, каждая хранит одну или больше записей из оперативной памяти.
Строки кэш памяти соотносятся с адресами ОП как «один ко многим»
Прямое отображение:
От адреса ОП отделяется несколько разрядов – это будет номер кэш-строки
Ищем по этому номеру – нашли. Но это может быть любой из подходящих элементов.
Чтобы не искать по всем подходящим, а быстро идентифицировать, то или не то нашли, в строке кэш-памяти содержится тэг – старшая ЧАСТЬ АДРЕСА ДАННЫХ в оперативной памяти.
Если тэг совпал с такой же частью из запроса – попадание.
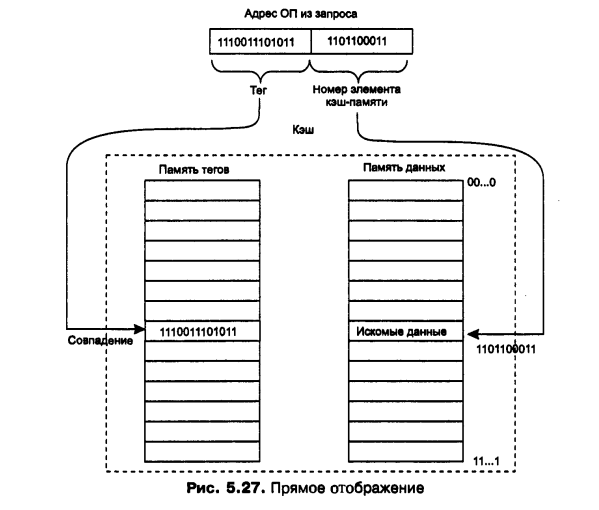
Особенности:
-
Вытеснение данных – не только при отсутствии свободного места -
Нет никакого выбора на замещение -
Низкая стоимость