Файл: Операции, производимые с данными (Понятия информации).pdf
Добавлен: 13.03.2024
Просмотров: 31
Скачиваний: 0

Рисунок 2.2. Технологии доступа при выполнении действий добавления элемента
Технология удаления изображена на рис. 2.3.
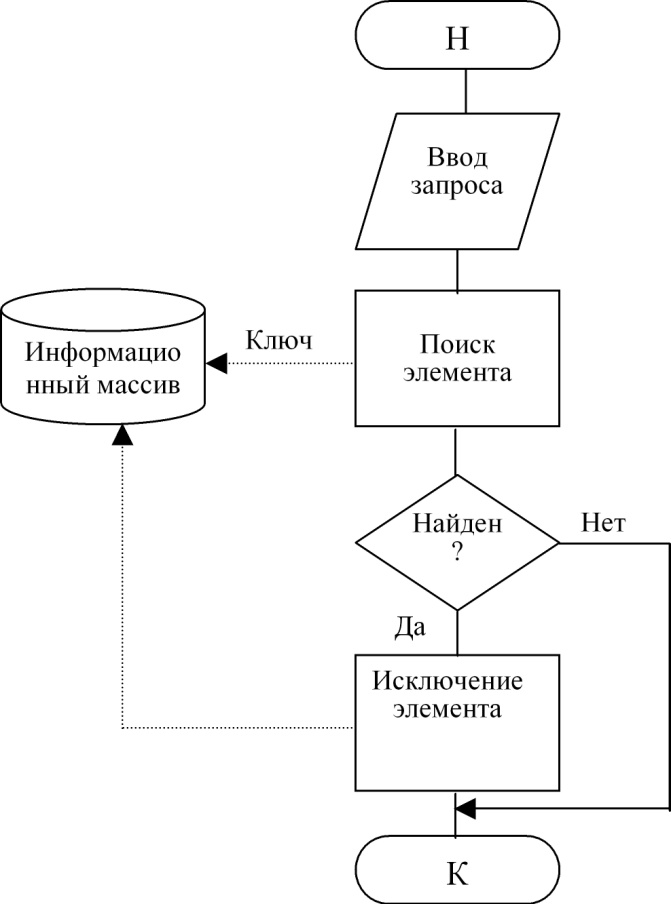
Рисунок 2.3. Технология удаления элемента
Технология просмотра элемента приведена на рис. 2.4. Различие в схемах состоит в том, что по технологии рис. 2.1 и 2.2 выполняется воздействие на информационный массив с целью его изменения, для чего в него передаются данные, по технологии рис. 2.3 воздействие не связано с передачей данных, а по схеме рис. 2.4 данные выводятся из информационного массива без его изменения.
При выполнении рассмотренных действий над элементами информационного массива на практике важны два фактора, противоречащие друг другу: временной фактор, в соответствии с которым запрос пользователя должен обрабатываться в минимальные сроки, и фактор минимизации требуемого объема памяти для хранения данных.
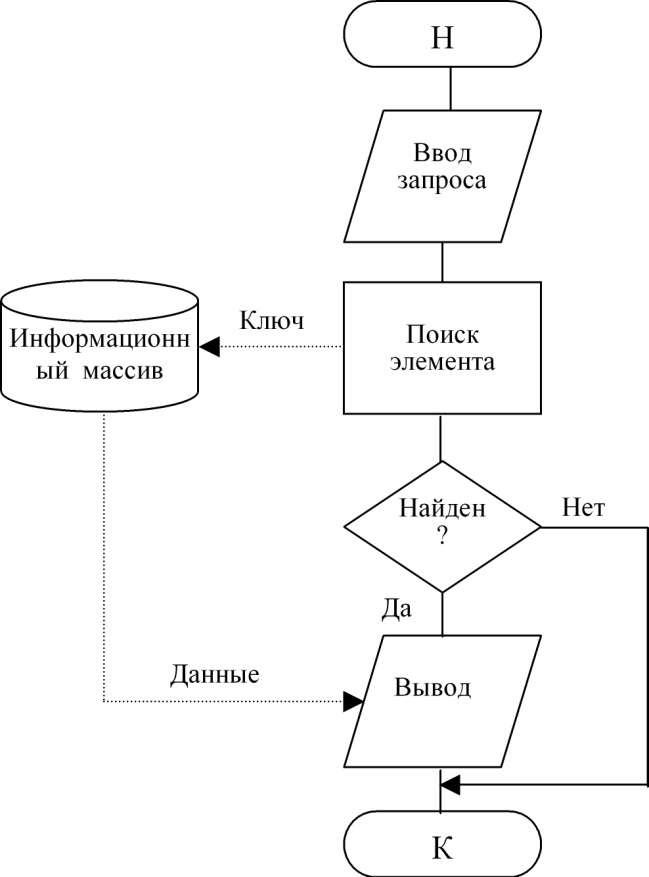
Рисунок 82. Технология просмотра элемента
Для уменьшения времени обработки запроса особые усилия прилагаются к применению таких структур хранения данных, которые позволяли бы оптимизировать поисковые операции, возможно, за счет дополнительных описаний данных. Это, очевидно, повышает расход памяти. Поэтому при проектировании моделей данных учитывается предполагаемый режим эксплуатации информационного массива: если это интерактивный режим, то основное внимание уделяется минимизации времени доступа к данным, если же режим пакетный, то минимизируют требуемую память. Кроме того, на выбор модели влияют особенности той предметной области, которая отражается в структурах хранения.
В силу вышесказанного, основное внимание в данном разделе уделено задачам организации хранения данных разных видов и поиска по ключам, входящим в запросы пользователей, поскольку поисковые операции и определяют, в основном, продолжительность различных действий над информационным массивом. Из приведенных типов действий в рассмотрение включены добавление и просмотр элементов данных, поскольку добавление связано с воздействием на информационный массив и изменением его объема (напомним, что удаление является обратным действием по отношению к добавлению), а просмотр - это наиболее часто выполняемые действия на практике. При этом рассматриваются общие вопросы работы с текстовой и структурированной информацией, методы и модели, используемые при организации хранения, поиска и добавления данных.
Излагаемые модели данных и алгоритмы доступа к ним составляют “brainware” современной информатики, носят универсальный характер и применяются в большинстве систем, связанных с хранением и обработкой информационных массивов.
2.2 Индексирование
Одна из основных задач, возникающих при работе с базами данных, – это задача поиска. При этом, поскольку информации в базе данных, как правило, содержится много, перед программистами встает задача не просто поиска, а эффективного поиска, т.е. поиска за сравнительно короткое время и с достаточно большой точностью. Для этого (для оптимизации производительности запросов) производят индексирование некоторых полей таблицы. Использовать индексы полезно для быстрого поиска строк с указанным значением одного столбца. Без индекса чтение таблицы осуществляется по всей таблице, начиная с первой записи, пока не будут найдены соответствующие строки. Чем больше объем таблицы, тем выше накладные расходы. Если же таблица содержит индекс по рассматриваемым столбцам, то база данных может быстро определить позицию для поиска в середине файла данных без просмотра всех данных. Это происходит потому, что база данных помещает проиндексированные поля поближе в памяти, так, чтобы можно было побыстрее найти их значения. Для таблицы, содержащей 1000 строк, это будет как минимум в 100 раз быстрее по сравнению с последовательным перебором всех записей. Однако в случае, когда необходим доступ почти ко всем 1000 строкам, быстрее будет последовательное чтение, так как при этом не требуется операций поиска по диску. Так что иногда индексы бывают только помехой. Например, если копируется большой объем данных в таблицу, то лучше не иметь никаких индексов. Однако в некоторых случаях требуется задействовать сразу несколько индексов (например, для обработки запросов к часто используемым таблицам).
Если говорить о MySQL, то там существует три вида индексов: PRIMARY, UNIQUE, и INDEX, а слово ключ (KEY) используется как синоним слова индекс (INDEX). Все индексы хранятся в памяти в виде B-деревьев.
PRIMARY – уникальный индекс (ключ) с ограничением, устанавливающим, что все индексированные им поля не могут иметь пустого значения (т.е. они NOT NULL). Таблица может иметь только один первичный индекс, который может состоять из нескольких полей.
UNIQUE – ключ (индекс), задающий поля, которые могут иметь только уникальные значения.
INDEX – обычный индекс (как описано выше). В MySqL, кроме того, можно индексировать строковые поля по заданному числу символов от начала строки.
2.2 Организация журнала операции с базой данных в информационной системе ООО «РУСПРОМКОМ»
Одним из основных требований к СУБД является надежность хранения данных во внешней памяти. Это означает, что СУБД должна суметь восстановить последнее согласованное состояние базы данных (БД) после любого аппаратного или программного сбоя. Обычно рассматриваются два возможных вида аппаратных сбоев: «мягкие сбои» - внезапная остановка работы компьютера (например, аварийное выключение питания), и «жесткие сбои», характеризуемые потерей информации на носителях внешней памяти.
В любом случае для восстановления БД нужно иметь дополнительную информацию. Поддержание надёжности хранения данных в БД требует избыточности хранения данных. При этом особо надёжно должны храниться данные, используемые для восстановления. Распространённым методом поддержания такой избыточной информации является ведение журнала изменений БД.
Журнал - это поддерживаемая с особой тщательностью часть БД, недоступная пользователям СУБД. В неё поступают записи обо всех изменениях основной части БД. Иногда поддерживают две копии журнала, размещая их на разных физических дисках.
Во всех случаях придерживаются стратегии «упреждающей» записи в журнал. Это означает, что запись об изменении любого объекта БД должна попасть во внешнюю память журнала раньше, чем измененный объект попадёт во внешнюю память основной части БД. Если в СУБД корректно соблюдается протокол WAL (WriteAheadLog), то с помощью журнала можно решить все проблемы восстановления БД после любого сбоя.
Целью процесса восстановления после мягкого сбоя является состояние внешней памяти основной части БД, которое возникло бы при фиксации во внешней памяти изменений всех завершившихся транзакций и которое не содержало бы никаких следов незаконченных транзакций. Для этого сначала производят откат незавершенных транзакций (undo), а потом повторно воспроизводят (redo) те операции завершенных транзакций, результаты которых не отображены во внешней памяти. Этот процесс содержит много тонкостей, связанных с общей организацией управления буферами и журналом.
Для восстановления БД после жесткого сбоя используют журнал и архивную копию БД. Архивная копия - это полная копия БД к моменту начала заполнения журнала. Для нормального восстановления БД после жесткого сбоя необходимо, чтобы журнал не пропал. К сохранности журнала во внешней памяти в СУБД предъявляются особо повышенные требования. Тогда восстановление БД состоит в том, что, исходя из архивной копии, по журналу воспроизводится работа всех транзакций, которые закончились к моменту сбоя. В принципе, можно даже воспроизвести работу незавершенных транзакций и продолжить их работу после завершения восстановления.
При эксплуатации информационных систем возможны не только сбои в работе оборудования, но также и ошибки оператора. В первом случае может потребоваться выполнить восстановление БД с ее резервной копии. Для этого используются стандартные утилиты, входящие в комплект системы управления базами данных (СУБД). Такие утилиты имеются и в составе СУБД PostgreSQL. В случае же ошибок оператора, особенно если они обнаружены с опозданием, выполнение восстановления базы данных посредством системной утилиты приведет к тому, что будут утрачены и корректные изменения базы данных, выполненные после проведения последнего резервного копирования. Таким образом, даже небольшая ошибка оператора может привести к необходимости повторного выполнения ввода или корректировки значительного объема данных.
Если бы в базе данных сохранялась вся история изменений каждой реляционной таблицы, то администратор имел бы возможность выполнять восстановление не только всей таблицы целиком, но и каждой конкретной строки в таблице.
В докладе предлагается организовать такую систему учета изменений базы данных, которая была бы построена на основе системы правил (rules) СУБД PostgreSQL.
Основные принципы и правила ее построения следующие.
- В каждую таблицу базы данных вводятся следующие атрибуты, содержащие служебную информацию:
who_chgtext DEFAULT USER - кем добавлена (изменена) запись;
when_chg timestamp;
DEFAULTCURRENT_TIMESTAMP - когда добавлена (изменена) запись.
- Для каждой таблицы базы данных, которые назовем рабочими таблицами, должна быть создана таблица, которую будем называть журнальной. Эта таблица содержит все атрибуты рабочей таблицы и дополнительно еще три атрибута:
db_operationtext - операция над БД;
who_addtextDEFAULTUSER - кем добавлена запись;
when_addtimestampDEFAULTCURRENT_TIMEST AMP - когда добавлена запись.
- Журнальные таблицы создаются без каких-либо ограничений целостности. Ограничения целостности не нужны, поскольку записи в журнальные таблицы добавляются только из рабочих таблиц, а в рабочих таблицах ограничения целостности присутствуют, поэтому данные в них согласованные.
- Для каждой рабочей таблицы создается три так называемых правила (CREATERULE). Это расширение языка SQL, поддерживаемое СУБД PostgreSQL.
Правила позволяют с каждой операцией, выполняемой над таблицей базы данных, связать некоторые дополнительные операции, выполняемые, возможно, над другими таблицами. В нашей технологии правила создаются для операций вставки записей в таблицу (INSERT), обновления записи в таблице (UPDATE) и удаления записей из таблицы (DELETE).
Правило для операции вставки записей выглядит так:
CREATE RULE Langs_rule_1 AS ON INSERT TO sost_zayvki DO INSERT INTO sost_zayvki_2 (id,id_zayavki,naimenovanie,sechenie, kol-vo, m2, stoim, itogo, skidka,who_chg,when_chg,db_operation )VALUES(
NEW.id,NEW.id_zayavki,NEW.naimenovanie,NEW.sec henie,NEW.kol-vo,NEW.m2, NEW.stoim, NEW.itogo,NEW.skidka, NEW.who_chg, NEW.when_chg, 'INSERT' );
В этой команде таблица sost_zayvki - это основная таблица, а sost_zayvki_2 - журнальная таблица. Атрибут db_operation будет содержать значение 'INSERT', атрибут who_add - значение по умолчанию, т. е. имя пользователя, добавившего запись в рабочую таблицу, атрибут when_add - значение по умолчанию, т. е. временную отметку выполнения операции.
Правило для операции обновления записей выглядит так:
CREATE RULE Langs_rule_2 AS
ON UPDATE TO sost_zayvki
DO INSERT INTO sost_zayvki_2 (id, id_zayavki, naimenovanie, sechenie, kol-vo, m2, stoim, itogo, skidka,who_chg, when_chg, db_operation )VALUES (NEW.id,NEW .id_zayavki,NEW. naimenovanie,NEW.sec henie,NEW.kol-vo,NEW. m2, NEW.stoim, NEW.itogo,NEW.skidka,NEW.who_chg, NEW.when_chg, 'UPDATE' );
Правило для операции удаления записей выглядит так:
CREATE RULE Langs_rule_3 AS
ON DELETE TO sost_zayvki
DO INSERT INTO sost_zayvki_2 (id, id_zayavki, naimenovanie, sechenie, kol-vo, m2, stoim, itogo, skidka,who_chg, when_chg, db_operation )VALUES (OLD.id,OLD.id_zayavki,OLD. naimenovanie,OLD.seche nie,OLD.kol-vo,OLD. m2, OLD.stoim,
OLD.itogo,OLD .skidkaOLD .who_chg, OLD.when_chg, 'DELETE' );
- В журнальные таблицы записи только добавляются, но не обновляются и не удаляются из них. Поэтому сохраняется вся история изменения каждой записи из рабочей таблицы.
Предложенный подход позволит повысить безопасность выполнения операций с базой данных. В случае ошибки оператора администратор базы данных сможет отыскать запись в журнальной таблице и восстановить то состояние конкретной записи в рабочей таблице, которое требуется.
ЗАКЛЮЧЕНИЕ
Само слово «данные» происходит от латинского слова data, что означает информация. Таким образом, в самом общем значении это слово обозначает информацию, которая передаётся в каком-либо формализованном виде: слова, цифры, коды.[1]
Из всего многообразия подходов к определению понятия "данные" справедливо то, которое говорит о том, что данные несут в себе информацию о событиях, произошедших в материальном мире, поскольку они являются регистрацией сигналов, возникших в результате этих событий. Однако данные не тождественны информации. Станут ли данные информацией, зависит от того, известен ли метод преобразования данных в известные понятия. То есть, чтобы извлечь из данных информацию необходимо подобрать соответствующий форме данных адекватный метод получения информации. Данные, составляющие информацию, имеют свойства, однозначно определяющие адекватный метод получения этой информации. Причем необходимо учитывать тот факт, что информация не является статичным объектом - она динамически меняется и существует только в момент взаимодействия данных и методов. Все прочее время она пребывает в состоянии данных. Информация существует только в момент протекания информационного процесса. Все остальное время она содержится в виде данных.[2]

