Добавлен: 04.05.2024
Просмотров: 30
Скачиваний: 0
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.

Отчёт к 1-й лабораторной работе по дисциплине СПиМПИ
Выполнил студент группы КТмо1-9 Караев Артём
Направление исследований
В качестве темы для исследований я решил выбрать self-supervised learning (обучение с самоконтролем) в deep learning. Данная тематика интересна лично мне, так как, по моему мнению, является очень перспективной. Self-supervised подход позволяет производить обучение сложных моделей, требующих большой размеченный датасет, без его наличия. Например, мне очень понравилась статья команды NVIDIA «Self-Supervised Pre-Training of Swin Transformers for 3D Medical Image Analysis», где очень жадную до данных модель swin трансформера смогли предобучить на неразмеченных КТ снимках, что впоследствии позволит избежать очень трудоёмкой разметки КТ снимков в огромном количестве.
Как это относится со стратегией развития информационного общества в РФ на 2017-2030 годы? Честно говоря, я не смог осилить тот документ. Многовато воды, как по мне, но, насколько я понял, акцент ставится на том, чтобы максимально упростить доступ ко всем возможным услугам (здравоохранение, правоохранение и различные юридические услуги) для граждан России с помощью информационных технологий.
Не знаю уж, насколько приведённая мною тема сочетается со стратегией развития, но полагаю, тот же приведённый выше пример с КТ снимками может многое сказать. Модели на основе нейронных сетей уже активно используются во всех сферах жизни. Возможность получить высокоточные модели для использования в медицине сможет облегчить, а местами даже автоматизировать работу соответствующих специалистов.
Поиск статей в системе Scopus
Полный поисковой запрос выглядит следующим образом: ( TITLE-ABS-KEY ( "deep learning" ) ) AND ( "self-supervised learning" OR "self supervised learning" ).
Как основа для поиска мной была взята тема deep learning, а затем она была сужена наличием в статьях фразы self-supervised learning. Через «or» были написаны два варианта написания, с тире и без него, так как разные авторы могут писать по-разному, а для поиска это важно. После получения выборки мной были рассмотрены названия статей из каждой сферы знаний, и так как все они не отходили от темы deep learning, было решено ничего не исключать. В итоге получилась выборка из 2909 статей.
Изучив распределение статей по годам публикаций (см. рис. 1), можно сказать, что тема появилась совсем недавно и в самом деле очень свежая.
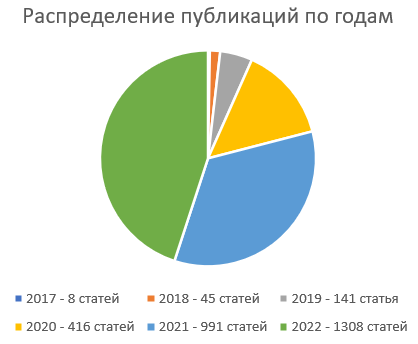
Рисунок 1 – Распределение публикаций по годам
Каждый год количество публикаций возрастает почти что с геометрической прогрессией.
Самые цитируемые статьи:
-
Exploring the limits of transfer learning with a unified text-to-text transformer (https://arxiv.org/abs/1910.10683) – 1109 цитирований -
Generative adversarial network in medical imaging: A review (https://arxiv.org/pdf/1809.07294.pdf) – 548 цитирований -
Artificial intelligence in cancer imaging: Clinical challenges and applications (https://www.researchgate.net/publication/330893720_Artificial_intelligence_in_cancer_imaging_Clinical_challenges_and_applications) – 545 цитирований -
Deep learning classifiers for hyperspectral imaging: A review (https://www2.umbc.edu/rssipl/people/aplaza/Papers/Journals/2019.ISPRS.Deeplearning.pdf) – 343 цитирований -
Deep learning for image-based cancer detection and diagnosis − A survey (https://www.researchgate.net/publication/325326901_Deep_Learning_for_Image-based_Cancer_Detection_and_Diagnosis_-_A_Survey) – 261 цитирований
Немного грустно, что 3 из 5 самых популярных статей оказались review и survey, но даже по их названиям можно сделать вывод, что self-supervised learning используется для обучения моделей, работающих над медицинскими визуальными данными. Этому же посвящена и 3-я по популярности статья. Самая же цитируемая статья оказалась направлена в сторону transfer обучения трансформеров для NLP задач.
Ведущие источники:
-
Lecture Notes In Computer Science Including Subseries Lecture Notes In Artificial Intelligence And Lecture Notes In Bioinformatics – 214 публикаций -
IEEE Access – 109 публикаций -
IEEE Robotics And Automation Letters – 67 публикаций -
Proceedings Of The IEEE Computer Society Conference On Computer Vision And Pattern Recognition – 51 публикаций -
ICASSP IEEE International Conference On Acoustics Speech And Signal Processing Proceedings – 45 публикаций
Ведущие организации:
-
Chinese Academy of Sciences – 95 публикаций -
Ministry of Education China – 67 публикаций -
Tsinghua University – 63 публикаций -
University of Chinese Academy of Sciences – 47 публикаций -
Shanghai Jiao Tong University - 40 публикаций
Китайцы вообще в последнее время очень активно ведут исследования в сфере DL, но вместе с этим ими выпускается и безумное множество survey и review статей. Полагаю, что отчасти это и могло так сильно застолбить за ними этот топ.
Выгрузка, сортировка и распределение статей
После выгрузки в файле оказалось 2000 статей. Из них мной были удалены все статьи без ключевых слов. Осталось 1644 статьи. Я решил не удалять статьи с нулевым показателем цитирований

, так как все из них оказались 2022 года, что, по моему мнению, говорит о свежести статей и, возможно, ещё не сформировавшемся интересе. К тому же, ещё при выгрузке большая часть обрезанных статей оказалась 2022 года, что сильно уменьшило их количество.
Как было замечено ранее, тема очень новая, и потому особо большого диапазона дат нет. Смотря на это, мне стало интересно провести анализ по годам, чтобы увидеть, как акценты в этой бурно растущей теме смещаются каждый год.
Временные группы:
-
2017-2018 – 33 статьи -
2019 – 72 статьи -
2020 – 165 статьи -
2021 – 227 статьи -
2022 – 222 статьи
При группировке ключевых слов были удалены слова, встречающиеся меньше 3-х раз. Получилось 333 ключевых слова. После автоматической группировки мною уже вручную было создано около 20 групп, в которые я включил очень близкие по смыслу понятия. Остальные же слова были распределены в отдельные группы. Итоговое количество – 248.
Анализ кластеров
Для алгоритмов кластеризации были выбраны параметры: максимальный размер – 5, минимальный размер – 3
При анализе образовалась следующая Overlapping map (см. рис. 2).

Рисунок 2 – Overlapping map
Далее приведён скриншот окна period view (рис. 3), с которым велась дальнейшая работа
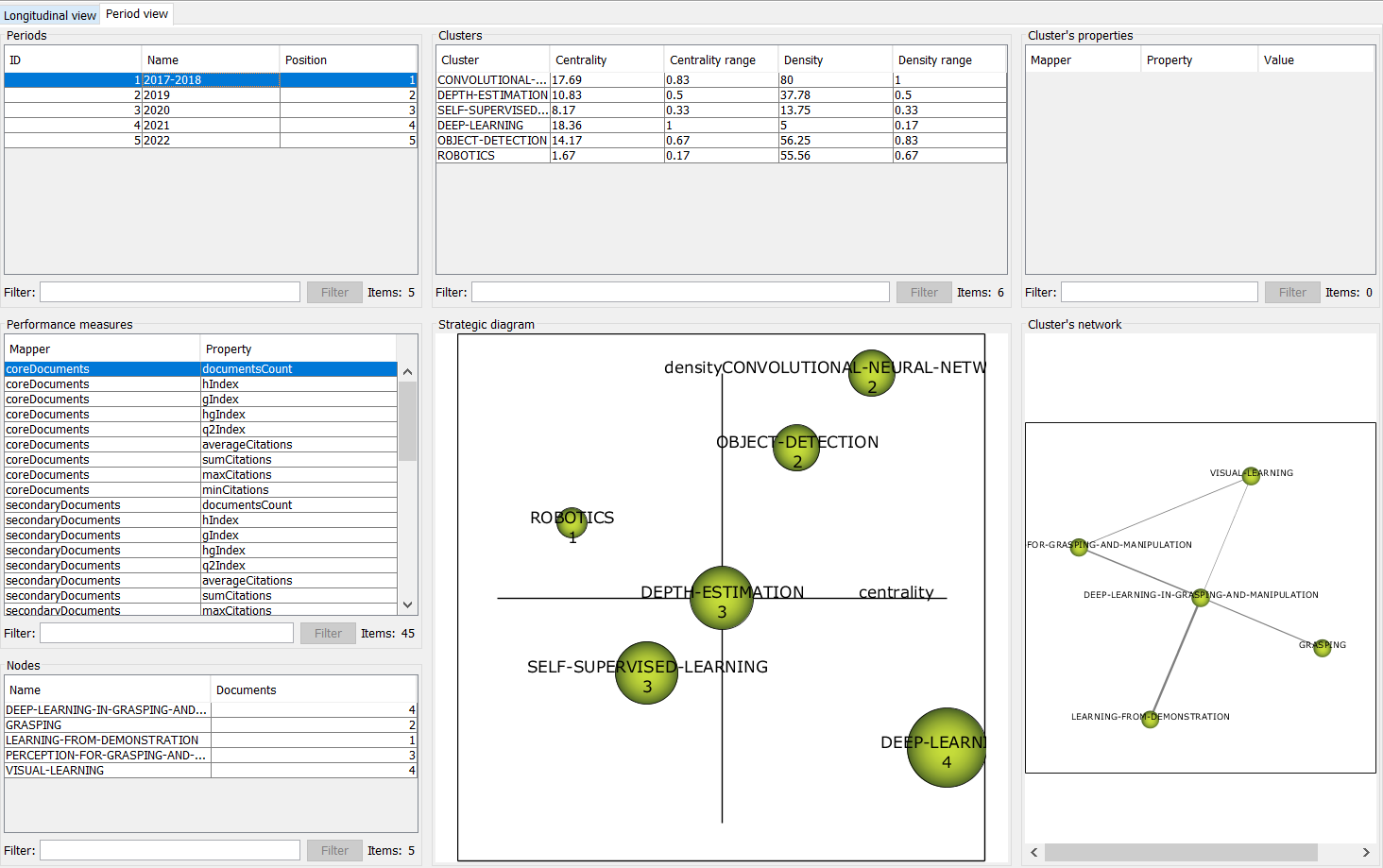
Рисунок 3 – Окно period view проведённого анализа
2017 – 2018 годы:
Тема только зарождается и содержит в себе совсем немного кластеров (рис. 4).
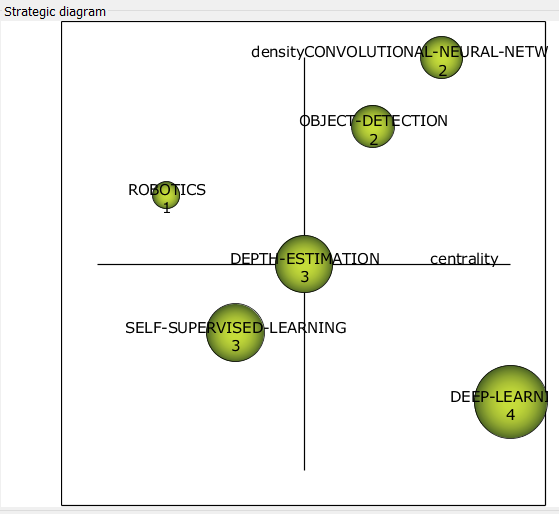
Рисунок 4 – Стратегическая диаграмма 2017-2018
Кластер deep learning (см. рис. 5), связанный со всей отраслью в целом, описывающий общую тему, находится в квадранте «фургонов» и включает в себя понятия из CV, а также метод предобработки данных data augmentation.
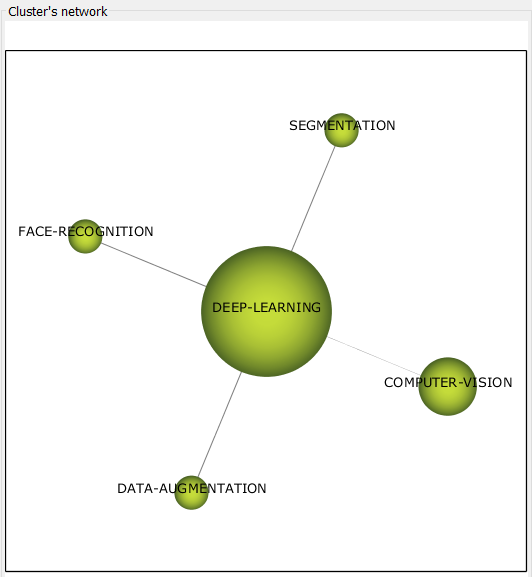
Рисунок 5 – Кластер deep learning 2017-2018
В тренде на тот момент находился кластер со свёрточными сетями (см. рис. 6), включающий в себя несколько задач компьютерного зрения и метод обучения сетей.
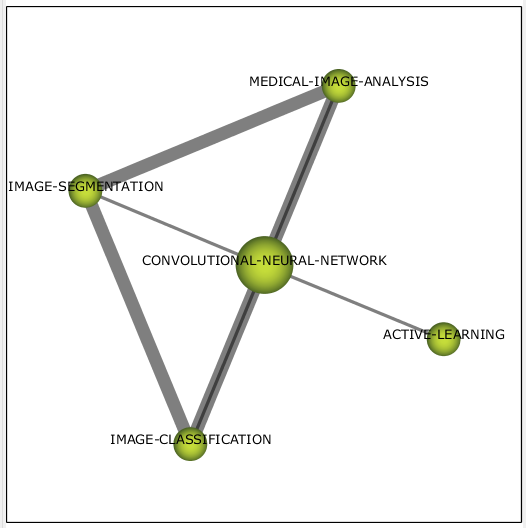
Рисунок 6 – Кластер convolutional neural network 2017-2018
Кластер, посвящённый самому обучению с самоконтролем (см. рис. 7), находится в «хаос»
квадранте как новая, набирающая силу тема, и содержит в себе 2 задачи компьютерного зрения и 2 метода обучения нейронных сетей.
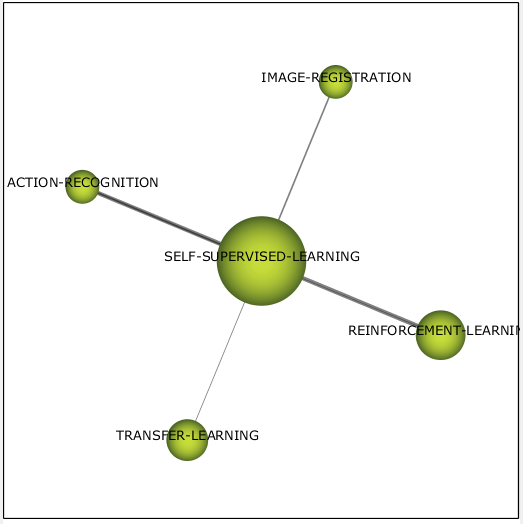
Рисунок 7 – Кластер self-supervised learning 2017-2018
Также в тренде на тот момент находился кластер, посвящённый задаче обнаружения объектов (см. рис. 8), который был связан с двумя прочими задачами из CV и методе обучения сетей – гибриде контролируемого и неконтролируемого обучения.
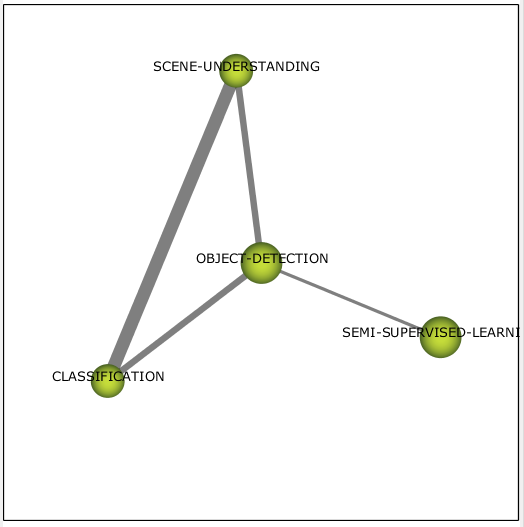
Рисунок 8 – Кластер object detection 2017-2018
2019:
На стратегической диаграмме (см. рис. 9) заметно больше тем. Некоторые кластеры из прошлого временного периода перекочевали и в этот, но сменили своё местоположение. Среди трендов появились медицинские изображения, про которые я говорил ранее.
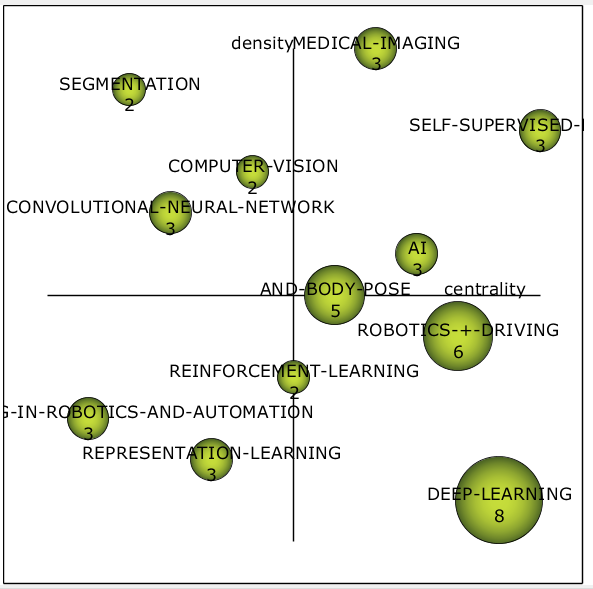
Рисунок 9 – Стратегическая диаграмма 2019
Кластер самоконтролируемого обучения (см. рис. 10) переместился из хаоса в мейнстрим, пропустив кластер фургонов. Теперь прослеживается связь с задачей оценки глубины на изображении и извлечением признаков из медицинских изображений.
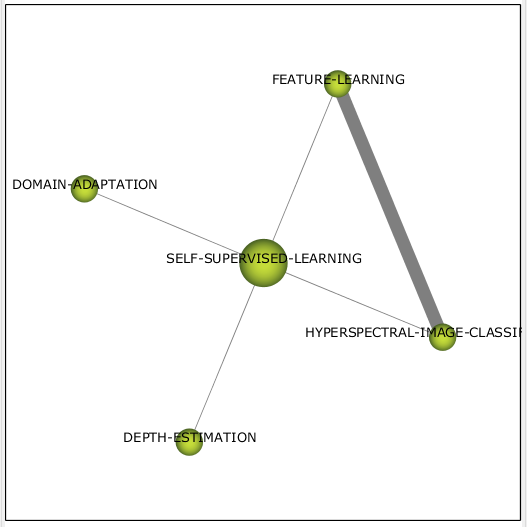
Рисунок 10 – Кластер self-supervised learning 2019
Кластер со свёрточными сетями (см. рис. 11) переместился к башням из слоновой кости как достаточно развитая, но уже немного изжитая тема. Связанные темы наполовину нацелены в сторону медицины, но в то же время остаётся задача по распознаванию действий и метод получения данных для обучения.
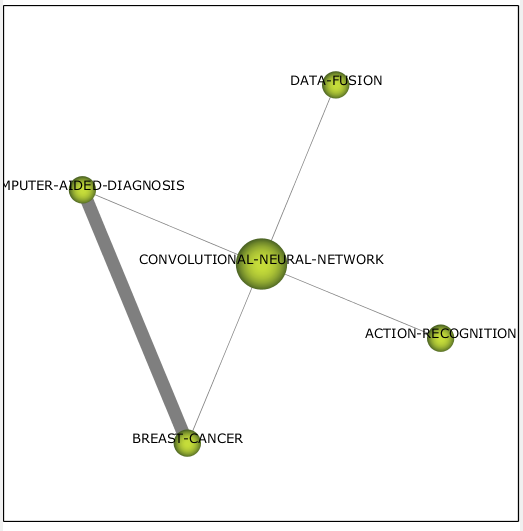
Рисунок 11 – Кластер convolutional neural network 2019
Самый популярный кластер текущего периода deep learning (см. рис. 12) всё так же в качестве общей темы находится среди фургонов. Он включает в себя несколько методов обучения сетей и задачу воссоздания модели трёхмерного объекта.
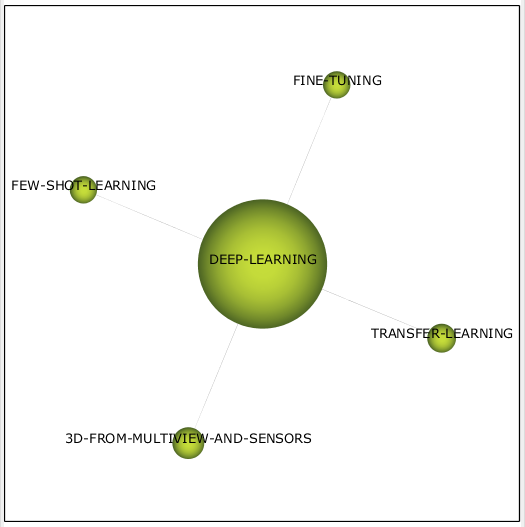
Рисунок 12 – Кластер deep learning 2019
В тренде в данный период находились темы
, связанные с медицинскими изображениями (см. рисунок 13). Данный кластер содержит уже встречавшееся ранее semi-supervised learning, а также неразмеченные данные и модель GAN. В добавок есть тема review, не несущая какого-то интереса.
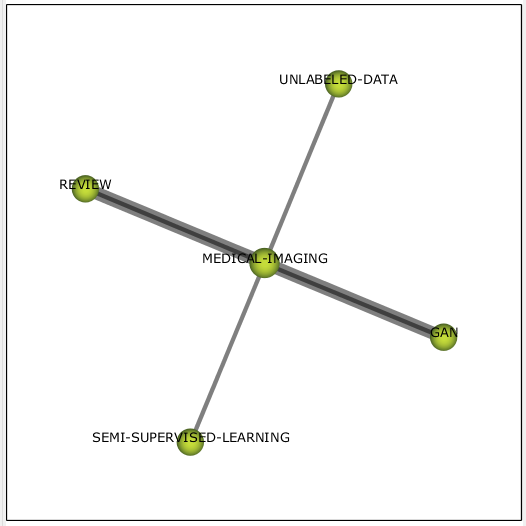
Рисунок 13 – Кластер medical imaging 2019
2020:
Ещё больше статей, ещё больше тем. Стратегическая диаграмма (см. рис. 14) становится немного перегруженной.
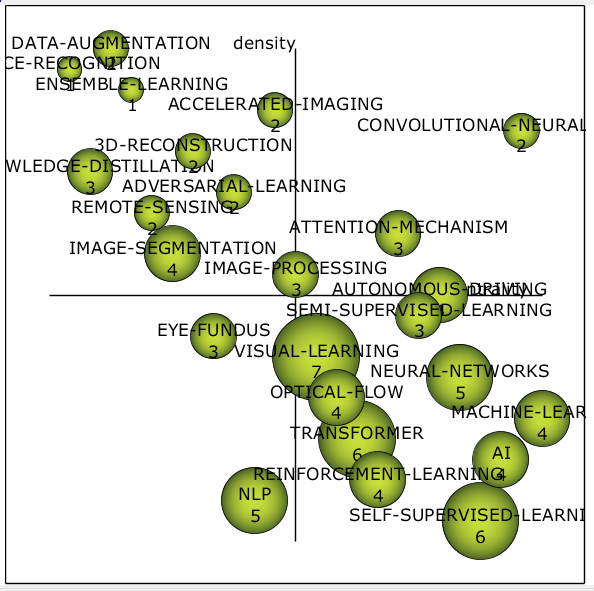
Рисунок 14 – Стратегическая диаграмма 2020
Весьма интересный, по моему мнению, кластер, связанный с самоконтролируемым обучением – transformer (см. рис. 15). Данный кластер появился сразу в квадранте фургонов и содержит в себе 2 подхода к обучению (multimodal learning и lifelong learning), а также 2 задачи.
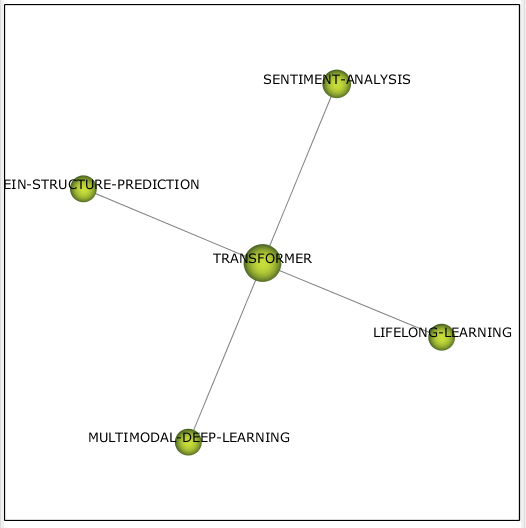
Рисунок 15 – Кластер transformer 2020
Тема semi-supervised learning, находящаяся ранее в кластере medical imaging в тренде, оказалась в самостоятельном кластере (см. рис. 16) в квадранте фургонов, что, возможно, говорит о небольшом снижении внимания к этой теме. Кластер содержит 3 задачи из машинного обучения и метод обучения.
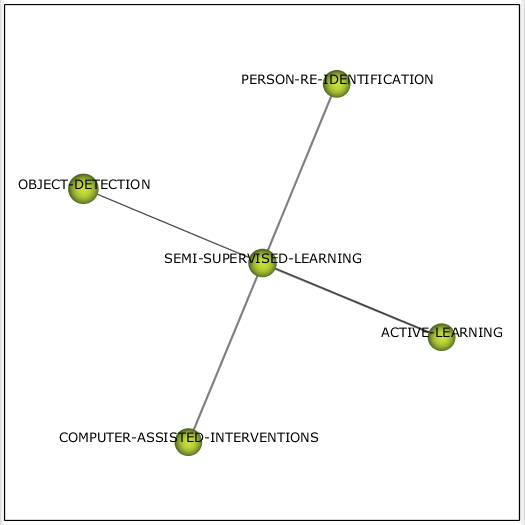
Рисунок 16 – Кластер semi-supervised learning 2020
Кластер о механизме внимания (см. рис. 17), который по своему смыслу связан с трансформерами, находится в квадранте хайпа. Он содержит в себе темы удаления шума, автоэнкодера (самообучаемый feature extractor), языковая модель и рекомендательные системы.
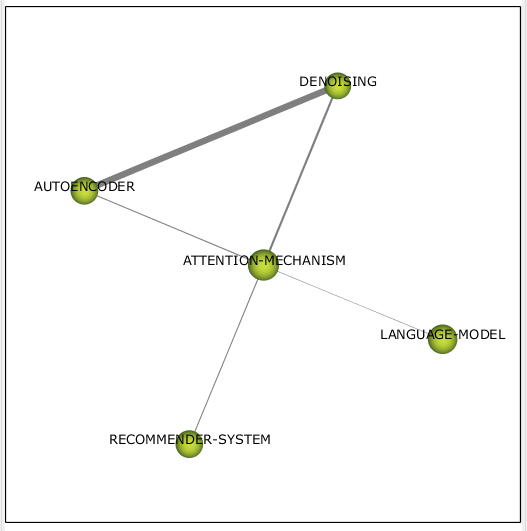
Рисунок 17 – Кластер attention mechanism 2020
Кластер NLP задач (см. рис. 18) появился в квадранте хаоса, что говорит о зарождении интереса к этой теме в рамках self-supevised learning. Кластер содержит задачи ответа на вопросы, распознавания проименованных сущностей, а также понятие извлечения информации.
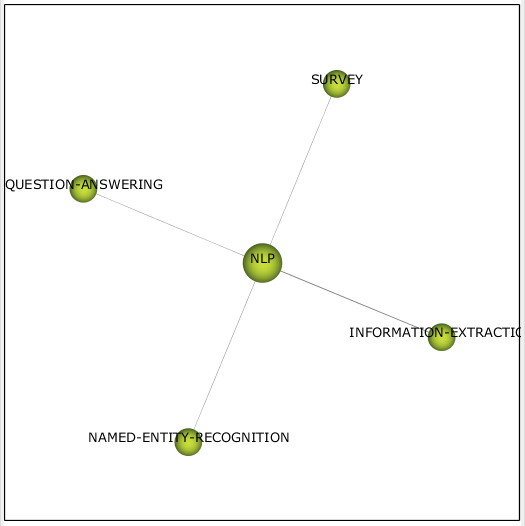
Рисунок 18 – Кластер NLP 2020
2021:
Стратегическая диаграмма (см. рис. 19) стала несколько захламлённой. Возможно, стоило сильнее обрезать словарь ключевых слов статей. Однако даже на такой диаграмме можно увидеть очень много интересных тем.
