Файл: Методы сортировки данных: эволюция и сравнительный анализ. Примеры использования ( Классы методов сортировки ).pdf
Добавлен: 29.02.2024
Просмотров: 61
Скачиваний: 0
Содержание:
ВВЕДЕНИЕ
Актуальность темы. Базы данных могут содержать сотни и тысячи записей. Часто бывает необходимо их упорядочить, т. е. расположить в определенной последовательности. Упорядочение записей называется сортировкой. Сортировка записей производится по какому-либо полю базы данных. Значения, содержащиеся в этом поле, располагаются в порядке возрастания или убывания. В процессе сортировки целостность записей сохраняется, т. е. строки таблицы перемещаются целиком. Сортировка – один из важнейших аспектов обработки данных, позволяющий ускорить и упростить этот наиважнейший в области вычислительной техники процесс.
Цель курсовой работы – анализ сортировки данных.
Для достижения поставленной цели необходимо решить следующие задачи:
- рассмотретьосновные классы методов сортировки;
- исследоватьсортировку подсчетом;
- рассмотретьсортировку вставками;
- изучить обменную сортировку;
- представитьсортировку посредством выбора;
- рассмотреть шаблоны функций с++;
- представить теоретическое обоснование метода;
- реализовать алгоритм;
- провести тестирование алгоритма;
- представить итоги анализа алгоритма.
Создание системы сортировки данных в значительной степени сэкономит ресурсы ЭВМ, затрачиваемые на обработку данных, сделает более рациональным использование оперативной памяти при обращении к большим массивам данных.
1 . Классы методов сортировки
1.1 Основные классы методов сортировки
В настоящее время существует огромное количество самых различных способов сортировки. Все они являются методами внутренней или внешней сортировки. Внутренней сортировкой называется сортировка, при которой все количество сортируемых записей помещается в оперативной памяти, а внешней – когда в оперативной памяти невозможно разместить все записи. Внутренняя сортировка позволяет создавать более гибкие и, следственно более выгодные методы сортировки. Методы же внешней сортировки зачастую основаны на методах внутренней, с тем лишь различием, что в них внесены некоторые дополнительные шаги. Поэтому мы не будем останавливаться на внешней сортировке и рассмотрим основные классы методов внутренней сортировки.
Все методы можно разделить на четыре основных класса:
- Сортировка вставками;
- Сортировка подсчетом;
- Обменная сортировка;
- Сортировка посредством выбора. [5, с.76]
Эти классы включают в себя все множество методов внутренней сортировки, а также все множество всех известных на сегодняшний день их усовершенствований. Причем стоит отметить, что нельзя провести четкую грань между этими классами: методы сортировки очень тесно взаимосвязаны и похожи друг на друга, что создает определенные связи между классами методов. Остановимся более подробно на этих классах.
1.2 Сортировка подсчетом
При сортировке методом подсчета упорядоченная последовательность элементов создается на свободном участке памяти. Идея метода заключается в следующем: в отсортированной последовательности, элемент, занимающий позицию с номером К+1, превышает ровно К элементов, поэтому в процессе сортировки методом подсчета на каждом i-ом проходе мы попарно сравниваем i-й элемент со всеми элементами массива. Если установлено, что mass[i] > mass[j], то увеличиваем счетчик К на единицу (в начале К = 0). По окончании текущего прохода счетчик К указывает количество элементов, меньших, чем mass[i], поэтому элемент mass[i] занимает в отсортированной последовательности позицию К + 1 (sortedMass[k + 1] = mass[i])[3, с.84].
Внимание. Рассмотренный алгоритм можно использовать только для последовательностей, которые не содержат одинаковых элементов! Для сортировки последовательностей, содержащих одинаковые элементы, алгоритм необходимо модифицировать.
Приведем реализацию алгоритма сортировки методом подсчета на языке программирования Си. Необходимо учесть, что в языке Си нумерация элементов массива начинается с нуля.
//сортировкаметодомподсчета
void methodOfCalculation(int n, int mass[], int sortedMass[])
{
int k;
for (int i = 0; i < n; i++)
{
k = 0;
for (int j = 0; j < n; j++)
{
if (mass[i] > mass[j])
k++;
}
sortedMass[k] = mass[i];
}
}
Ниже находится пример консольной программы на языке программирования Си, которая считывает исходную последовательность, сортирует ее методом подсчета и выводит отсортированный массив на экран.
#include <stdio.h>
#include <malloc.h>
#include <conio.h>
//сортировка методом подсчета
void methodOfCalculation(int n, int mass[], int sortedMass[])
{
int k;
for (int i = 0; i < n; i++)
{
k = 0;
for (int j = 0; j < n; j++)
{
if (mass[i] > mass[j])
k++;
}
sortedMass[k] = mass[i];
}
}

int main()
{
//ввод N
int N;
printf("Input N: ");
scanf_s("%d", &N);
//выделение памяти под массивы
int *mass, *sortedMass;
mass = (int *)malloc(N * sizeof(int));
sortedMass = (int *)malloc(N * sizeof(int));
//вводэлементовмассива
printf("Input the array elements:\n");
for (int i = 0; i < N; i++)
scanf_s("%d", &mass[i]);
//сортировкаметодомподсчета
methodOfCalculation(N, mass, sortedMass);
//вывод отсортированного массива на экран
printf("Sorted array:\n");
for (int i = 0; i < N; i++)
printf("%d ", sortedMass[i]);
printf("\n");
//освобождениепамяти
free(mass);
free(sortedMass);
_getch();
return 0;
}
Демонстрация работы программы приведена на скриншоте:
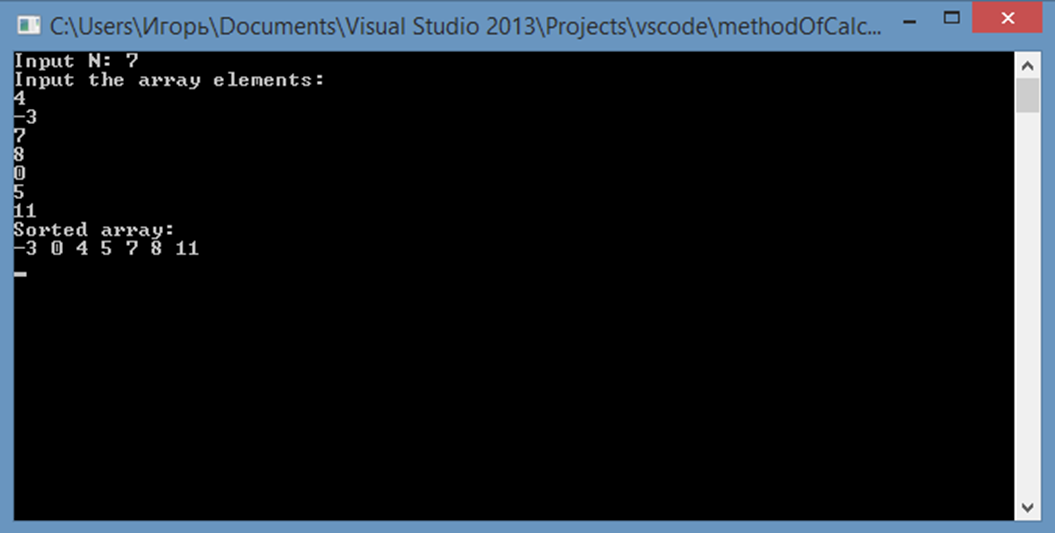
Рисунок 1 - Демонстрация работы программы
1.3 Сортировка вставками
Общая суть сортировок вставками такова:
- Перебираются элементы в неотсортированной части массива.
- Каждый элемент вставляется в отсортированную часть массива на то место, где он должен находиться[8, с.95].
То есть, сортировки вставками всегда делят массив на 2 части — отсортированную и неотсортированную. Из неотсортированной части извлекается любой элемент. Поскольку другая часть массива отсортирована, то в ней достаточно быстро можно найти своё место для этого извлечённого элемента. Элемент вставляется куда нужно, в результате чего отсортированная часть массива увеличивается, а неотсортированная уменьшается
Самое слабое место в этом подходе — вставка элемента в отсортированную часть массива. На самом деле это непросто и на какие только ухищрения не приходится идти, чтобы выполнить этот шаг[1, с.17]
Проходим по массиву слева направо и обрабатываем по очереди каждый элемент. Слева от очередного элемента наращиваем отсортированную часть массива, справа по мере процесса потихоньку испаряется неотсортированная. В отсортированной части массива ищется точка вставки для очередного элемента. Сам элемент отправляется в буфер, в результате чего в массиве появляется свободная ячейка — это позволяет сдвинуть элементы и освободить точку вставки.
definsertion(data):
for i in range(len(data)):
j = i - 1
key = data[i]
while data[j] > key and j >= 0:
data[j + 1] = data[j]
j -= 1
data[j + 1] = key
return data
На примере простых вставок показательно смотрится главное преимущество большинства сортировок вставками, а именно — очень быстрая обработка почти упорядоченных массивов:
При таком раскладе даже самая примитивная реализация сортировки вставкам, скорее всего, обгонит супер-оптимизированный алгоритм какой-нибудь быстрой сортировки, в том числе и на больших массивах.
Этому способствует сама основная идея этого класса — переброска элементов из неотсортированной части массива в отсортированную. При близком расположении близких по величине данных место вставки обычно находится близко к краю отсортированной части, что позволяет вставлять с наименьшими накладными расходами.
Нет ничего лучше для обработки почти упорядоченных массивов чем сортировки вставками. Когда где-то встречается информация, что лучшая временная сложность сортировки вставками равна O(n), то, скорее всего, имеются в виду ситуации с почти упорядоченными массивами.
Сортировка простыми вставками с бинарным поиском. Так как место для вставки ищется в отсортированной части массива, то идея использовать бинарный поиск напрашивается сама собой[9, с.43]. Другое дело, что поиск места вставки не является критичным для временно́й сложности алгоритма (главный пожиратель ресурсов — этап самой вставки элемента в найденную позицию), поэтому данная оптимизация здесь мало что даёт.
А в случае почти отсортированного массива бинарный поиск может работать даже медленнее, поскольку он начинает с середины отсортированного участка, который, скорее всего, будет находиться слишком далеко от точки вставки (а на обычный перебор от позиции элемента до точки вставки уйдёт меньше шагов, если данные в массиве в целом упорядочены).
definsertion_binary(data):
for i in range(len(data)):
key = data[i]
lo, hi = 0, i - 1
while lo < hi:
mid = lo + (hi - lo) // 2
if key < data[mid]:
hi = mid
else:
lo = mid + 1
for j in range(i, lo + 1, -1):
data[j] = data[j - 1]
data[lo] = key
return data
В защиту бинарного поиска отмечу, что он может сказать решающее слово в эффективности других сортировок вставками. Благодаря ему, в частности, на среднюю сложность по времени O(n log n)выходят такие алгоритмы как сортировка библиотекаря и пасьянсная сортировка.
Парная сортировка простыми вставками. Модификация простых вставок, разработанная в тайных лабораториях корпорации Oracle. Эта сортировка входит в пакет JDK, является составной частью Dual-Pivot Quicksort. Используется для сортировки малых массивов (до 47 элементов) и сортировки небольших участков крупных массивов[9, с.44]
В буфер отправляются не один, а сразу два рядом стоящих элемента. Сначала вставляется больший элемент из пары и сразу после него метод простой вставки применяется к меньшему элементу из пары.Что это даёт? Экономию для обработки меньшего элемента из пары. Для него поиск точки вставки и сама вставка осуществляются только на той отсортированной части массива, в которую не входит отсортированная область, задействованная для обработки большего элемента из пары. Это становится возможным, поскольку больший и меньший элементы обрабатываются сразу друг за другом в одном проходе внешнего цикла[3, с.101]
На среднюю сложность по времени это не влияет (она так и остаётся равной O(n2)), однако парные вставки работают чуть быстрее чем обычные.
Алгоритмы иллюстрируем на Python, но тут приведу первоисточник (видоизменённый в целях читабельности) на Java:
for (int k = left; ++left <= right; k = ++left) {
//Очередную пару рядом стоя́щих элементов
//заносим в пару буферных переменных
int a1 = a[k], a2 = a[left];
if (a1 < a2) {
a2 = a1; a1 = a[left];
}
//Вставляем больший элемент из пары
while (a1 < a[--k]) {
a[k + 2] = a[k];
}
a[++k + 1] = a1;
//Вставляем меньший элемент из пары
while (a2 < a[--k]) {
a[k + 1] = a[k];
}
a[k + 1] = a2;
}
//Граничный случай, если в массиве нечётное количество элементов
//Для последнего элемента применяем сортировку простыми вставками
int last = a[right];
while (last < a[--right]) {
a[right + 1] = a[right];
}
a[right + 1] = last;
1.4 Обменная сортировка
Если описать в паре предложений по какому принципу работают сортировки обменами, то:
1. Попарно сравниваются элементы массива
2. Если элемент слева больше элемента справа, то элементы меняются местами
3. Повторяем пункты 1-2 до тех пор, пока массив не отсортируется.
Традиционно к «обменникам» относят сортировки, в которых элементы меняются (псевдо)случайным образом (bogosort, bozosort, permsort и т.п.).
defstooge_rec(data, i = 0, j = None):
if j isNone:
j = len(data) - 1
if data[j] < data[i]:
data[i], data[j] = data[j], data[i]
if j - i >1:
t = (j - i + 1) // 3
stooge_rec(data, i, j - t)
stooge_rec(data, i + t, j)
stooge_rec(data, i, j - t)
return data
defstooge(data):
return stooge_rec(data, 0, len(data) - 1)