Файл: Определение законов распределения случайных величин на основе опытных данных реферат.docx
Добавлен: 12.04.2024
Просмотров: 6
Скачиваний: 0
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.

Автономная некоммерческая образовательная организация высшего образования «Сибирский институт бизнеса и информационных технологий»
РЕФЕРАТ
Дисциплина: Высшая математика. Часть 3
Тема: Определение законов распределения случайных величин на основе опытных данных реферат.
Выполнил: студент группы: МН-1121(2)
Ф.И.О. Матвеева Вероника Евгеньевна
Город: Омск
Омск 2023
Содержание
Введение......................................................................................................................3
Глава1. Основные задачи математической статистики.........................................5
1.1 Задача определения закона распределения по статистическим данным…..5-6
1.2 Задача проверки правдоподобия гипотез…………………………………….6
1.3 Простая статистическая совокупность. Статистическая функция распределения…………………………………………………………………….6-10
Глава 2. Статистический ряд. Гистограмма…………………..………...........11-15
Глава 3. Числовые характеристики статистического распределения............16-19
Заключение.............................................................................................................20
Список использованных источников...................................................................21
ВВЕДЕНИЕ
Цель работы - приобретение практических навыков построения распределений и оценки выборочных характеристик случайных величин на основе опытных данных. Задачей реферата является ознакомиться с такими разделами как: «Основные задачи математической статистики», «Статистический ряд», «Гистограмма». Изучить числовые характеристики статистического распределения и выравнивание статистических рядов
Статистический ряд оформляется графически в виде так называемой гистограммы. Она строится следующим образом. По оси абцисс откладываются, а на каждом из интервалов как основании строится прямоугольник, площадь которого равна частоте данного интервала. Для построения гистограммы нужно частоту каждого интервала разделить на его длину и полученное число взять в качестве высоты прямоугольника. В случае равных по длине интервалов высоты прямоугольников пропорциональны соответствующим частотам. Из способа построения гистограммы следует, что полная ее площадь равна единице.
Допустим, что некоторый статистический ряд выровнен с помощью некоторой теоретической кривой f(x). Обычно в качестве такой кривой принимается функция распределения F(x). Как бы хорошо ни была подобрана теоретическая кривая, между ней и статистическим распределением всегда будут некоторые расхождения. Встает вопрос: чем объясняются эти расхождения? Случайными обстоятельствами, в первую очередь, связанными с малым количеством наблюдений, или неправильно подобранной функцией f(x)=F(x), определяющей эту кривую? Для ответа на этот вопрос служат так называемые критерии согласия.
ГЛАВА 1 ОСНОВНЫЕ ЗАДАЧИ МАТЕМАТИЧЕСКОЙ СТАТИСТИКИ
Математические законы теории вероятностей не являются беспредметными абстракциями, лишенными физического содержания; они представляют собой математическое выражение реальных закономерностей, фактически существующих в массовых случайных явлениях природы.
До сих пор, говоря о законах распределения случайных величин, мы не затрагивали вопроса о том, откуда берутся, на каком основании устанавливаются эти законы распределения. Ответ на вопрос вполне определенен — в основе всех этих характеристик лежит опыт; каждое исследование случайных явлений, выполняемое методами теории вероятностей, прямо или косвенно опирается на экспериментальные данные. Оперируя такими понятиями, как события и их вероятности, случайные величины, их законы распределения и числовые характеристики, теория вероятностей дает возможность теоретическим путем определять вероятности одних событий через вероятности других, законы распределения и числовые характеристики одних случайных величин через законы распределения и числовые характеристики других. Такие косвенные методы позволяют значительно экономить время и средства, затрачиваемые на эксперимент, но отнюдь не исключают самого эксперимента. Каждое исследование в области случайных явлений, как бы отвлеченно оно ни было, корнями своими всегда уходит в эксперимент, в опытные данные, в систему наблюдений.
Разработка методов регистрации, описания и анализа статистических экспериментальных данных, получаемых в результате наблюдения массовых случайных явлений, составляет предмет специальной науки — математической статистики.
Все задачи математической статистики касаются вопросов обработки наблюдений над массовыми случайными явлениями, но в зависимости от характера решаемого практического вопроса и от объема
имеющегося экспериментального материала эти задачи могут принимать ту или иную форму.
Охарактеризуем вкратце некоторые типичные задачи математической статистики, часто встречаемые на практике.
1.1Задача определения закона распределения случайной величины по статистическим данным
Мы уже указывали, что закономерности, наблюдаемые в массовых случайных явлениях, проявляются тем точнее и отчетливее, чем больше объем статистического материала. При обработке обширных по'своему объему статистических данных часто возникает вопрос об" определении законов распределения тех или иных случайных величин. Теоретически при достаточном количестве опытов свойственные этим случайным величинам закономерности будут осуществляться сколь угодно точно. На практике нам всегда приходится иметь дело с ограниченным количеством экспериментальных данных; в связи с этим результаты наших наблюдений и их обработки всегда содержат больший или меньший элемент случайности. Возникает вопрос о том, какие черты наблюдаемого явления относятся к постоянным, устойчивым и действительно присущи ему, а какие являются случайными и проявляются в данной серии наблюдений только за счет ограниченного объема экспериментальных данных. Естественно, к методике обработки экспериментальных данных следует предъявить такие требования, чтобы она, по возможности, сохраняла типичные, характерные черты наблюдаемого явления и отбрасывала все несущественное, второстепенное, связанное с недостаточным объемом опытного материала. В связи с этим возникает характерная для математической статистики задача сглаживания или выравнивания статистических данных, представления их в наиболее компактном виде с помощью простых аналитических зависимостей.
1.2 Задача проверки правдоподобия гипотез
Эта задача тесно связана с предыдущей; при решении такого рода задач мы обычно не располагаем настолько обширным статистическим материалом, чтобы выявляющиеся в нем статистические закономерности были в достаточной мере свободны от элементов случайности. Статистический материал может с большим или меньшим правдоподобием подтверждать или не подтверждать справедливость той или иной гипотезы. Например, может возникнуть такой вопрос: согласуются ли результаты эксперимента с гипотезой о том, что данная случайная величина подчинена закону распределения F(х)? Другой подобный вопрос: указывает ли наблюденная в опыте тенденция к зависимости между двумя случайными величинами на наличие действительной объективной зависимости между. ними или же она объясняется случайными причинами, связанными с недостаточным объемом наблюдений? Для решения подобных вопросов математиматическая статистика выработала ряд специальных приемов.
1.3 Простая статистическая совокупность. Статистическая функция распределения
Предположим, что изучается некоторая случайная величина X, закон распределения которой в точности неизвестен, и требуется определить этот закон из опыта или проверить экспериментально гипотезу о том, что величина X подчинена тому или иному закону. С этой целью над случайной величиной X производится ряд независимых опытов (наблюдений). В каждом из этих опытов случайная
Реклама
величина X принимает определенное значение. Совокупность наблюденных значений величины и представляет собой первичный статистический материал, подлежащий обработке, осмыслению и научному анализу. Такая совокупность называется «простой статистической совокупностью» или «простым статистическим рядом». Обычно простая статистическая совокупность оформляется в виде таблицы с одним входом, в первом столбце которой стоит номер опыта Л а во втором — наблюденное значение случайной величины. Пример 1. Случайная величина β - угол скольжения самолета в момент сбрасывания бомбы '). Произведено 20 бомбометаний, в каждом из которых зарегистрирован угол скольжения β в тысячных долях радиана. Результаты наблюдений сведены в простой статистический ряд:
| i | βi | i | βi | i | βi |
| | | | | | |
| 1 | —20 | 8 | —30 | 15 | —10 |
| | | | | | |
| 2 | —60 | 9 | 120 | 16 | 20 |
| | | | | | |
| 3 | —10 | 10 | —100 | 17 | 30 |
| | | | | | |
| 4 | 30 | 11 | —80 | 18 | —80 |
| | | | | | |
| 5 | 60 | 12 | 20 | 19 | 60 |
| | | | | | |
| 6 | 70 | 13 | 40 | 20 | 70 |
| | | | | | |
| 7 | —10 | 14 | —60 | | |
| | | | | | |
Простой статистический ряд представляет собой первичную форму записи статистического материала и может быть обработан различными способами. Одним из способов такой обработки является построение статистической функции распределения случайной величины.
Статистической функцией распределения случайной величины X называется частота события X < х в данном статистическом материале:
F*(х) = Р*(Х<х). (7.2.1)
Для того чтобы найти значение статистической функции распределения при данном х, достаточно подсчитать число опытов, в которых величина X приняла значение, меньшее чем х, и разделить на общее число п произведенных опытов.
Пример 2. Построить статистическую функцию распределения для случайной величины р, рассмотренной в предыдущем примере2).
1) Под углом скольжения подразумевается угол, составленный вектором скорости и плоскостью симметрии самолета.
2) Здесь и во многих случаях далее, при рассмотрении конкретных практических примеров, мы не будем строго придерживаться правила — обозначать случайные величины большими буквами, а их возможные значения — соответствующими малыми буквами. Если это не может привести к недоразумениям, мы в ряде случаев будем обозначать случайную величину и ее возможное значение одной и той же буквой.
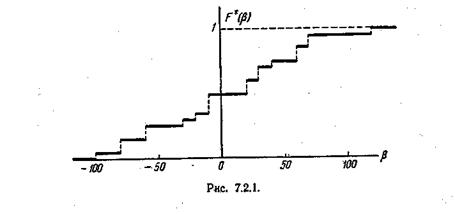
Решение. Так как наименьшее наблюденное значение величины равно—100, то F (—100) = 0. Значение —100 наблюдено один раз, его частота равна
В промежутке от —100 до — 80 функция F*( β) имеет значение
дважды, и т. д.
График статистической функции распределения величины представлен на рис.7.2.1.
Статистическая функция распределения любой случайной величины— прерывной или непрерывной — представляет собой прерывную ступенчатую функцию, скачки которой соответствуют наблюденным значениям случайной величины и по величине равны частотам этих значений. Если каждое отдельное значение случайной величины
X было наблюдено только один раз, скачок статистической функции распределения в каждом наблюденном значении равен
При увеличении числа опытов п, согласно теореме Бернулли, при любом jc частота события X < х приближается (сходится по вероятности) к вероятности этого события. Следовательно, при увеличении п статистическая функция распределения F* (х) приближается (сходится по вероятности) к подлинной функции распределения F (х) случайной величины X.
Если X — непрерывная случайная величина, то при увеличении
числа наблюдений п число скачков функции F* (х) увеличивается,
самые скачки уменьшаются и график функции F* (х)
 |
В принципе построение статистической функции распределения уже решает задачу описания экспериментального материала. Однако при большом числе опытов и построение F* (х) описанным выше способом весьма трудоемко. Кроме того, часто бывает удобно — в смысле наглядности — пользоваться другими характеристиками статистических распределений, аналогичными не функции распределения F(x), а плотности ƒ(x). С такими способами описания статистических данных мы познакомимся в следующем параграфе.
ГЛАВА 2 СТАТИСТИЧЕСКИЙ РЯД
При большом числе наблюдений (порядка сотен) простая статистическая совокупность перестает быть удобной формой записи статистического материала — она становится слишком громоздкой и мало наглядной. Для придания ему большей компактности и наглядности статистический материал должен быть подвергнут дополнительной обработке — строится так называемый «статистический ряд».
Предположим, что в нашем распоряжении результаты наблюдений над непрерывной случайной величиной X, оформленные в виде простой статистической совокупности. Разделим весь диапазон наблюденных значений X на интервалы или «разряды» и подсчитаем количество значений mt, приходящееся на каждый J-й разряд. Это число разделим на общее число наблюдений п и найдем частоту, соответствующую данному разряду:

