Файл: Лекция 01. Основные принципы построения распределенных информационных систем Скворцов С. Е. 15 января 2019.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 26.04.2024
Просмотров: 16
Скачиваний: 0
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.

СОДЕРЖАНИЕ
Лекция № 01. Основные принципы построения распределенных информационных систем
Лекция № 02. Архитектура распределенной обработки данных
Лекция № 03. Программное обеспечение распределенных приложений
Лекция № 04. HTML-формы. Создание форм, объекты и события. Текстовое поле, кнопка. Обработка событий
Лекция № 01. Основные принципы построения распределенных информационных систем
Скворцов С.Е.
15 января 2019
Просмотров: 232
Empty
Такая отличительная особенность баз данных, как многоцелевое параллельное использование данных, предопределяет наличие средств, обеспечивающих практически одновременный и независимый доступ к одним и тем же данным. Причем сама база данных может быть размещена как на одном, так и на нескольких компьютерах.
Общая тенденция развития технологий обработки данных позволяет в настоящее время выделить два класса распределенной обработки данных: системы распределенной обработки данных и системы распределенных баз данных.
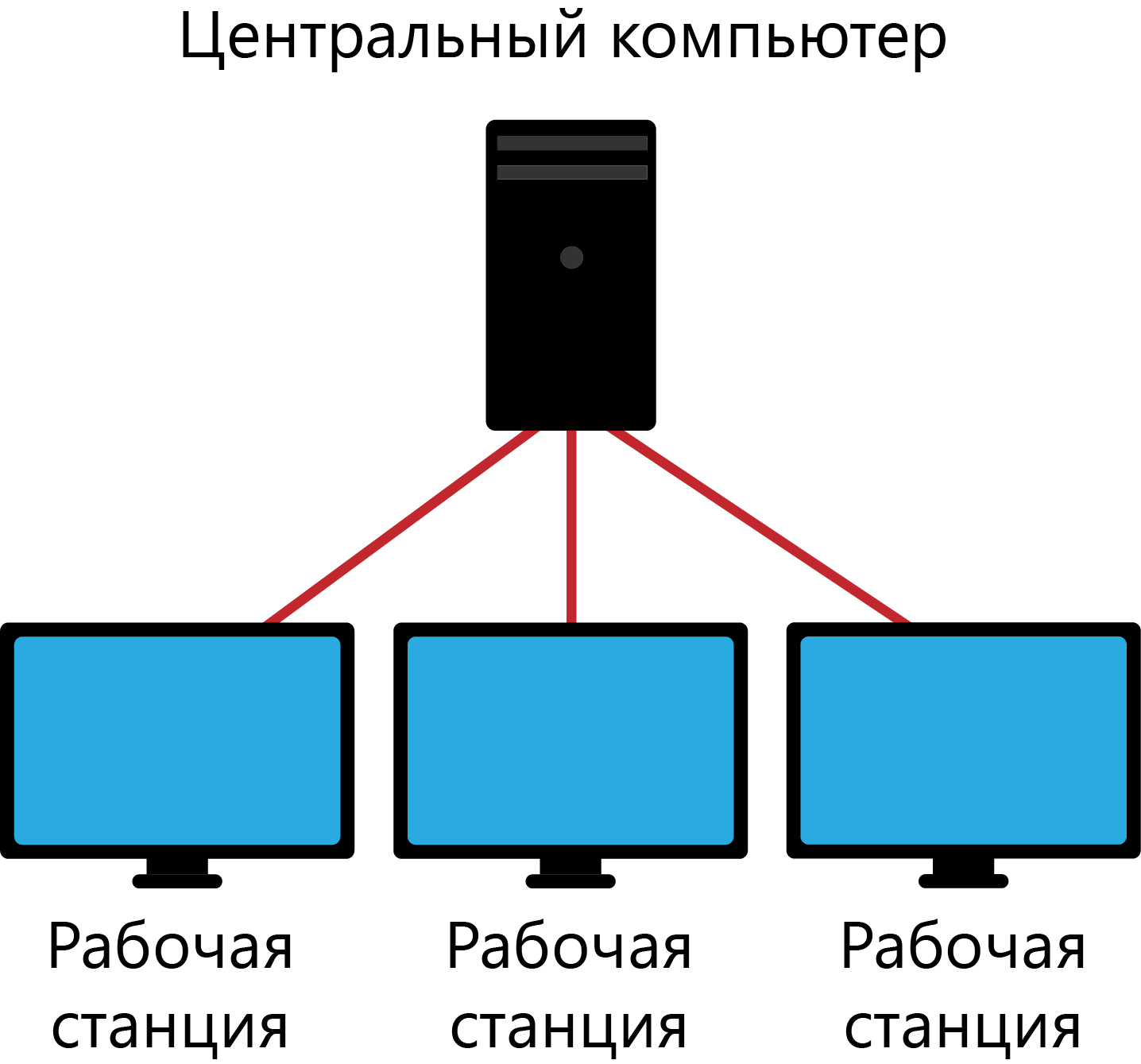
Системы распределенной обработки данных в основном отражают структуру и свойства многопользовательских операционных систем с базой данных, размещенной на центральном компьютере (мэйнфрейм, сервер). Еще до недавнего времени это был единственно возможный вариант вычислительной среды для реализации больших баз данных. Клиентские места могут реализовываться в виде терминалов или мини-ЭВМ, обеспечивающих в основном ввод-вывод данных и не обладающими собственными вычислительными ресурсами (хотя не исключено и использование обычных ПК)Развитием данного направления стоит считать технологию «Клиент-Сервер», позволяющую реализовать различные модели обработки информации в АИС.
Развитие сетевых технологий в сочетании с широким распространением персональных ЭВМ и внедрениям стандартов открытых систем привело к появлению систем баз данных, размещенных в сети разнотипных компьютеров. Такие системы распределенных баз данных обеспечивают обработку распределенных запросов, когда при обработке одного запроса используются ресурсы базы, размещенные в различных узлах сети. Узлы системы взаимодействую между собой так, что база данных любого узла будет доступна пользователю, как если бы она была локальной.
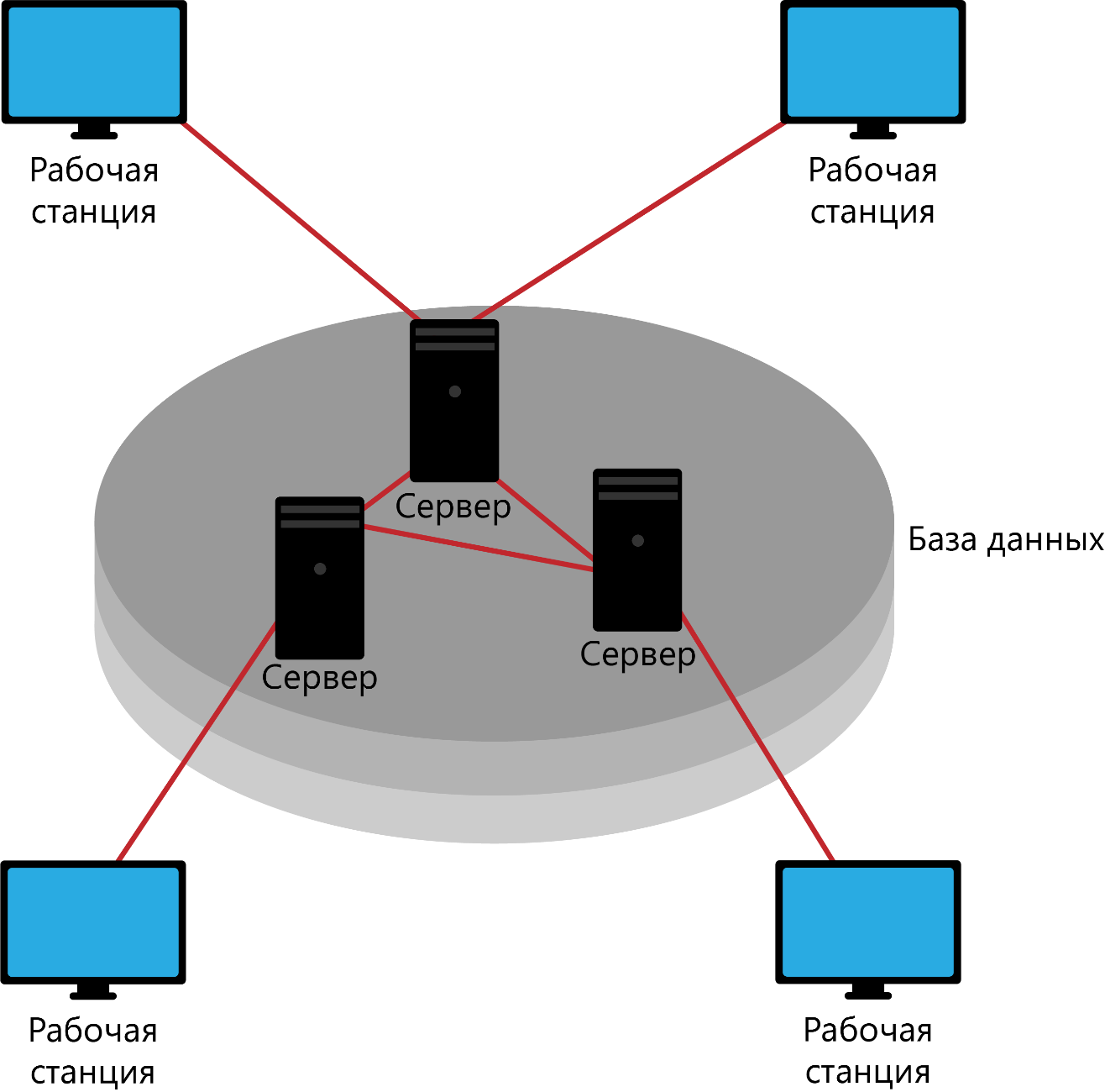
В обоих случаях программы, обеспечивающие обработку данных
, могут быть организованы таким образом, чтобы обеспечить более эффективное использование вычислительных ресурсов за счет разделения функций обработки между центральным процессором сервера БД и клиентскими машинами (1 вариант), либо за счет разделения функций обработки между процессорами узлов СУБД и клиентским машинами (второй вариант).
Для типового приложения обработки данных можно выделить следующие группы функций:
-
Presentation Logic -
Business Logic -
Database Logic -
Управление данными и другими ресурсами БД, реализуемое внутренними средствами СУБД -
Управление процессами обработки: связывание и синхронизация процессов обработки данных разного уровня.
Выделяют следующие, сформулированные ведущими поставщиками СУБД, свойства «идеальной» системы управления распределенными базами данных:
-
прозрачность относительно расположения данных: СУБД должна представлять данные так, как если бы они хранились на локальном компьютере; -
гетерогенность системы: СУБД должна работать с данными, которые хранятся в системах с различной архитектурой и производительностью (независиость от СУБД); -
прозрачность относительно сети: СУБД должна одинаково работать в условиях разнородных сетей; -
поддержка распределенных запросов: пользователь должен иметь возможность объединять данные из любых баз, даже если они размещены в разных системах; -
поддержка распределенных изменений: пользователь должен иметь возможность изменять данные в любых базах, на доступ к которым у него есть права, даже если эти базы размещены в различных системах; -
поддержка распределенных транзакций: СУБД должна выполнять транзакции, выходящие за рамки одной вычислительной системы, и поддерживать целостность распределенной БД даже при возникновении отказов в отдельных системах или в сети; -
безопасность: СУБД должна обеспечивать защиту всей распределенной БД от несанкционированного доступа; -
универсальность доступа: СУБД должна обеспечивать единую методику доступа ко всем данным.
Однако ни одна из существующих СУБД не достигает этого идеала вследствие следующих практических проблем:

· низкая и несбалансированная производительность сетей передачи данных, что в распределенных транзакциях сильно снижает общую производительность обработки;
· обеспечение целостности данных в распределенных транзакциях базируется на принципе «все или ничего», и требует специального протокола двухфазного завершения транзакций, что приводит к длительной блокировке изменяемых данных;
· необходимо обеспечить совместимость данных стандартного типа, для хранения которых в разных системах используются разные форматы и кодировки.
· Выбор схемы размещения системных каталогов. Если каталог будет храниться в одной системе с данными, то удаленный доступ будет замедлен. Если отдельно – изменения придется синхронизировать.
· Необходимо обеспечить совместимость СУБД разных типов и поставщиков
Указанные причины определили на практике частичность и этапность введения в СУБД тех или иных возможностей по распределенной обработке данных. В простейшем случае пользователь имеет возможность обращаться по сети к записям БД, размещенным на другом компьютере. В других случаях сама СУБД производит аутентификацию удаленного пользователя и устанавливает сетевые соединения.
В общем случае режимы работы с БД можно классифицировать по следующим признакам:
-
Многозадачность – однопользовательский или многопользовательский -
Правило обслуживания запросов – последовательное или параллельное -
Схема размещения данных – централизованная или распределенная БД
Лекция № 02. Архитектура распределенной обработки данных
Скворцов С.Е.
15 января 2019
Просмотров: 258
Empty
Почти все модели организации взаимодействия пользователя с базой данных, построены на основе модели "клиент-сервер". Т.е. предполагается, что каждое такое приложение отличается способом распределения функций ранее приведенных групп обработки данных между как минимум двумя частями:
-
клиентской, которая отвечает за целевую обработку данных и организацию взаимодействия с пользователем; -
серверной, которая обеспечивает хранение данных, обрабатывает запросы и посылает результаты клиенту для специальной обработки.
В общем случае предполагается, что эти части приложения функционируют на отдельных компьютерах, т.е. к серверу БД с помощью сети подключены компьютеры пользователей (клиенты).
Сервер – это программа, реализующая функции собственно СУБД: определение данных, запись-чтение данных, поддержка схем внешнего, концептуального и внутреннего уровней, диспетчеризация и оптимизация выполнения запросов, защита данных.
Клиент – это различные программы, написанные как пользователями, так и поставщиками СУБД, внешние или «встроенные» по отношению к СУБД. Программа-клиент организована в виде приложения, работающего «поверх» СУБД, и обращающегося для выполнения операций над данными к компонентам СУБД через интерфейс внешнего уровня.
Разделение процесса выполнения запроса на «клиентскую» и «серверную» компоненту позволяет:
-
различным прикладным (клиентским) программам одновременно использовать общую базу данных; -
централизовать функции управления, такие, как защита информации, обеспечение целостности данных, управление совместным использованием ресурсов; -
обеспечивать параллельную обработку запроса в случае распределенных БД; -
высвобождать ресурсы рабочих станций и сети; -
повышать эффективность управления данными за счет использования компьютера, специально разработанных для работы СУБД (серверы баз данных и машины баз данных).
Базовые архитектуры распределенной обработки
Учитывая, что одним из основных показателей эффективности сетевой обработки данных является время обслуживания запроса, рассмотрим различные модели архитектуры распределенной обработки на примере, когда прикладная программа работы с базой данных, расположенной на сервере, загружена на рабочую станцию, и пользователю необходимо получить все записи, удовлетворяющие некоторым поисковым условиям.
Архитектура «Файл-сервер»
В архитектуре «файл-сервер», схема которой представлена на рисунке 1, средства организации и управления базой данных (в том числе и СУБД) целиком располагаются на машине клиента, а база данных, представляющая собой обычно набор специализированных структурированных файлов, на машине-сервере. В этом случае серверная компонента представлена даже не средствами СУБД, а сетевыми составляющими операционной системы, обеспечивающими удаленный разделяемый доступ к файлам. Таким образом, «файл-сервер» представляет собой вырожденный случай клиент-серверной архитектуры.
Взаимодействие между клиентом и сервером происходит на уровне команд ввода-вывода файловой системы, которая возвращает запись или блок данных. Запрос к базе, сформулированный на языке манипулирования данными, преобразуется самой СУБД в последовательность команд ввода-вывода, которые обрабатываются операционной системой машины-сервера.
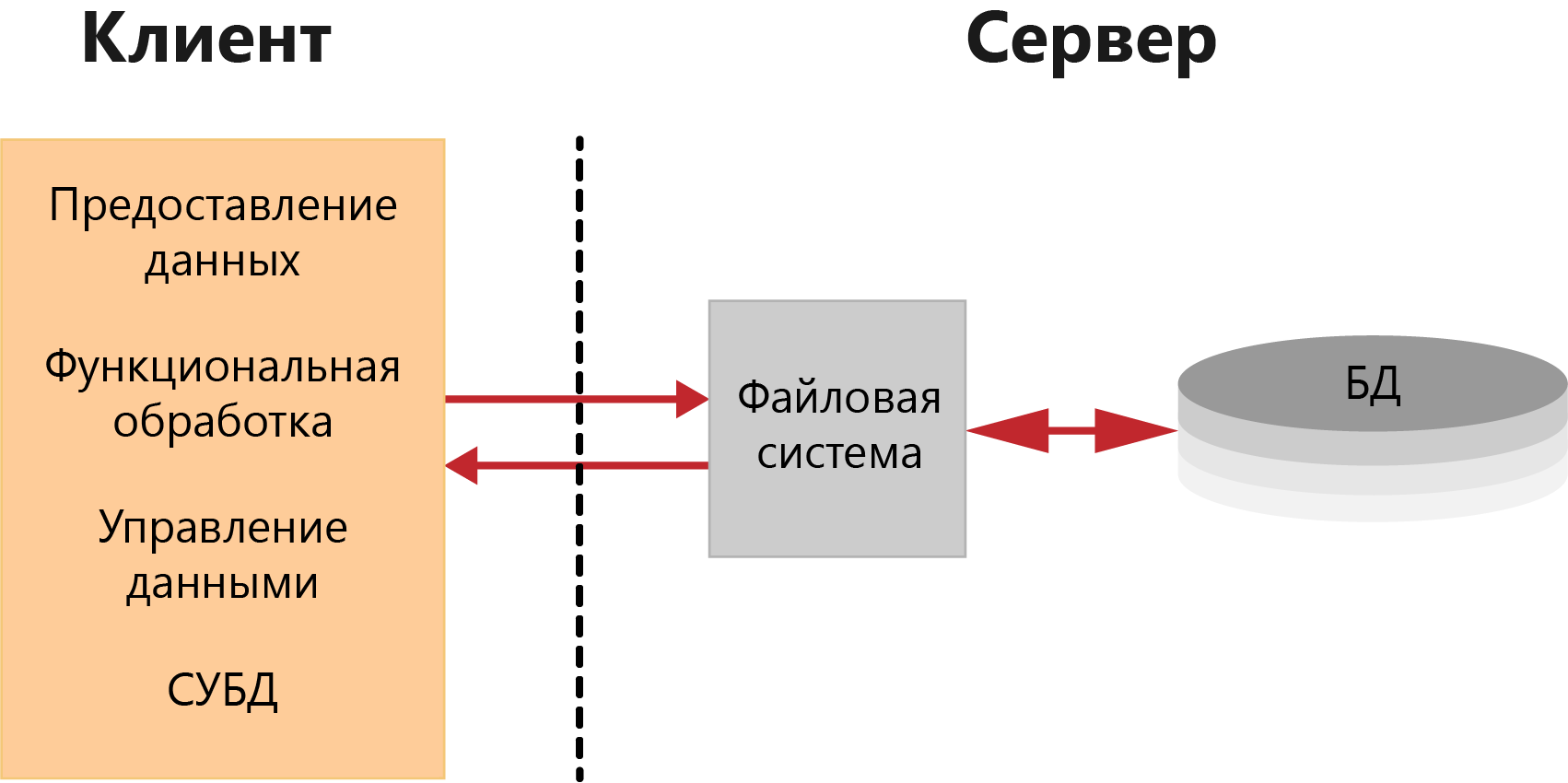
Рисунок 1 - Архитектура «файл-сервер»
Достоинство - возможность обслуживания запросов нескольких клиентов.
Недостатки:
-
высокая загрузка сети и машин-клиентов, т.к. обмен идет на уровне единиц информации файловой системы – физических записей, блоков или даже файлов, из которых на машине клиента будут выбраны и представлены необходимые для приложения элементы данных; -
низкий уровень защиты данных, т.к. доступ к файлам БД управляется общими средствами ОС сервера; -
низкий уровень управления целостностью и непротиворечивостью информации, т.к. бизнес-правила функциональной обработки, сосредоточенные на клиентской части, могут быть противоречивыми и несихронизированными.