Файл: Лекция 01. Основные принципы построения распределенных информационных систем Скворцов С. Е. 15 января 2019.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 26.04.2024
Просмотров: 19
Скачиваний: 0
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.

СОДЕРЖАНИЕ
Лекция № 01. Основные принципы построения распределенных информационных систем
Лекция № 02. Архитектура распределенной обработки данных
Лекция № 03. Программное обеспечение распределенных приложений
Лекция № 04. HTML-формы. Создание форм, объекты и события. Текстовое поле, кнопка. Обработка событий
В среде файлового сервера программа управления данными, которая выполняется на машине-клиенте, должна осуществить запрос каждой записи базы, после чего она может определить, удовлетворяет ли запись поисковым условиям, лишь после этого передать для функциональной обработки. Очевидно, что для этой схемы характерно наибольшее суммарное время обработки информации.
Архитектура «Выделенный сервер базы данных»
В архитектуре сервера базы данных, схема которой представлена на рисунке 2, средства управления базой данных и база данных размещены на машине-сервере.
Взаимодействие между клиентом и сервером происходит на уровне команд языка манипулирования данными СУБД (обычно SQL), которые обрабатываются СУБД на машине-сервере. Сервер базы данных осуществляет поиск записей и анализирует их. Записи, удовлетворяющие условиям, могут накапливаться на сервере и после того, как запрос будет целиком обработан, пользователю на клиентскую машину передаются все логические записи (запрашиваемые элементы данных), удовлетворяющие поисковым условиям.
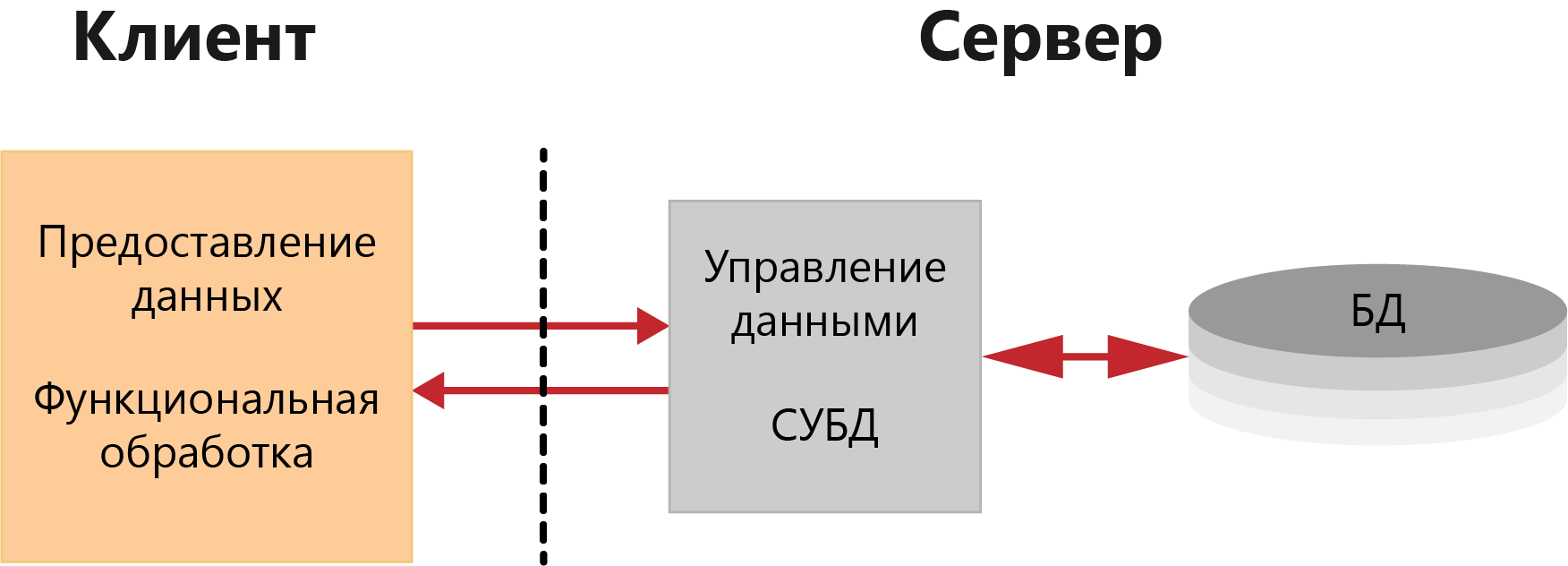
Рисунок 2 - Архитектура с выделенным сервером базы данных
Достоинства:
-
возможность обслуживания запросов нескольких клиентов; -
снижение нагрузки на сеть и машины сервера и клиентов; -
защита данных осуществляется средствами СУБД, что позволяет блокировать неразрешенные пользователю действия; -
сервер реализует управление транзакциями и может блокировать попытки одновременного изменения одних и тех же записей.
Недостатки:
-
бизнес-логика функциональной обработки и представление данных могут быть одинаковыми для нескольких клиентских приложений и это увеличит совокупные потребности в ресурсах при исполнении – повторение части кода программ и запросов; -
низкий уровень управления непротиворечивостью информации, т.к. бизнес-правила функциональной обработки, сосредоточенные на клиентской части, могут быть противоречивыми. -
данная технология позволяет снизить сетевой трафик и повысить общую эффективность обработки за счет оптимизации и буферизации ввода-вывода. Т.о., сервер может осуществить поиск и обрабатывать запросы даже быстрее, чем, если бы они обрабатывались на рабочей станции.
Архитектура «Активный сервер баз данных»
Для того чтобы устранить недостатки, свойственные архитектуре сервера базы данных необходимо, чтобы непротиворечивость бизнес-логики и изменения базы данных контролировались на стороне сервера. Причем некоторые, заранее специфицированные состояния могли бы изменять последовательность взаимодействия приложения с базой данных.
Для этого функции бизнес-логики разделяются между клиентской и серверной частью. Общие или критически значимые функции оформляются в виде хранимых процедур, включаемых в состав базы данных. Кроме этого, вводится механизм отслеживания событий БД – триггеров, также включаемых в состав базы. При возникновении соответствующего события (обычно изменения данных), СУБД вызывает для выполнения хранимую процедуру, связанную с триггером, что позволяет эффективно контролировать изменение базы данных.
Хранимые процедуры и триггеры могут быть использованы любыми клиентскими приложениями, работающими с базой данных. Это снижает дублирование программных кодов и исключает необходимость компиляции каждого запроса (рисунок 3).
Недостатком такой архитектуры становится существенно возрастающая загрузка сервера за счет необходимости отслеживания событий и выполнения части бизнес-правил.
Такую архитектуру организации взаимодействия (а также рассматриваемый далее сервер приложений) иногда называют моделью с «тонким клиентом», в отличие от предыдущих архитектур, называемых моделью с «толстым клиентом», где на стороне клиента выполняется большинство функций.

Рисунок 3 - Архитектура «активный сервер баз данных»
Архитектура «Сервер приложений»
Рассмотренные выше архитектуры являются двухзвенными: здесь все функции доступа и обработки распределены между программой клиента и сервером БД.
Дальнейшее снижение требований к ресурсам клиента достигается за счет введения промежуточного звена – сервера приложений, на который переносится значительная часть программных компонентов управления данными и большая часть бизнес-логики. При этом серверы баз данных обеспечивают исключительно функции СУБД по ведению и обслуживанию базы данных. Схема трехзвенной архитектуры сервера приложений приведена на рисунок 4.


Рисунок 4 - Архитектура сервера приложений
К другим (организационно-технологическим) достоинствам трехзвенной архитектуры можно отнести:
-
централизованное ведение бизнес-логики и в случае их изменения отсутствие необходимости их тиражирования в клиентских приложениях; -
отсутствие необходимости устанавливать на клиентских машинах компонент программного обеспечения управления доступом к данным; -
возможность отложенного обновления БД в случае изменения данных, запрошенных с сервера, в автономном режиме. Данные будут обновлены в базе после следующего соединения клиентской программы с сервером приложений.
Архитектура сервера баз данных
Повышение эффективности и оперативности обслуживания большого числа клиентских запросов, помимо простого увеличения ресурсов и вычислительной мощности серверной машины, может быть достигнуто двумя путями:
-
снижением суммарного расхода памяти и вычислительных ресурсов за счет буферизации (кэширования) и совместного использования (разделяемые ресурсы) наиболее часто запрашиваемых данных и процедур; -
распараллеливанием процесса обработки запроса – использованием разных процессоров для параллельной обработки изолированных подзапросов и/или для одновременного обращения к частям базы данных, размещенным на отдельных физических носителях.
Рассмотрим архитектуры, реализующие следующие модели совместной обработки клиентских запросов.
Архитектура «один к одному»
В этом случае (рисунок 5) для обслуживания каждого запроса запускается отдельный серверный процесс.Таким образом, даже если от клиентов поступят совершенно одинаковые запросы, для обработки каждого из них будут запущены отдельные процессы, каждый из которых будет выполнять одинаковые действия и использовать одни и те же ресурсы.
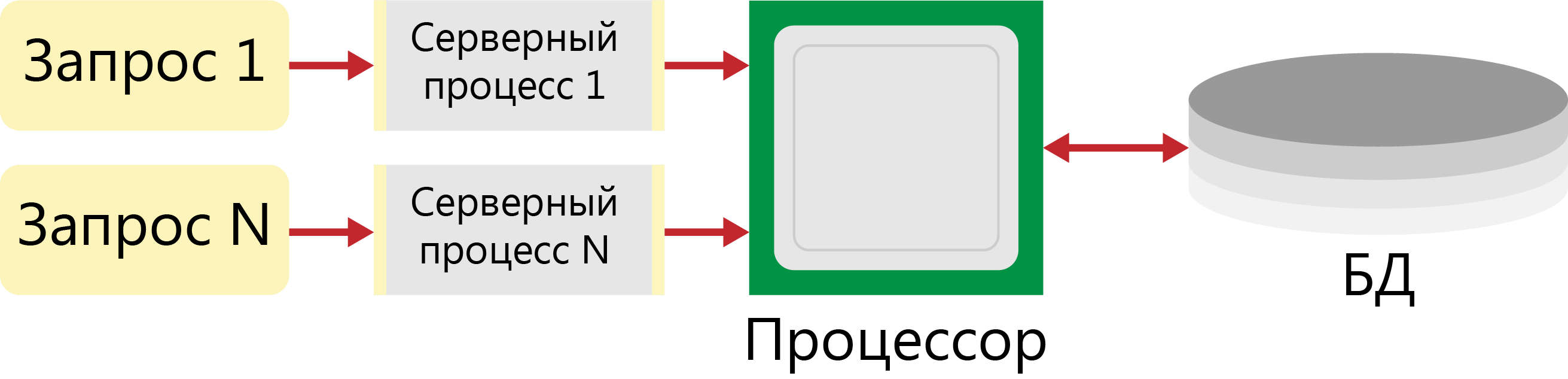 Рисунок 5 - Архитектура сервера «один к одному»
Рисунок 5 - Архитектура сервера «один к одному»Многопотоковая односерверная архитектура
Обработку всех клиентских запросов выполняет один серверный процесс (использующий один процессор), взаимодействующий со всеми клиентами и монопольно управляющий ресурсами (рисунок 6). При этом для отдельного клиентского процесса создается поток, (thread) в рамках которого локализуется обработка запроса.
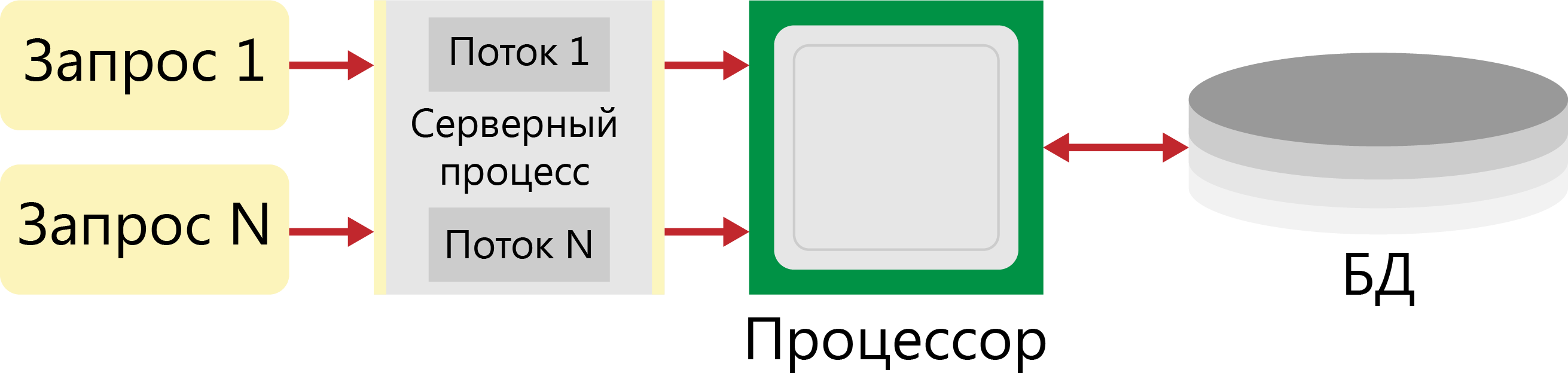 Рисунок 6 - Многопотоковая односерверная архитектура
Рисунок 6 - Многопотоковая односерверная архитектураМультисерверная архитектура
В том случае, когда для работы СУБД используются многопроцессорные платформы, обслуживание запросов может быть физически распределено для параллельной обработки между процессорами. Такое решение (рисунок 7) требует введения дополнительного звена, в задачи которого входит диспетчеризация запросов для обеспечения сбалансированной загрузки процессоров.
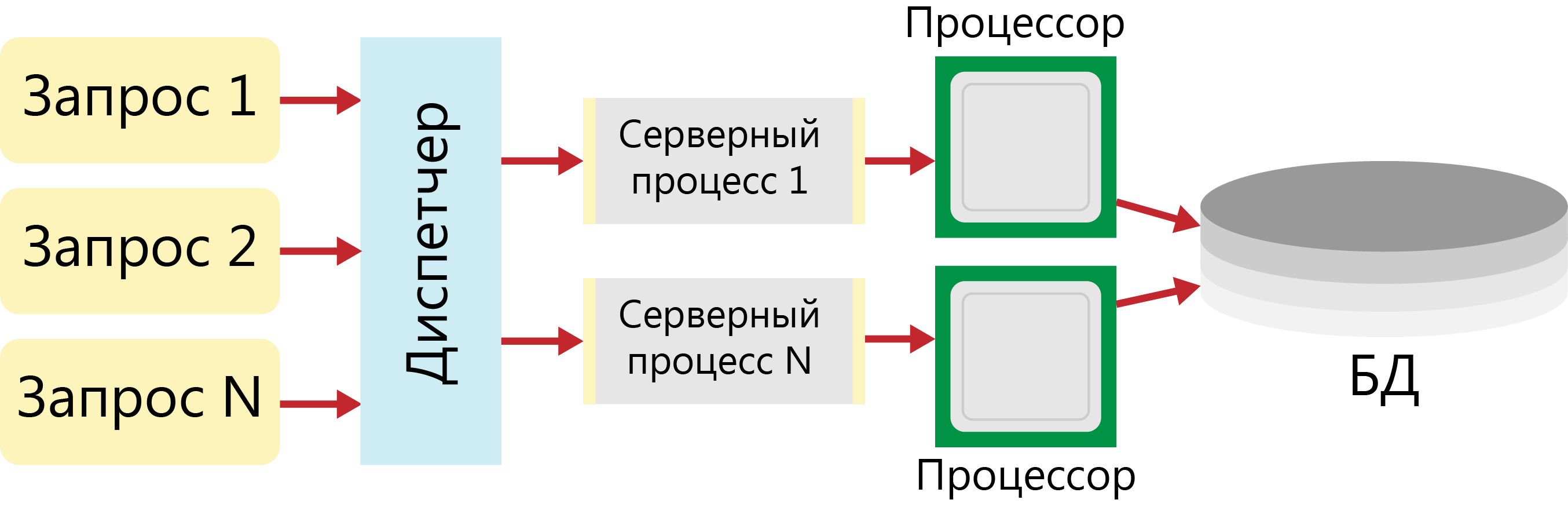
Рисунок 7 - Многопотоковая односерверная архитектура
В том случае, когда серверный процесс реализуется как многопоточное приложение, говорят, что СУБД имеет мультисерверную многопотоковую архитектуру.
Следует отметить, что характер распределения запросов в значительной степени зависит от того, поддерживает ли операционная система потоковую обработку, а также от возможностей средств управления приоритетами задач.
Серверные архитектуры с параллельной обработкой запроса
Для повышения оперативности за счет распараллеливания процесса обработки отдельного клиентского запроса в мультисерверной архитектуре можно использовать следующие подходы:
-
Размещение хранимых данных БД на нескольких физических носителях (сегментирование базы). Для обработки запроса в этом случае запускаются несколько серверных процессов (использующих обычно отдельные процессоры), каждый из которых независимо от других выполняет одинаковую последовательность действий, определяемую существом запроса, но с данными, принадлежащими разным сегментам базы. Полученные таким образом результаты объединяются и передаются клиенту. Такой тип распараллеливания называют моделью горизонтального параллелизма. -
Запрос обрабатывается по конвейерной технологии. Для этого запрос разбивается на взаимосвязанные по результатам подзапросы, каждый из которых может быть обслужен отдельным серверным процессом независимо от обработки других подзапросов. Получаемые результаты объединяются согласно схеме декомпозиции запроса и передаются клиенту. Такой тип распараллеливания называют моделью вертикального параллелизма.
Примерная схема обработки клиентского запроса, построенная с использование обеих моделей параллелизма (гибридная модель) приведена на рисунке 8.
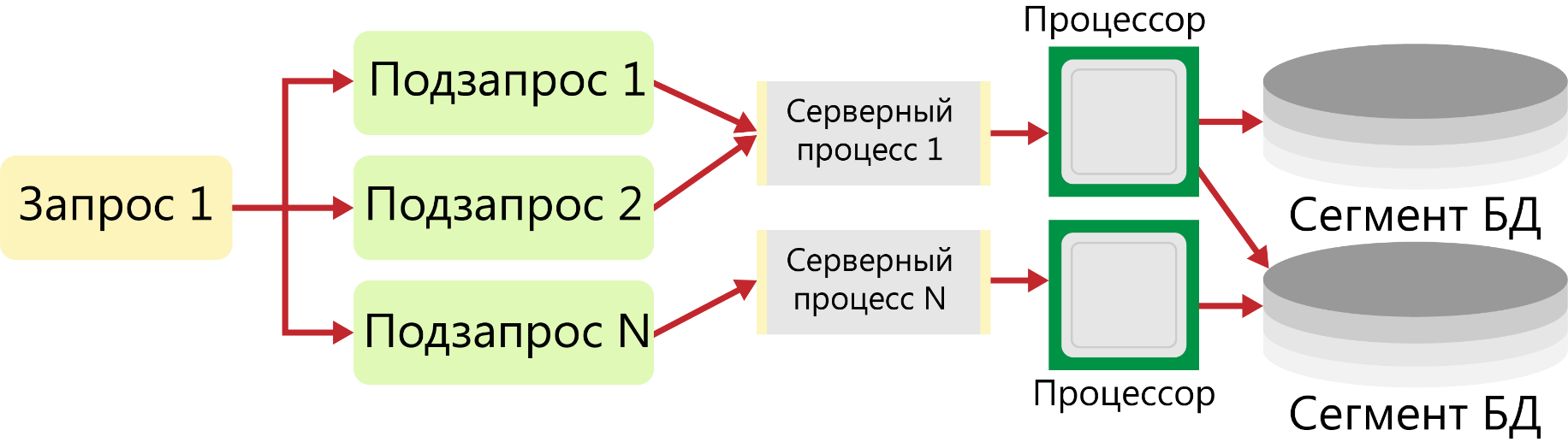 Рисунок 8 - Архитектура сервера обработки запроса при гибридном параллелизме
Рисунок 8 - Архитектура сервера обработки запроса при гибридном параллелизмеИспользование моделей параллельной обработки позволяет существенно сократить общее время обслуживания запроса, что особенно важно в случае работы с большими базами данных и аналитической обработки (OLAP-приложений).