Файл: Лекция 01. Основные принципы построения распределенных информационных систем Скворцов С. Е. 15 января 2019.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 26.04.2024
Просмотров: 17
Скачиваний: 0
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.

СОДЕРЖАНИЕ
Лекция № 01. Основные принципы построения распределенных информационных систем
Лекция № 02. Архитектура распределенной обработки данных
Лекция № 03. Программное обеспечение распределенных приложений
Лекция № 04. HTML-формы. Создание форм, объекты и события. Текстовое поле, кнопка. Обработка событий
Лекция № 03. Программное обеспечение распределенных приложений
Скворцов С.Е.
18 января 2019
Просмотров: 209
Empty
Распределенные корпоративные приложения всё более усложняются, интегрируя в себя унаследованные приложения, разрабатываемые и вновь приобретаемые готовые программные средства. Кроме того, разные подсистемы решают разные бизнес-задачи, однако одна из главных целей создания корпоративной системы – получить «единый образ» общего состояния системы, что обеспечит пользователям доступ к нужным операциям и ресурсам.
Основа такой инфраструктуры – так называемое промежуточное программное обеспечение, позволяющее, не вникая в тонкости сетевых реализаций, создавать и эксплуатировать взаимодействующие между собой приложения с разными требованиями к межмодульным коммуникациям.
Промежуточное ПО эволюционировало вместе с архитектурой клиент-сервер. Ранние, но достаточно эффективные как с точки зрения разработки, так и эксплуатации, частные решения предназначались для упрощения доступа к БД в двухзвенной модели, где «толстый» клиент реализует всю логику обработки информации, предоставляемой сервером БД. Такие системы вполне удовлетворяли потребностям небольших корпоративных подразделений с ограниченным числом пользователей и невысокой интенсивностью обмена.
Однако, по мере того, как клиент-серверная архитектура стала проникать в сферу высококритичных корпоративных приложений, обслуживающих уже не десятки, а сотни пользователей и работающих со значительными массивами данных, стали очевидны недостатки двухзвенного подхода. Этот способ реализации клиент-серверной схемы доступа ограничивал возможности масштабирования, поскольку увеличение числа обращений к одной БД непомерно увеличивало нагрузку на сервер и делало доступ к данным «узким местом» в общей производительности системы. Кроме того, всякая модификация логики приложения требовала внесения изменений во все экземпляры клиентских приложений.
Чтобы избежать таких проблем, для разработки корпоративных приложений используют трёхзвенную модель, которая переносит логику приложения на отдельный уровень сервера приложений. В результате клиентская часть приложения становится «тоньше» и в основном отвечает за предоставление удобного пользовательского интерфейса. Как правило, сервер баз данных также освобождается от
необходимости поддерживать бизнес-логику, которая в двухзвенной модели реализуется с помощью специальных расширений СУБД, например, хранимых процедур. Перенос основных операций приложения на отдельный уровень позволяет с максимальной эффективностью распределить нагрузку на аппаратные средства (трёхзвенная модель на самом деле может быть многозвенной с разделением нагрузки на несколько серверов приложений) и обеспечивает безболезненное наращивание как функциональности приложения, так и числа обслуживаемых пользователей.
Развитие этого среднего звена клиент-серверной модели идёт в сторону усложнения. Ограничиваясь вначале построением более высокого уровня абстракции для взаимодействия приложения с ресурсами данных, разработчик приложения получал возможность использовать общие API (ApplicationProgramInterface), которые скрывали различия специфических интерфейсов коммуникационных протоколов более низкого уровня, например, TCP/IP, Sockets или DECNet. Однако теперь этого явно недостаточно для построения сложных распределенных приложений. Современные решения не только обеспечивают межпрограммное взаимодействие, но и являются платформой для реализации сервера приложений, обеспечивая обширный набор необходимых служб: управления транзакциями, именования, защиты и т.д.
Вычислительная среда распределённых приложений может включать в себя различные операционные системы, аппаратные платформы, коммуникационные протоколы и разнообразные средства разработки. Соответственно, формат представления данных в различных узлах будет различаться.
Таким образом, в распределённой неоднородной среде программное обеспечение промежуточного уровня играет роль «информационной шины», надстроенной над сетевым уровнем и обеспечивающей доступ приложения к разнородным ресурсам, а также независимую от платформ взаимосвязь различных прикладных компонентов, изолирующую логику приложений от уровня сетевого взаимодействия и ОС.
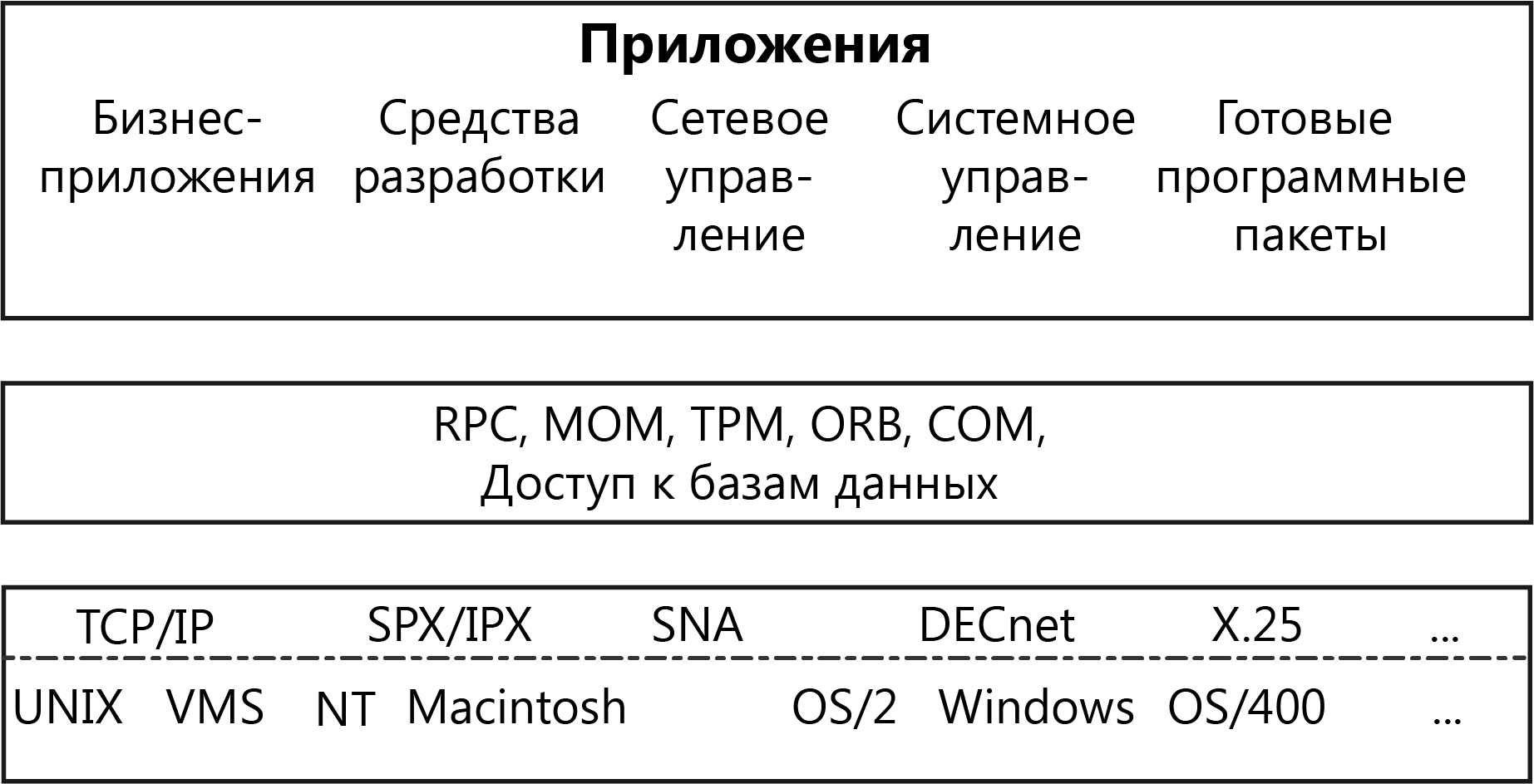
Рисунок 1 - Структура компонент поддержки удаленного доступа
ПО промежуточного уровня можно разделить на две категории:
-
ПО доступа к БД (например, ODBC-интерфейсы и SQL-шлюзы); -
ПО межмодульного взаимодействия – системы, реализующие вызов удаленных процедур (RPC – RemoteProcedureCall); мониторы обработки транзакций (TP-мониторы); средства интеграции распределенных объектов.

При этом различия прикладных задач не позволяют построить универсальное ПО, реализовав в одном продукте все необходимые возможности.
Доступ к базам данных в двухзвенных моделях клиент-сервер
В простых двухзвенных моделях клиент-сервер, где несколько БД обслуживают ограниченное число пользователей настольных ПК, в роли встроенного ПО доступа к данным могут выступать обычные ODBC-драйверы.
Необходимость в более сложных решениях возникает в больших, разнородных многозвенных системах, где множество приложений в параллельном режиме осуществляет доступ к разнообразным источникам данных, включая разнотипные СУБД и хранилища данных. В таких системах между клиентами и серверами баз данных размещается промежуточное звено – SQL-шлюз, представляющий набор общих API, позволяющих разработчику строить унифицированные запросы к разнородным данным (в формате SQL или с помощью ODBC-интерфейса). SQL-шлюз выполняет синтаксический разбор такого запроса, анализирует и оптимизирует его и, в конце концов, выполняет преобразование в SQL-диалект нужной СУБД. ПО этого типа реализует синхронный механизм связи, когда выполнение приложения, сделавшего запрос, блокируется до момента получения данных.
Пример такого приложения – система анализа статистических данных о деятельности компаний, отбирающая соответствующую информацию из расположенных в различных регионах БД с разными СУБД. Подобные решения достаточно просты, не требуют сложных механизмов управления транзакциями и способны обеспечить постепенную миграцию важных приложений с унаследованных платформ в архитектуру клиент-сервер.
Каждое приложение, построенное на основе архитектуры «клиент-сервер», включает, как минимум, две части:
-
клиентскую часть, отвечающую за целевую обработку данных и организацию взаимодействия с пользователем; -
серверную часть, собственно хранящую данные, обрабатывающую запросы и посылающую результаты клиенту для специальной обработки.
В общем случае предполагается, что эти части приложения функционируют на отдельных компьютерах, т.е. к выделенному серверу БД с помощью сети подключены узлы – компьютеры пользователей (клиенты). При этом узел-клиент сам может быть СУБД.
Создается такое приложение обычно с использованием средств языков высокого уровня (например, C++, Pascal, VisualBasic), позволяющих реализовать эффективную целевую обработку данных и дружественный пользовательский интерфейс. В исходный текст программы включаются SQL-выражения, специфицирующие условия выборки или изменения данных в базе. Во время исполнения приложения эти выражения передаются серверу, который собственно и манипулирует данными. Данные, полученные в результате выполнения сервером SQL-запросов, возвращаются прикладной программе и размещаются в заранее определенных структурах для дальнейшей обработки, в том числе корректировки записей.
Рассмотрим различные способы организации доступа прикладной программы к серверу базы данных в двухзвенной архитектуре.
Использование библиотек доступа и встраиваемого SQL
Каждая СУБД помимо интерактивной SQL-утилиты обязательно имеет библиотеку процедур доступа и набор драйверов СУБД для различных операционных систем. Схема взаимодействия клиентского приложения с сервером базы данных в этом случае представлена на рисунке ниже.
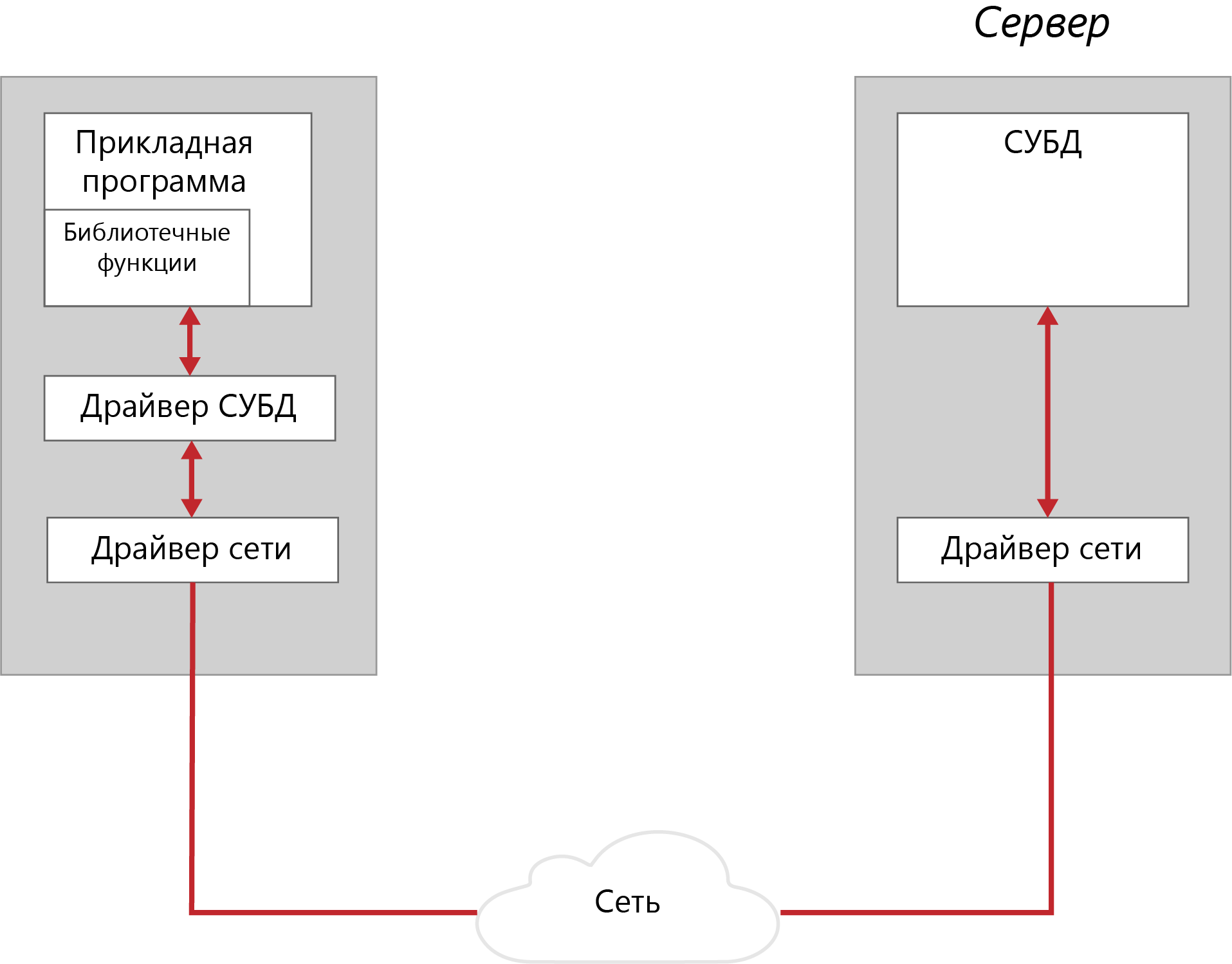
Рисунок 2 - Схема взаимодействия с использованием библиотек процедур доступа
Библиотека доступа содержит набор функций, позволяющих клиентскому приложению соединяться с БД, передавать запросы серверу и получать данные – результаты обработки запроса. Типичный набор функций такой библиотеки включает:
-
соединение с БД; -
запрос к БД на выполнение SQL-выражения; -
запрос на извлечение данных; -
запрос на изменение данных; -
закрытие соединения с БД.
Обычно в библиотеке присутствуют также функции, позволяющие определить характеристики структуры набора результата (число, порядок и имена столбцов, число строк, номер текущей строки), передвигаться по этой структуре не только вперед, но и назад и т.д.
Библиотечные вызовы преобразуются драйвером БД в сетевые вызовы и передаются сетевым ПО на сервер. На сервере происходит обратный процесс преобразования сетевых пакетов в SQL-запросы, которые обрабатываются СУБД. Результаты обработки передаются клиенту.
Такой способ создания приложений достаточно гибок и позволяет реализовать практически любое приложение, однако имеет и недостатки:
-
разработка клиентской программы возможна только для той ОС и на том языке программирования, в которых поддерживается библиотека; -
драйвер БД определяет допустимые типы сетевых интерфейсов; -
библиотечные функции обычно неунифицированы.
Некоторой модификацией данного способа является использование «встроенного» языка SQL. В этом случае текст программы на языке третьего поколения вместо вызовов функций библиотеки включает непосредственно предложения SQL, которые предваряются выражением «EXEC SQL». Перед компиляцией в машинный код такая программа обрабатывается препроцессором, который транслирует смесь операторов «собственного» языка СУБД и SQL-предложений в промежуточный «чистый» исходный код, а затем коды SQL замещаются вызовами соответствующих процедур из библиотек, поддерживающих конкретную СУБД. Такой подход позволяет несколько снизить степень привязанности к СУБД, например, при переключении ПП на работу с другим сервером базы данных – достаточно указать новый сервер и заново перекомпилировать программу.
Программный интерфейс уровня вызовов
Стандарт SQL2 определил интерфейс уровня вызова (CLI – Call Level Interface), в котором стандартизован общий набор рабочих процедур, обеспечивающий совместимость со всеми основными типами серверов баз данных.
Технологическая основа CLI – размещаемая на компьютере клиента специальная библиотека, хранящая вызовы процедур и сетевых компонентов для организации связи с сервером. Это ПО поставляется обычно в составе среды разработки и поддерживает разнообразные сетевые протоколы.
Использование программных вызовов позволяет свести к минимуму операции на компьютере-клиенте. В общем случае клиент формирует оператор языка SQL в виде строки и пересылает её на сервер посредством процедуры исполнения (execute). Когда же сервер в качестве ответа возвращает несколько строк данных, клиент считывает результат последовательным вызовом процедуры выборки данных. Далее данные из столбцов полученной таблицы могут быть связаны с соответствующими переменными приложения. Вызов специальной процедуры позволяет клиенту определить число полученных строк, столбцов и типы данных в каждом столбце.
Открытый интерфейс доступа к базам данных
Спецификация открытого интерфейса баз данных (ODBC – Open Database Connectivity), предназначена для унификации доступа к данным, размещённым на удалённых серверах. ODBC опирается на спецификации CLI.
ODBC представляет программный слой, унифицирующий интерфейс взаимодействия приложений с БД. За реализацию особенностей доступа к каждой отдельной СУБД отвечает соответствующий специальный ODBC-драйвер. Пользовательское приложение этих особенностей не видит, т.к. взаимодействует с универсальным программным слоем более высокого уровня. Таким образом, приложение становится в значительной степени независимым от СУБД. Вместо создания в каждом отдельном случае СУБД-приложения с обращениями через «родной», но быстро устаревающий интерфейс, можно использовать один общий стандартизированный программный интерфейс.
В архитектуре ODBC используется один ODBC Driver Manager и несколько ODBC-драйверов, обеспечивающих доступ к конкретным СУБД. DriverManager связывает приложение и интерфейсные объекты, которые выполняют обработку SQL-запросов к конкретной СУБД.