ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 06.02.2024
Просмотров: 12
Скачиваний: 0
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.

Министерство науки и высшего образования РФ
Федеральное государственное бюджетное образовательно учреждение высшего образования
«Тульский государственный университет»
Институт прикладной математики и компьютерных наук
Кафедра прикладной математики и информатики
Параллельное программирование с использованием технологии OpenMP
Отчёт по лабораторной работе №1
по курсу «Вычислительные системы»
Выполнил:
студент гр. 221211 Евтушенко Дарья
Проверил:
Скобельцын Сергей Алексеевич
Тула 2023
Цель работы:
Получение навыков параллельного программирование с использованием технологии OpenMP средствами Microsoft Visual Studio C++.
Задание на работу
На языке программирования C++ с использованием технологии OpenMP разработать программу, которая находит число вхождений подстроки s в строку символов S.
Теоретические сведения
Программа должна содержать минимум 2 функции с одинаковым интерфейсом, одна из которых должна решать задачу в последовательной технологии, а другая – в параллельной технологии OpenMP. Должен быть реализован механизм сравнения результатов этих двух функций и времени их работы для одних и тех же данных и, по возможности, при одном запуске программы.
OpenMP (Open Multi-Processing) — технология программирования многопоточных приложений на многопроцессорных системах с общей памятью. В соответствии с классификацией архитектур ЭВМ по признакам наличия параллелизма в потоках команд и данных, предложенной Майклом Флинном в 1966 году, технологию OpenMP относят к средствам организации параллельных вычислений с одиночным потоком команд и множественным потоком данных — ОКМД (в оригинале – SIMD – Single Instruction, Multiple Data).
Предварительно в функции sum_P вызывается OpenMP-функция omp_set_num_threads(NUM_PROC); которая устанавливает число потоков, которые будут организованы в блоке после дерективы #pragma omp parallel. Заметим, что число потоков не обязательно должно совпадать с числом процессоров NUM_PROC в системе.
Для оценки и сравнения времени работы “последовательной” функции sum_S и “параллельной” функции sum_P до вызова каждой из функций и после ее завершения фиксируется время с помощью OpenMP-функции omp_get_wtime().
Переменная S введена в глобальном контексте функции sum_P с начальным значением 0. В начале параллельного блока (в директиве #pragma omp parallel) переменная S объявляется в опции verb!reduction(+:S)!.
Это организует использование переменная S в каждом потоке таким образом:
– в потоке создается локальная копия переменной S;
– её начальное значение устанавливается в 0;
– по завершении выполнения параллельного блока значения локальных переменных S прибавляются к глобальной переменной S.
При начальном значении 0 глобальной переменной S это обеспечивает “автоматическое” слияние в ней числа вхождений подстроки в строку. Остается передать ее значение в качестве возвращаемого из функции.
Ход работы
Создадим командный файл. Текст внутри файла cc.bat:
@SET MSVC=C:\MSVC\
@SET INCLUDE=%MSVC%\include;%MSVC%\sdk\v7.1A\Include
@SET PATH=%MSVC%\bin\;%MSVC%\sdk\v7.1A\Bin\
@SET LIB=%MSVC%\lib\;%MSVC%\sdk\v7.1A\Lib\
@SET LIBPATH=%MSVC%\lib\;%MSVC%\sdk\v7.1A\Lib\
cl.exe /nologo /c /EHsc /openmp %1
link.exe /NOLOGO /SUBSYSTEM:CONSOLE /MACHINE:X86 %
n1.obj msvcrt.lib kernel32.lib user32.lib gdi32.lib shell32.lib /NODEFAULTLIB:libcmt.lib
Листинг программы
#include
#include
using namespace std;
#include
#include
const int N=200000;
int NUM_PROC;
double sum_S()
{ string s1("dffffsg%sffgsrrddffffsg%sffgsrrddffffsg%sffgsrrddffffsg%sffgsrrddff%ffsgsffgsrrd"), s2("%");
size_t cnt = 0; int c;
string::size_type i;
for(i = 0; i < s1.length(); ++i)
{ if(s1[i] == s2[0]);
c=i;
if(s1.substr(c, s2.length()) == s2)
{
++cnt;
c+= s2.length() - 1;
}
}
return cnt;
} // sum_S
double sum_P()
{string s1("dffffsg%sffgsrrddffffsg%sffgsrrddffffsg%sffgsrrddffffsg%sffgsrrddff%ffsgsffgsrrd"), s2("%");
size_t cnt = 0; int c,a;
string::size_type i; a=i;
omp_set_num_threads(NUM_PROC);
#pragma omp parallel reduction(+:cnt)
{
#pragma omp for
for(a = 0; a < s1.length(); ++a)
{ if(s1[i] == s2[0]);
c=a;
if(s1.substr(c, s2.length()) == s2)
{
++cnt;
c+= s2.length() - 1;
}
}
}
return cnt;
} // sum_P
int main()
{ double time_1, time_2, S=0;
double otn, otn1, otn2;
NUM_PROC=omp_get_num_procs();
printf_s("Procs = %d _OPENMP=%d\n",NUM_PROC, _OPENMP);
time_1 = omp_get_wtime();
for (int b=0; b
time_2 = omp_get_wtime();
otn1=time_2-time_1;
printf_s("Time_s = %18.15f; Ss=%g (exact)\n",time_2-time_1,S);
time_1 = omp_get_wtime();
for (int b=0; b
time_2 = omp_get_wtime();
otn2=time_2-time_1;
printf_s("Time_p = %18.15f; Sp=%g\n",time_2-time_1,S);
otn= (otn1)/(otn2);
cout << "Vhogdeniy: " << S <<'\n' << "otnS>otnP v =" << otn << '\n';
return 0;
}
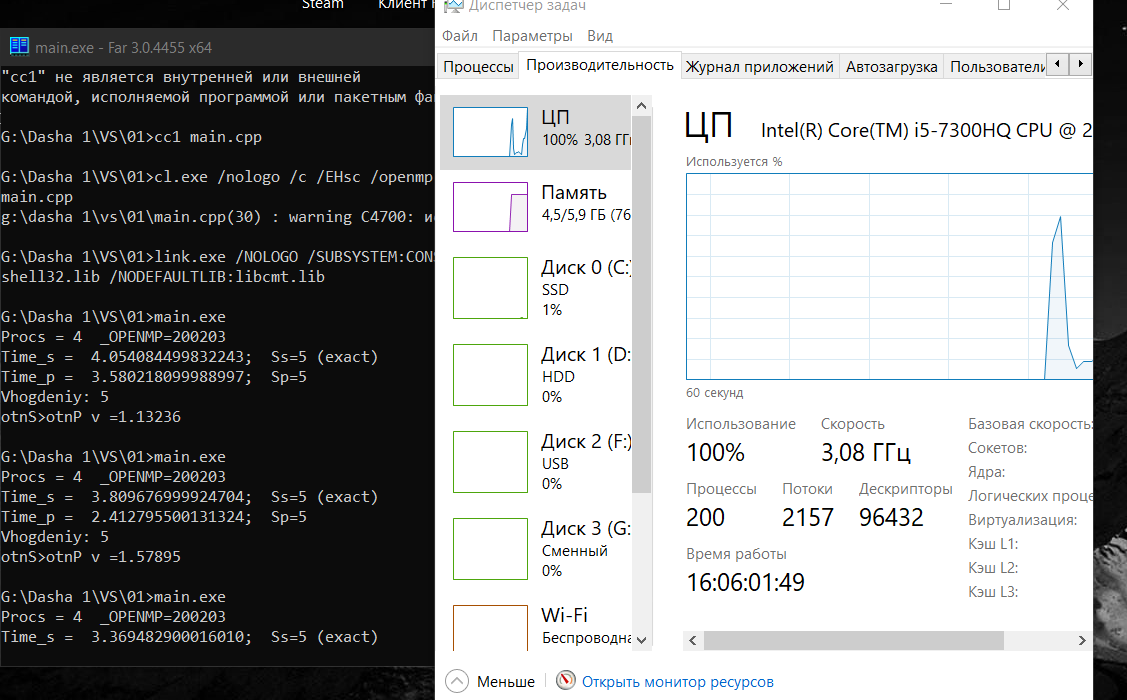
Результат работы программы
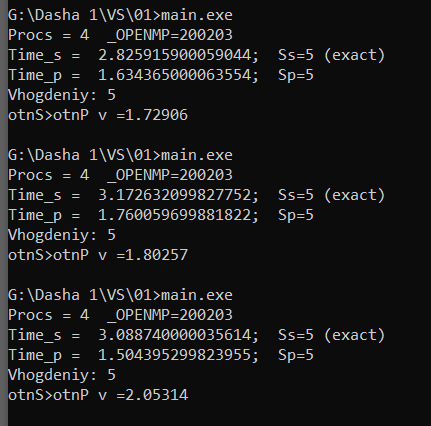
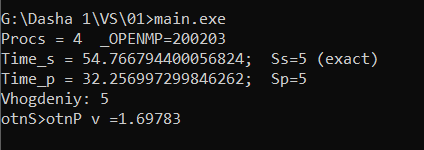
Увеличим число повторений N:
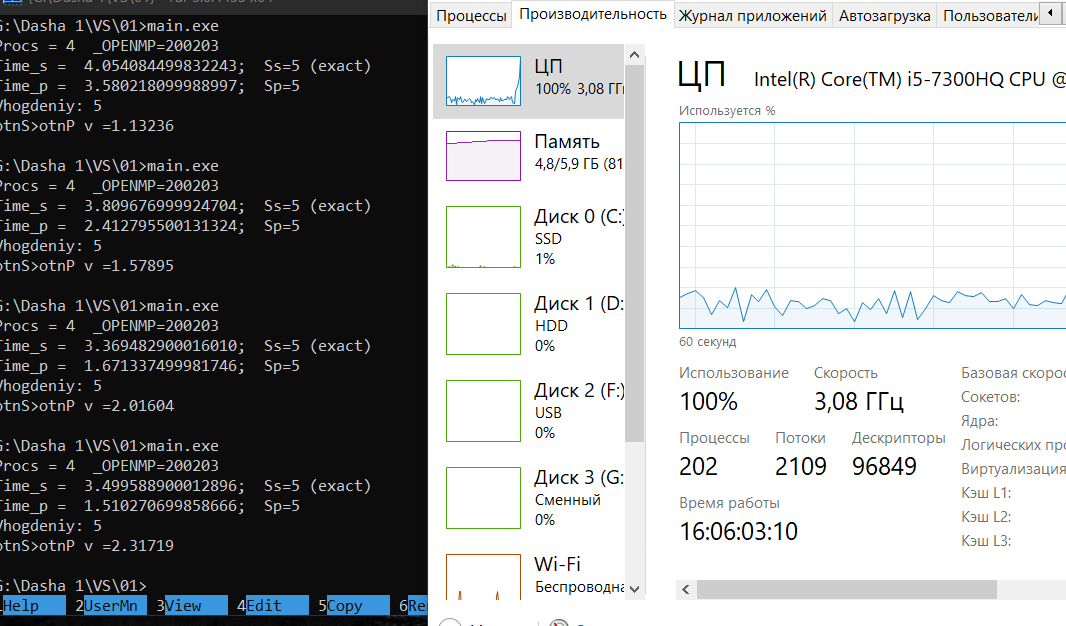
Загруженность процессора: