Добавлен: 16.02.2024
Просмотров: 60
Скачиваний: 0

СОДЕРЖАНИЕ
1.1 Описание предметной области. Постановка задачи
1.2.Выбор средств / методологии проектирования. Выбор СУБД
1.3. Проектирование логической структуры базы данных
1.4. Проектирование физической структуры базы данных
ПРОЕКТИРОВАНИЕ БД ДЛЯ ДОМАШНЕЙ БИБЛИОТЕКИ
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ
ПРИЛОЖЕНИЕ 1 – Структура тестовой БД.
ПРИЛОЖЕНИЕ 2 – Логическая структура БД для домашней библиотеки.
ПРИЛОЖЕНИЕ 3 – Скрипты создания таблиц и связей в БД library.
ПРИЛОЖЕНИЕ 4 – скрипт создания View для отчета со всеми книгами
Рисунок 6 – Пример объектно-ориентированной БД
- Объектно-реляционная модель данных (Рисунок 7). Подобные базы данных совмещают в себе объектно-ориентированную модель по качеству хранящихся данных и реляционный подход к структуре хранения.
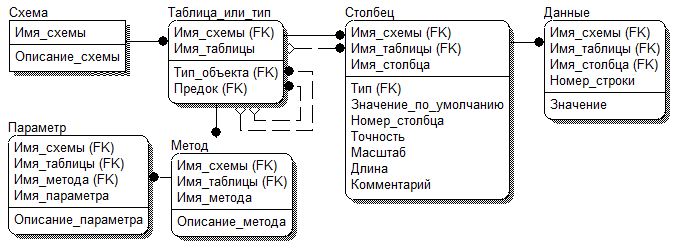
Рисунок 7 – Объектно-реляционная модель данных
Далее рассмотрим классификацию СУБД по организации данных. В такой классификации выделяют два типа СУБД.
- Локальная – БД называется локальной, если все ее части находятся на одном компьютере. Преимущество такой модели в ее независимости от сетевых процессов, т.к. все операции управления производятся на одном ПК. Но главный недостаток очевиден – редактирование БД происходит независимо на каждом ПК и, в случае работы в ней нескольких пользователей, сложно собрать и актуализировать все БД.
- Распределенная – БД называется распределенной, если ее части размещаются на двух или более устройствах. Это наиболее удобный вариант БД для многопользовательских систем. Так же, к плюсам подобного устройства БД можно отнести то, что части БД могут храниться на устройствах различного вида и с разными ОС.
По способу доступа к данным мы выделяем три основных вида организации СУБД.
- Файл-серверная архитектура – специфика данной архитектуры заключается в том, что пользователю передаются файлы из БД, но обрабатываются они уже на ПК пользователя. Из минусов такой системы сразу можно отметить, что на сеть дается дополнительная нагрузка в связи с излишними данными, передаваемыми пользователю, что негативно сказывается в случае большого объема объектов, хранящихся на сервере. Однако, эта структура отличается своей простотой, поэтому ее все еще можно встретить на некоторых небольших предприятиях.
- Клиент-серверная архитектура позволяет избежать тех проблем, которые преподносит файл-серверная архитектура. В подобной СУБД большая часть обработки данных происходит на машине сервера, а значит машина пользователя получает уже нужное количество данных, что позволяет снизить нагрузку на сеть, в отличие от предыдущего вида СУБД.
- Встраиваемая архитектура удобна, если БД используется только на одной машине. В этом случае СУБД встроена (тесно связана) с прикладной программой, обращающейся к ней. При этом сама БД находится на той же машине. Конечно, подобная структура не подойдет для средних или крупных предприятий, где администрирование производится несколькими людьми.
SQL (Structure Query Language) является языком программирования, который применяется для организации взаимодействия пользователя с реляционной базой данных. SQL работает по следующей схеме: запрос, написанный программистом на языке SQL обращается к некой СУБД, которая в свою очередь извлекает необходимую информацию из БД.
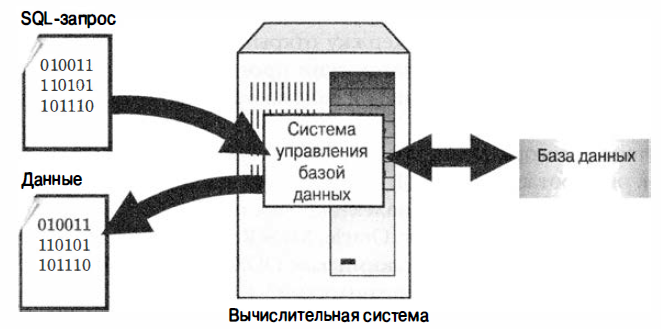
Рисунок 8 – Схема работы SQL
Несмотря на довольно простой принцип действия, сейчас можно говорить, что SQL предназначен не только для выборки данных, хотя это и является его основной функцией, но этот язык предлагает пользователю гораздо больше возможностей:
- Структура и организация запрашиваемых данных;
- Выборка данных;
- Обработка данных (добавление, изменение, удаление);
- Управление доступом к данным;
- Организация совместного использования БД;
- Обеспечение целостности данных.
Все эти возможности реализуются с помощью операторов SQL, либо встроенных функций СУБД. Рассмотрим основные операторы языка SQL.
Для удобства дальнейшей работы предлагаю воспользоваться примером БД, структура которой представлена в Приложении 1.
Запросы в языке SQL имеют примерно одинаковую структуру:
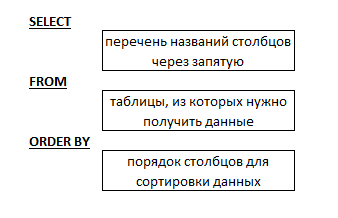
Рисунок 9 - Структура SQL запросов
Конечно, чем сложнее выборка данных, тем сложнее структура, больше подзапросов и массивнее объем обрабатываемых данных. Так же могут добавляться блоки условий и группировки данных, но основная структура практически всегда сохраняется в представленном виде.
Итак, все запросы на выборку данных в языке SQL начинаются с оператора SELECT. Следом за ним можно встретить следующие варианты:
- «TOP(n)» – где n – это количество строк. С помощью этого оператора мы можем вывести фиксированное количество строк. Используется совместно с перечнем столбцов.
- «pid, name, last_name» – перечень названий столбцов (через запятую), которые необходимо вывести в итоговой таблице.
- «*» - оператор, обозначающий все столбцы. Может использоваться как совместно с перечнем столбцов, так и индивидуально.
Далее, после определения набора столбцов следует оператор FROM. Здесь описываются таблицы, из которых необходимо получить данные. Чаще всего здесь используются операторы INNER/LEFT/RIGHT/FULL JOIN для объединения нескольких таблиц.
В случае необходимости, добавляется оператор условия WHERE, либо, если используются агрегирующие функции, HAVING. Здесь мы можем «отфильтровать» данные по нужным нам параметрам.

И заключительные операторы GROUP BY и ORDER BY. GROUP BY позволяет объединить строки с одинаковыми значениями в определенных столбцах (при этом, должны быть выбраны все столбцы, которые перечислены в операторе SELECT). Оператор ORDER BY позволяет сортировать данные в итоговой таблице, используется совместно с asc – по возрастанию, или desc – по убыванию.
Например, нам нужно из нашей БД выбрать фамилию, имя, город (в котором находится офис сотрудника) и должность сотрудников, с годом рождения с 1990 по 2000 включительно. Запрос будет выглядеть следующим образом:

Рисунок 10 - Пример запроса
Далее разберем операторы, позволяющие управлять данными в БД.
|
INSERT |
позволяет добавить одну или несколько строк с данными в существующую таблицу. |
|
DELETE |
позволяет удалить одну или несколько строк из существующей таблицы в БД. |
|
CREATE |
позволяет создать элемент БД (таблицу, хранимую процедуру, функцию). |
|
DROP |
позволяет удалить элемент БД (таблицу, хранимую процедуру, функцию). |
|
UPDATE |
позволяет изменить уже существующие данные в существующей таблице. |
Примеры использования:
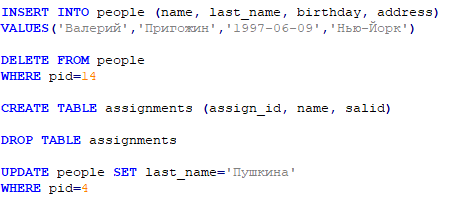
Рисунок 11 - Примеры использования операторов
В данных примерах рассмотрены самые простые запросы, которые можно построить с помощью языка SQL. Но в жизни запросы гораздо сложнее и затрагивают большее количество данных. Данные могут не только выводиться при определенных условиях, но могут подвергаться более глубокому анализу. Поэтому SQL завоевал большое количество пользователей.
В рамках данной курсовой работы мы будем использовать MS SQL для проектирования БД домашней библиотеки. Учитывая структуру будущей БД, будет логичным выбором использование объектно-реляционной структуры БД.
1.3. Проектирование логической структуры базы данных
Ранее мы уже определили основные характеристики, или атрибуты, которыми должна обладать книга. Для удобства использования и экономии места в БД мы будем использовать реляционную модель, которая позволит избежать дублирующих значений.
Прежде чем приступить непосредственно к созданию БД, нужно продумать архитектуру будущей базы. Структурировать таблицы и данные.
Преследуя финальную цель – иметь удобную и понятную БД для домашней библиотеки – необходимо создать таблицу, в которой мы будем хранить данные о книгах – books (Рисунок 12).
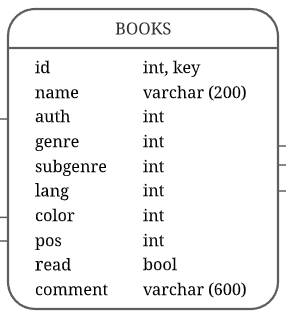
Рисунок 12 – Таблица books
В качестве столбцов таблицы мы добавляем:
- Id – уникальный идентификатор книги, внешний ключ;
- Name – название книги, тип данных varchar;
- Auth – информация об авторе, ссылка на таблицу со списком авторов;
- Genre – жанр книги, ссылка на таблицу со списком жанров;
- Subgenre – поджанр книги, ссылка на таблицу со списком поджанров;
- Lang – язык, на которой написана книга, ссылка на таблицу со списком языков;
- Color – цвет обложки книги, ссылка на таблицу со списком цветов;
- Pos – расположение книги, ссылка на таблицу со списком шкафов и полок;
- Read – была книга прочитана или нет;
- Comment – поле для комментария.
Теперь создаем таблицу с авторами – authors (Рисунок 13).
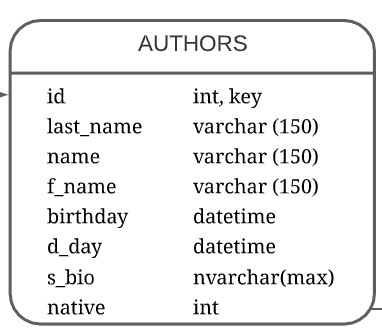
Рисунок 13 – Таблица authors
- Id – уникальный идентификатор автора, внешний ключ;
- Last_name – фамилия автора;
- Name – имя автора;
- F_name – отчество автора (если имеется);
- Birthday – дата рождения автора;
- D_day – дата смерти (если имеется);
- S_bio – краткая биография;
- Native – родной язык автора.
Таблица со списком жанров и поджанров – genres (Рисунок 14).
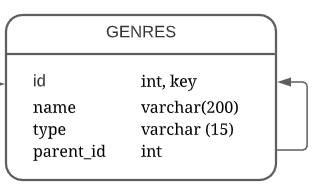
Рисунок 14 – Таблица genres
- Id – уникальный идентификатор жанра/поджанра, внешний ключ;
- Name – название жанра/поджанра;
- Type – разделение на жанр/поджанр;
- Parent_id – ссылка на родительский жанр у поджанров.
Таблица с перечнем языков – languages (Рисунок 15).
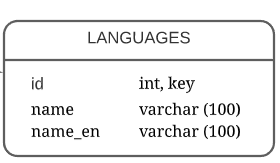
Рисунок 15 – Таблица languages
- Id – уникальный идентификатор языка, внешний ключ;
- Name – название языка на этом языке;
- Name_en – название языка на английском.
Таблица с цветами – colors (Рисунок 16).
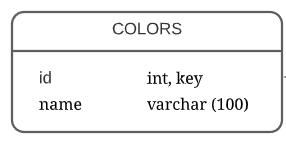
Рисунок 16 – Таблица colors
- Id – уникальный идентификатор цвета, внешний ключ;
- Name – название цвета.
Таблица с определением места книги – position (Рисунок 17).
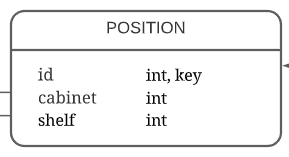
Рисунок 17 – таблица position
- Id – уникальный идентификатор позиции, внешний ключ;
- Cabinet – id шкафа;
- Shelf – id полки
Таблица со всеми шкафами и полками – storage (Рисунок 18).
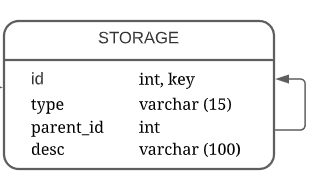
Рисунок 18 – таблица storage
- Id – уникальный идентификатор шкафа/полки, внешний ключ;
- Type – разделение на шкафы и полки;
- Parent_id – ссылка на родительский шкаф у полок;
- Desk – описание (местонахождение шкафа и тд).
Полная структура БД представлена в Приложении 2.
1.4. Проектирование физической структуры базы данных
После завершения построения логической модели БД, перейдем непосредственно к созданию физической модели БД.
На локальном сервере (MS Server 2019) создаем новую БД с названием library (Рисунок 19).
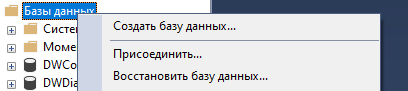
Рисунок 19 – Создание БД library
Далее создаем все таблицы, описанные выше и устанавливаем связи. Проверяем схему получившейся БД. Скрипты создания таблиц и создания связей, а так же схема БД приведены в Приложении 3.
ПРОЕКТИРОВАНИЕ БД ДЛЯ ДОМАШНЕЙ БИБЛИОТЕКИ
Инструкции по работе с базой данных
Как мы определили раньше, для организации ввода и вывода информации самым удобным решением будет создание локального сайта. Для удобной работой с БД удобным и простым решением будет создание сайта на языке PHP с использованием HTML для отрисовки интерфейса сайта. Так как сайт создается исключительно для локального использования, создавать сложную графику для сайта будет нерелевантным. Поэтому, используем самую простую табличную форму HTML (Рисунок 20).
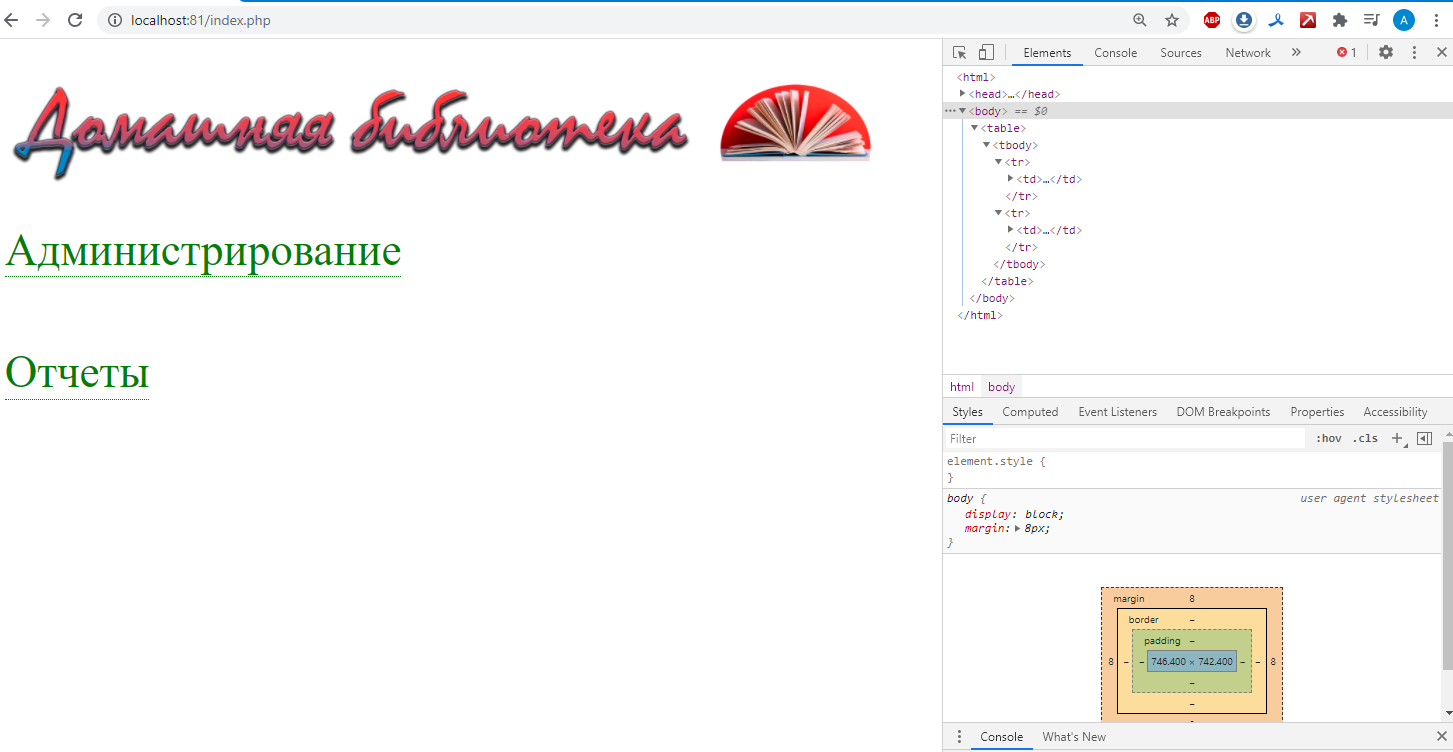
Рисунок 20 – Внешний вид домашней страницы
Для создания новых записей или редактирования существующих создан раздел «Администрирование». При нажатии на заголовок раскрываются доступные опции (Рисунок 21).

Рисунок 21 – Раздел «Администрирование»
Разберем пример добавления автора. При клике на соответствующую кнопку «Добавить автора» раскрывается форма для ввода данных на отдельной странице (Рисунок 22). Форма организована с помощью HTML тега <form>, метод GET позволяет передать данные из формы в соответствующие переменные и с помощью PHP (драйвер SQL для PHP, семейство функций sqlsrv) записать эти данные в БД. В случае наличия связей между таблицами реализованы выпадающие списки с возможными вариантами (Рисунок 22).