Добавлен: 16.02.2024
Просмотров: 57
Скачиваний: 0

СОДЕРЖАНИЕ
1.1 Описание предметной области. Постановка задачи
1.2.Выбор средств / методологии проектирования. Выбор СУБД
1.3. Проектирование логической структуры базы данных
1.4. Проектирование физической структуры базы данных
ПРОЕКТИРОВАНИЕ БД ДЛЯ ДОМАШНЕЙ БИБЛИОТЕКИ
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ
ПРИЛОЖЕНИЕ 1 – Структура тестовой БД.
ПРИЛОЖЕНИЕ 2 – Логическая структура БД для домашней библиотеки.
ПРИЛОЖЕНИЕ 3 – Скрипты создания таблиц и связей в БД library.
ПРИЛОЖЕНИЕ 4 – скрипт создания View для отчета со всеми книгами
Содержание:
ВВЕДЕНИЕ
Актуальность темы курсовой работы подтверждает тот факт, что сейчас умение обрабатывать информацию является ключевым навыком во всех сферах, не только в сфере информационных технологий. Разрабатывается все больше ПО для сбора, хранения и обработки информации. В том числе довольно новое, но очень популярное направление Big Data, которое применяется во многих отраслях современной инфраструктуры. Язык структурированных запросов (далее SQL – Structured Query Language) предоставляет пользователям очень простой и в то же время очень эффективный способ обработки данных. Помимо этого, SQL широко используется и в прикладном программировании, что дает возможность работать с ним и обычным пользователям, даже не прибегая к синтаксису самого языка.
В первую очередь, SQL предназначен для работы и управления реляционными базами данных. Далее мы рассмотрим их особенности и специфику работы. Важно отметить, что SQL является интегрируемым языком широкого пользования, что предоставляет пользователям возможность использовать его в ряде посторонних приложениях. Функциональность языка не изменяется вне зависимости от используемого ПО, устройства или базы данных.
Среди основных СУБД мы можем отметить таких «гигантов» в сфере IT технологий, как Microsoft (Microsoft SQL Server Management Studio, или SSMS), Oracle (Oracle SQL Developer), MySQL AB и Sun Microsystems (MySQL) и т.д.
Предметом исследования курсовой работы является «Проектирование БД для домашней библиотеки», объектом – «Базы данных».
Целью курсовой работы является изучение возможностей использования SQL даже для домашнего ежедневного использования. Являясь поклонником библиотек, книг и имея в наличии достаточное их количество, полученная в ходе исследоования и разработки БД может быть использована локально.
В рамках выполнения цели, необходимо будет решить следующие задачи:
1) определить основные понятия: база данных, система управления базами данных (далее – СУБД), классификация СУБД, основные возможности языка SQL;
3) проведение сравнительного анализа разных видов СУБД;
2) выявить преимущества и недостатки реляционной модели данных;
4) рассмотреть синтаксис языка SQL;
5) разработать структуру и подготовить скрипты для создания БД для домашней библиотеки.
Синтаксис скриптов будет использоваться для SSMS.
1 Глава. Аналитическая часть.
1.1 Описание предметной области. Постановка задачи
Еще совсем недавно использование Excel в качестве основного инструмента регистрации и обработки информации было обычным делом и даже крупные компании делились опытом и «фишками» использования Excel для ведения данных о сотрудниках, расчета заработной платы, премий, продаж, сведениях о клиентах и т.д. Сейчас же многие переходят на базы данных (далее – БД) и различные программы, использующие SQL как основной инструмент работы с БД. Что же это меняет? Почему использование Excel перестало быть таким популярным?
Первое преимущество использования SQL это, конечно же, возможность работы с БД несколькими пользователями одновременно, без риска «затереть» данные друг друга.
Оперативность работы. Ни для кого не секрет, что при значительном объеме данных, скорость работы Excel падает в несколько раз. А так же при использовании более сложного функционала, форм или макросов, скорость обработки функций так же падает. При работе с БД через прикладные программы (в основном использующих клиент-серверную архитектуру) запросы уже оптимизированы, и потеря скорости незначительна для конечного пользователя.
Простота. Конечно же, Excel – превосходный инструмент. Но, чтобы использовать все его возможности и оптимально работать с данными, необходимо иметь специфичные знания. Это превращает конечных пользователей в программистов, заставляя их разбираться с тонкостями работы макросов, вместо работы с данными. Прикладные программы же изначально создавались для удобства использования конечными пользователями без технических знаний. Это позволяет значительно сэкономить человеческий ресурс.
Это основные, но далеко не все преимущества перехода на прикладные программы с Excel. Конечно же, в некоторых случаях использование Excel остается конкурентным вариантом. И, при наличии соответствующих специалистов, Excel может полностью заменить прикладные программы, работающие с БД.
База данных – это организованный (упорядоченный) набор структурированной информации или данных, которые хранятся в электронном виде в компьютерной системе. Обычно, БД управляется с помощью системы управления базой данных.
Итак, перед нами стоит задача создать удобный инструмент для ведения домашней библиотеки с использованием СУБД. Для этого нам нужно будет:

- Придумать и настроить интерфейс для ввода данных;
- Создать структуру БД;
- Настроить БД;
- Определить список результатов (отчетов), которые мы хотим получать.
В качестве источника данных могут быть использованы следующие опции:
- Веб-интерфейс для записи данных в библиотеку;
- Загрузка данных из Excel с помощью стандартного фукционала СУБД;
- Ручной ввод в БД с помощью скриптов.
Есть и другие способы заполнения БД, но я предлагаю сконцентрироваться на этих трех, как на основных способах реализации поставленной задачи. Конечно, последние два пункта – это скорее привилегии администратора, либо начальная загрузка данных в БД, нежели ежедневное обновление информации. Наиболее удобным для постоянного использования является первый способ – веб-интерфейс. Там же можно будет настроить получение тех или иных отчетов.
Что же может понадобиться пользователю такой БД? Какие отчеты и результаты он бы хотел видеть на выборке? Предлагаю определить основные характеристики, которые будут описаны для книг:
- Автор;
- Название;
- Жанр и поджанр;
- Язык, на котором написана книга;
- Основной цвет обложки;
- Факт прочтения.
Соответственно, в качестве результата может быть отчет, отфильтрованный по одному или нескольким полям характеристик. И, в качестве стандартного отчета – все книги в библиотеке, которые еще не были прочитаны.
Т.к. библиотекой пользуюсь я одна – создавать многопользовательскую версию БД я не вижу смысла. Все действия будут выполняться одним единственным пользователем, он же – администратор БД.
Задачей курсовой работы является: создание удобного инструмента для ведения настроенной базы данных для домашней бибилиотеки и с возможностью выгружать необходимые отчеты из БД.
1.2.Выбор средств / методологии проектирования. Выбор СУБД
Система управления базами данных (далее СУБД) – это комплекс программных инструментов и средств, которые необходимы для создания структуры новой БД, ее редактирования, наполнения и отображения информации. СУБД могут быть классифицированы различными способами: по модели данных, по организации данных, по способу доступа к данным (Рисунок 1).

Рисунок 1 – Классификация СУБД
Классификация СУБД в соответствии с моделью данных. По данной классификации всего выделяют 5 типов СУБД. Рассмотрим их особенности:
- Иерархическая модель данных (Рисунок 2). Представляет собой набор элементов данных, расположенные в порядке подчинения. В иерархической структуре: каждый узел на более низком уровне должен быть связан только с одним узлом на более высоком уровне; корневой узел должен быть только один и он не должен подчиняться никакому другому узлу; до каждого узла существует только один путь от корневого.
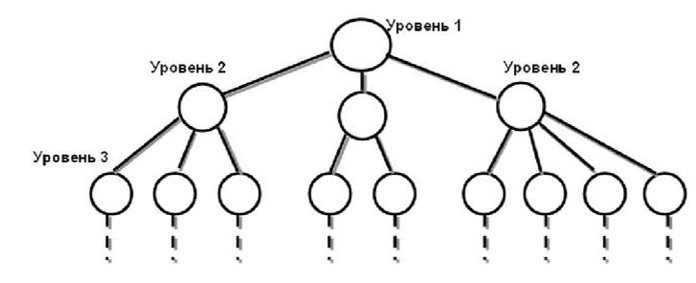
Рисунок 2 – Иерархическая модель данных
Примером Иерархической модели данных может служить модель населенных пунктов планеты Земля, где на первом (корневом) узле будет находиться планета Земля, далее континенты (Евразия, Африка, Южная Америка и т.д.), далее страны (Россия, Англия, Китай и т.д.), и, наконец, населенные пункты (Лондон, Москва, Санкт-Петербург, Париж и т.д.).
- Сетевая модель данных (Рисунок 3). Внешне похожа на иерархическую модель, но, в отличии от нее каждый узел может быть связан с любым узлом.
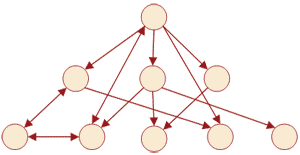
Рисунок 3 – Сетевая модель данных
Наглядным примером сетевой модели данных может служить список учеников школы, распределенных по дополнительным занятиям. На первом уровне будет находиться школа, далее классы (пока что никакого различия с иерархической структурой не наблюдается), на третьем уровне – ученики и на четвертом дополнительные занятия. На последних двух уровнях как раз яркий пример сетевой модели данных, так как ученики из разных классов могут заниматься в одном и том же кружке и, в свою очередь, каждый ученик может заниматься в нескольких кружках одновременно. Плюс каждый кружок проводит один из преподавателей, курирующих определенный класс, поэтому так же наблюдается связь четвертого и второго уровней структуры.
- Реляционная модель данных (Рисунок 4). Организована в виде двумерных таблиц. Каждая из таблиц в свою очередь является двумерным массивом. Таблицы должны соответствовать правилам: каждый из столбцов таблицы однородный по типу данных; каждый столбец имеет уникальное имя для этой таблицы; порядок строк и столбцов в таблице произвольный; каждая строчка (запись) имеет уникальный идентификатор для этой таблицы.
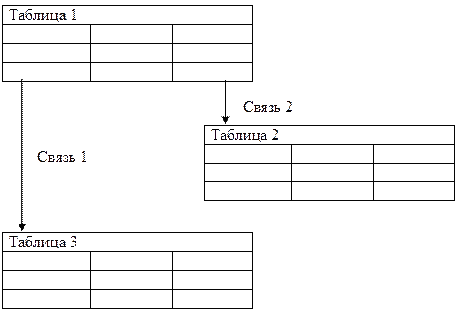
Рисунок 4 – Реляционная модель данных
Область применения реляционных таблиц очень широка. Для данной курсовой работы будет актуален пример списка сотрудников на предприятии (Рисунок 5). Для крупных предприятий характерно использование набора ID в полях описания сотрудника и последующее обращение к соответствующей таблице для определения значения этого ID. Допустим у нас имеется предприятие «Фирма». В базе данных Фирмы существует список физических лиц, в котором имеются все данные по людям, которые когда-либо так или иначе работали на предприятии. Далее имеется список работников – каждые прием и увольнение сотрудника. В этой таблице мы видим ссылку на ID из таблицы физических лиц, но так же имеется свой уникальный ID для каждого работника, т.к. одно и то же физ. лицо может быть принят и уволен несколько раз. Далее мы видим таблицу со списком назначений – в ней отражены все перемещения и изменения для каждого работника. В этой таблице так же записаны ID физ. лица и работника, но и свой уникальный ID присутствует. В столбце с должностью записывается ID должности, значение которой может быть извлечено из соответствующей таблицы должностей.
Набор таблиц и полей в подобной БД может варьироваться в зависимости от области применения и необходимости предприятия.

Рисунок 5 – Пример реляционной модели данных
- Объектно-ориентированная модель данных. Согласно определению, это БД, в которой данные формируются в виде объектов, атрибутов, методов и классов этих объектов. Каждый объект такой БД имеет свой уникальный идентификатор. Объекту присущи состояние и поведение. Состояние объекта характеризуется набором его атрибутов. Поведением объекта называется набор методов, управляющих его состоянием. Множество объектов с одинаковыми атрибутами и методами объединяются в классы объектов. Класс имеет свойство наследование – то есть создание нового класса, на основе уже существующего. При этом вновь созданный класс (подкласс) наследует все свойства родительского класса (суперкласс), но к ним приобретает свои дополнительные атрибуты и методы. Зачастую в прикладном программировании используются именно такие модели данных, так как с ними проще всего взаимодействовать на программном уровне. Проще всего представить объектно-ориентированную модель на примере (Рисунок 6). Рассмотрим ту же БД для предприятия «Фирма», но уже в объектно-ориентированной модели.
