Файл: Инструменты повышения производительности программного обеспечения. Требования к производительности.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 03.02.2024
Просмотров: 33
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.

Инструменты повышения производительности программного обеспечения.
Требования к производительности
Что значит - “быстро”?
Какие задачи система должна делать наиболее быстро? (Это должно быть либо наиболее важные для пользователя, либо наиболее часто им используемые). Не нужно оптимизировать производительность всех задач одновременно. Зачастую и невозможно: оптимизация, которая ускоряет выполнение одной задачи, снижает производительность для другой.
Для какой нагрузки (для какого количества параллельных задач)?
Собираемся мы обслуживать нашим серверным приложением 300 одновременных пользователей? 1000? 10 000?
C какой скоростью?
Пример 1:
страница “просмотр заявки” в веб приложении в среднем случае должна загружаться быстрее 3-х секунд
Пример 2:
Процесс обнаружения подозрительной активности в банковских транзакциях должен проверять 100 000 транзакций в сутки
Что такое производительность?
Две ключевые метафоры для понимания производительности:
-
“труба” (pipe)
-
“конвейер задач”
Обслуживание пользователя - это всегда последовательность задач.
Возьмем для примера, WEB приложение, которое получило запрос пользователя (например “открыть приходную накладную номер 123”). Конвейер задач выглядит так:
-
HTTP POST request
-
Find and load Session
-
Check Permissions
-
Try load object from Cache
-
Load object from Database
-
Write to usage tracking log
-
Send Request back to client.

Каждая задача имеет “длину”, т.е. продолжительность задачи в миллисекундах.
Каждая задача имеет “ширину”, т.е. затраты процессорного времени/памяти/производительности дискового ввода-вывода.
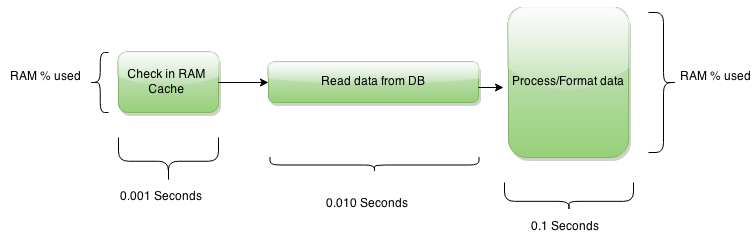
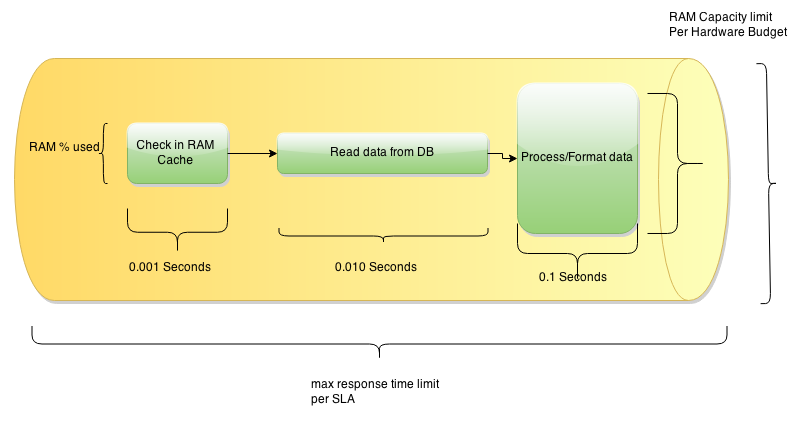
Суммарная продолжительность задач при выполнении одного запроса - это скорость с которой приложение отвечает пользователю (Response time, оно же Latency). Это то, что конечный пользователь называет производительностью.
Количество запросов, которое приложение способно выполнить в минуту (час/день), обслуживая необходимое для бизнеса количество пользователей(скажем 10 000) -
это пропускная способность (Bandwitch). Именно ее называет производительностью Заказчик/Бизнес-спонсор проекта.
Пример: “1 миллион просмотров страницы товара в сутки, при количестве одновременных пользователей до 10 000”.
От чего зависит пропускная способность?
-
От “пространства”, которое приложению требуется, чтобы обслужить одни запрос, т.е. произведения ширины и длины задач
Например, чем больше CPU time(RAM/Network bandwitch,и т.д.) приложению требуется для задачи “Проверить наличие товара на складе”(или чем ДОЛЬШЕ оно эту задачу выполняет) - тем меньше его остается для обслуживания других пользователей.
-
От пропускной способности “трубы” (pipe) в которой запросы выполняются. Больше места в “трубе” - больше запросов можно обслужить одновременно. Ее определяют прежде всего аппаратное обеспечение(hardware), потом OS и Middleware.
Виды ресурсов и фундаментальные ограничения
Инструменты повышения производительности программного обеспечения.
Требования к производительности
Что значит - “быстро”?
Какие задачи система должна делать наиболее быстро? (Это должно быть либо наиболее важные для пользователя, либо наиболее часто им используемые). Не нужно оптимизировать производительность всех задач одновременно. Зачастую и невозможно: оптимизация, которая ускоряет выполнение одной задачи, снижает производительность для другой.
Для какой нагрузки (для какого количества параллельных задач)?
Собираемся мы обслуживать нашим серверным приложением 300 одновременных пользователей? 1000? 10 000?
C какой скоростью?
Пример 1:
страница “просмотр заявки” в веб приложении в среднем случае должна загружаться быстрее 3-х секунд
Пример 2:
Процесс обнаружения подозрительной активности в банковских транзакциях должен проверять 100 000 транзакций в сутки
Что такое производительность?
Две ключевые метафоры для понимания производительности:
-
“труба” (pipe)
-
“конвейер задач”
Обслуживание пользователя - это всегда последовательность задач.
Возьмем для примера, WEB приложение, которое получило запрос пользователя (например “открыть приходную накладную номер 123”). Конвейер задач выглядит так:
-
HTTP POST request
-
Find and load Session
-
Check Permissions
-
Try load object from Cache
-
Load object from Database
-
Write to usage tracking log
-
Send Request back to client.
Каждая задача имеет “длину”, т.е. продолжительность задачи в миллисекундах.
Каждая задача имеет “ширину”, т.е. затраты процессорного времени/памяти/производительности дискового ввода-вывода.
Суммарная продолжительность задач при выполнении одного запроса - это скорость с которой приложение отвечает пользователю (Response time, оно же Latency). Это то, что конечный пользователь называет производительностью.
Количество запросов, которое приложение способно выполнить в минуту (час/день), обслуживая необходимое для бизнеса количество пользователей(скажем 10 000) -
это пропускная способность (Bandwitch). Именно ее называет производительностью Заказчик/Бизнес-спонсор проекта.
Пример: “1 миллион просмотров страницы товара в сутки, при количестве одновременных пользователей до 10 000”.
От чего зависит пропускная способность?
-
От “пространства”, которое приложению требуется, чтобы обслужить одни запрос, т.е. произведения ширины и длины задач
Например, чем больше CPU time(RAM/Network bandwitch,и т.д.) приложению требуется для задачи “Проверить наличие товара на складе”(или чем ДОЛЬШЕ оно эту задачу выполняет) - тем меньше его остается для обслуживания других пользователей.
-
От пропускной способности “трубы” (pipe) в которой запросы выполняются. Больше места в “трубе” - больше запросов можно обслужить одновременно. Ее определяют прежде всего аппаратное обеспечение(hardware), потом OS и Middleware.
Виды ресурсов и фундаментальные ограничения
Инструменты повышения производительности программного обеспечения.
Требования к производительности
Что значит - “быстро”?
Какие задачи система должна делать наиболее быстро? (Это должно быть либо наиболее важные для пользователя, либо наиболее часто им используемые). Не нужно оптимизировать производительность всех задач одновременно. Зачастую и невозможно: оптимизация, которая ускоряет выполнение одной задачи, снижает производительность для другой.
Для какой нагрузки (для какого количества параллельных задач)?
Собираемся мы обслуживать нашим серверным приложением 300 одновременных пользователей? 1000? 10 000?
C какой скоростью?
Пример 1:
страница “просмотр заявки” в веб приложении в среднем случае должна загружаться быстрее 3-х секунд
Пример 2:
Процесс обнаружения подозрительной активности в банковских транзакциях должен проверять 100 000 транзакций в сутки
Что такое производительность?
Две ключевые метафоры для понимания производительности:
-
“труба” (pipe)
-
“конвейер задач”
Обслуживание пользователя - это всегда последовательность задач.
Возьмем для примера, WEB приложение, которое получило запрос пользователя (например “открыть приходную накладную номер 123”). Конвейер задач выглядит так:
-
HTTP POST request
-
Find and load Session
-
Check Permissions
-
Try load object from Cache
-
Load object from Database
-
Write to usage tracking log
-
Send Request back to client.
Каждая задача имеет “длину”, т.е. продолжительность задачи в миллисекундах.
Каждая задача имеет “ширину”, т.е. затраты процессорного времени/памяти/производительности дискового ввода-вывода.
Суммарная продолжительность задач при выполнении одного запроса - это скорость с которой приложение отвечает пользователю (Response time, оно же Latency). Это то, что конечный пользователь называет производительностью.
Количество запросов, которое приложение способно выполнить в минуту (час/день), обслуживая необходимое для бизнеса количество пользователей(скажем 10 000) -
это пропускная способность (Bandwitch). Именно ее называет производительностью Заказчик/Бизнес-спонсор проекта.
Пример: “1 миллион просмотров страницы товара в сутки, при количестве одновременных пользователей до 10 000”.
От чего зависит пропускная способность?
-
От “пространства”, которое приложению требуется, чтобы обслужить одни запрос, т.е. произведения ширины и длины задач
Например, чем больше CPU time(RAM/Network bandwitch,и т.д.) приложению требуется для задачи “Проверить наличие товара на складе”(или чем ДОЛЬШЕ оно эту задачу выполняет) - тем меньше его остается для обслуживания других пользователей.
-
От пропускной способности “трубы” (pipe) в которой запросы выполняются. Больше места в “трубе” - больше запросов можно обслужить одновременно. Ее определяют прежде всего аппаратное обеспечение(hardware), потом OS и Middleware.
Виды ресурсов и фундаментальные ограничения
Инструменты повышения производительности программного обеспечения.
Требования к производительности
Что значит - “быстро”?
Какие задачи система должна делать наиболее быстро? (Это должно быть либо наиболее важные для пользователя, либо наиболее часто им используемые). Не нужно оптимизировать производительность всех задач одновременно. Зачастую и невозможно: оптимизация, которая ускоряет выполнение одной задачи, снижает производительность для другой.
Для какой нагрузки (для какого количества параллельных задач)?
Собираемся мы обслуживать нашим серверным приложением 300 одновременных пользователей? 1000? 10 000?
C какой скоростью?
Пример 1:
страница “просмотр заявки” в веб приложении в среднем случае должна загружаться быстрее 3-х секунд
Пример 2:
Процесс обнаружения подозрительной активности в банковских транзакциях должен проверять 100 000 транзакций в сутки
Что такое производительность?
Две ключевые метафоры для понимания производительности:
-
“труба” (pipe)
-
“конвейер задач”
Обслуживание пользователя - это всегда последовательность задач.
Возьмем для примера, WEB приложение, которое получило запрос пользователя (например “открыть приходную накладную номер 123”). Конвейер задач выглядит так:
-
HTTP POST request
-
Find and load Session
-
Check Permissions
-
Try load object from Cache
-
Load object from Database
-
Write to usage tracking log
-
Send Request back to client.
Каждая задача имеет “длину”, т.е. продолжительность задачи в миллисекундах.
Каждая задача имеет “ширину”, т.е. затраты процессорного времени/памяти/производительности дискового ввода-вывода.
Суммарная продолжительность задач при выполнении одного запроса - это скорость с которой приложение отвечает пользователю (Response time, оно же Latency). Это то, что конечный пользователь называет производительностью.
Количество запросов, которое приложение способно выполнить в минуту (час/день), обслуживая необходимое для бизнеса количество пользователей(скажем 10 000) -
это пропускная способность (Bandwitch). Именно ее называет производительностью Заказчик/Бизнес-спонсор проекта.
Пример: “1 миллион просмотров страницы товара в сутки, при количестве одновременных пользователей до 10 000”.
От чего зависит пропускная способность?
-
От “пространства”, которое приложению требуется, чтобы обслужить одни запрос, т.е. произведения ширины и длины задач
Например, чем больше CPU time(RAM/Network bandwitch,и т.д.) приложению требуется для задачи “Проверить наличие товара на складе”(или чем ДОЛЬШЕ оно эту задачу выполняет) - тем меньше его остается для обслуживания других пользователей.
-
От пропускной способности “трубы” (pipe) в которой запросы выполняются. Больше места в “трубе” - больше запросов можно обслужить одновременно. Ее определяют прежде всего аппаратное обеспечение(hardware), потом OS и Middleware.
Виды ресурсов и фундаментальные ограничения
Инструменты повышения производительности программного обеспечения.
Требования к производительности
Что значит - “быстро”?
Какие задачи система должна делать наиболее быстро? (Это должно быть либо наиболее важные для пользователя, либо наиболее часто им используемые). Не нужно оптимизировать производительность всех задач одновременно. Зачастую и невозможно: оптимизация, которая ускоряет выполнение одной задачи, снижает производительность для другой.
Для какой нагрузки (для какого количества параллельных задач)?
Собираемся мы обслуживать нашим серверным приложением 300 одновременных пользователей? 1000? 10 000?
C какой скоростью?
Пример 1:
страница “просмотр заявки” в веб приложении в среднем случае должна загружаться быстрее 3-х секунд
Пример 2:
Процесс обнаружения подозрительной активности в банковских транзакциях должен проверять 100 000 транзакций в сутки
Что такое производительность?
Две ключевые метафоры для понимания производительности:
-
“труба” (pipe)
-
“конвейер задач”
Обслуживание пользователя - это всегда последовательность задач.
Возьмем для примера, WEB приложение, которое получило запрос пользователя (например “открыть приходную накладную номер 123”). Конвейер задач выглядит так:
-
HTTP POST request
-
Find and load Session
-
Check Permissions
-
Try load object from Cache
-
Load object from Database
-
Write to usage tracking log
-
Send Request back to client.
Каждая задача имеет “длину”, т.е. продолжительность задачи в миллисекундах.
Каждая задача имеет “ширину”, т.е. затраты процессорного времени/памяти/производительности дискового ввода-вывода.
Суммарная продолжительность задач при выполнении одного запроса - это скорость с которой приложение отвечает пользователю (Response time, оно же Latency). Это то, что конечный пользователь называет производительностью.
Количество запросов, которое приложение способно выполнить в минуту (час/день), обслуживая необходимое для бизнеса количество пользователей(скажем 10 000) -
это пропускная способность (Bandwitch). Именно ее называет производительностью Заказчик/Бизнес-спонсор проекта.
Пример: “1 миллион просмотров страницы товара в сутки, при количестве одновременных пользователей до 10 000”.
От чего зависит пропускная способность?
-
От “пространства”, которое приложению требуется, чтобы обслужить одни запрос, т.е. произведения ширины и длины задач
Например, чем больше CPU time(RAM/Network bandwitch,и т.д.) приложению требуется для задачи “Проверить наличие товара на складе”(или чем ДОЛЬШЕ оно эту задачу выполняет) - тем меньше его остается для обслуживания других пользователей.
-
От пропускной способности “трубы” (pipe) в которой запросы выполняются. Больше места в “трубе” - больше запросов можно обслужить одновременно. Ее определяют прежде всего аппаратное обеспечение(hardware), потом OS и Middleware.
Виды ресурсов и фундаментальные ограничения
Инструменты повышения производительности программного обеспечения.
Требования к производительности
Что значит - “быстро”?
Какие задачи система должна делать наиболее быстро? (Это должно быть либо наиболее важные для пользователя, либо наиболее часто им используемые). Не нужно оптимизировать производительность всех задач одновременно. Зачастую и невозможно: оптимизация, которая ускоряет выполнение одной задачи, снижает производительность для другой.
Для какой нагрузки (для какого количества параллельных задач)?
Собираемся мы обслуживать нашим серверным приложением 300 одновременных пользователей? 1000? 10 000?
C какой скоростью?
Пример 1:
страница “просмотр заявки” в веб приложении в среднем случае должна загружаться быстрее 3-х секунд
Пример 2:
Процесс обнаружения подозрительной активности в банковских транзакциях должен проверять 100 000 транзакций в сутки
Что такое производительность?
Две ключевые метафоры для понимания производительности:
-
“труба” (pipe)
-
“конвейер задач”
Обслуживание пользователя - это всегда последовательность задач.
Возьмем для примера, WEB приложение, которое получило запрос пользователя (например “открыть приходную накладную номер 123”). Конвейер задач выглядит так:
-
HTTP POST request
-
Find and load Session
-
Check Permissions
-
Try load object from Cache
-
Load object from Database
-
Write to usage tracking log
-
Send Request back to client.
Каждая задача имеет “длину”, т.е. продолжительность задачи в миллисекундах.
Каждая задача имеет “ширину”, т.е. затраты процессорного времени/памяти/производительности дискового ввода-вывода.
Суммарная продолжительность задач при выполнении одного запроса - это скорость с которой приложение отвечает пользователю (Response time, оно же Latency). Это то, что конечный пользователь называет производительностью.
Количество запросов, которое приложение способно выполнить в минуту (час/день), обслуживая необходимое для бизнеса количество пользователей(скажем 10 000) -
это пропускная способность (Bandwitch). Именно ее называет производительностью Заказчик/Бизнес-спонсор проекта.
Пример: “1 миллион просмотров страницы товара в сутки, при количестве одновременных пользователей до 10 000”.
От чего зависит пропускная способность?
-
От “пространства”, которое приложению требуется, чтобы обслужить одни запрос, т.е. произведения ширины и длины задач
Например, чем больше CPU time(RAM/Network bandwitch,и т.д.) приложению требуется для задачи “Проверить наличие товара на складе”(или чем ДОЛЬШЕ оно эту задачу выполняет) - тем меньше его остается для обслуживания других пользователей.
-
От пропускной способности “трубы” (pipe) в которой запросы выполняются. Больше места в “трубе” - больше запросов можно обслужить одновременно. Ее определяют прежде всего аппаратное обеспечение(hardware), потом OS и Middleware.
Виды ресурсов и фундаментальные ограничения
Инструменты повышения производительности программного обеспечения.
Требования к производительности
Что значит - “быстро”?
Какие задачи система должна делать наиболее быстро? (Это должно быть либо наиболее важные для пользователя, либо наиболее часто им используемые). Не нужно оптимизировать производительность всех задач одновременно. Зачастую и невозможно: оптимизация, которая ускоряет выполнение одной задачи, снижает производительность для другой.
Для какой нагрузки (для какого количества параллельных задач)?
Собираемся мы обслуживать нашим серверным приложением 300 одновременных пользователей? 1000? 10 000?
C какой скоростью?
Пример 1:
страница “просмотр заявки” в веб приложении в среднем случае должна загружаться быстрее 3-х секунд
Пример 2:
Процесс обнаружения подозрительной активности в банковских транзакциях должен проверять 100 000 транзакций в сутки
Что такое производительность?
Две ключевые метафоры для понимания производительности:
-
“труба” (pipe)
-
“конвейер задач”
Обслуживание пользователя - это всегда последовательность задач.
Возьмем для примера, WEB приложение, которое получило запрос пользователя (например “открыть приходную накладную номер 123”). Конвейер задач выглядит так:
-
HTTP POST request
-
Find and load Session
-
Check Permissions
-
Try load object from Cache
-
Load object from Database
-
Write to usage tracking log
-
Send Request back to client.
Каждая задача имеет “длину”, т.е. продолжительность задачи в миллисекундах.
Каждая задача имеет “ширину”, т.е. затраты процессорного времени/памяти/производительности дискового ввода-вывода.
Суммарная продолжительность задач при выполнении одного запроса - это скорость с которой приложение отвечает пользователю (Response time, оно же Latency). Это то, что конечный пользователь называет производительностью.
Количество запросов, которое приложение способно выполнить в минуту (час/день), обслуживая необходимое для бизнеса количество пользователей(скажем 10 000) -
это пропускная способность (Bandwitch). Именно ее называет производительностью Заказчик/Бизнес-спонсор проекта.
Пример: “1 миллион просмотров страницы товара в сутки, при количестве одновременных пользователей до 10 000”.
От чего зависит пропускная способность?
-
От “пространства”, которое приложению требуется, чтобы обслужить одни запрос, т.е. произведения ширины и длины задач
Например, чем больше CPU time(RAM/Network bandwitch,и т.д.) приложению требуется для задачи “Проверить наличие товара на складе”(или чем ДОЛЬШЕ оно эту задачу выполняет) - тем меньше его остается для обслуживания других пользователей.
-
От пропускной способности “трубы” (pipe) в которой запросы выполняются. Больше места в “трубе” - больше запросов можно обслужить одновременно. Ее определяют прежде всего аппаратное обеспечение(hardware), потом OS и Middleware.
Виды ресурсов и фундаментальные ограничения
Инструменты повышения производительности программного обеспечения.
Требования к производительности
Что значит - “быстро”?
Какие задачи система должна делать наиболее быстро? (Это должно быть либо наиболее важные для пользователя, либо наиболее часто им используемые). Не нужно оптимизировать производительность всех задач одновременно. Зачастую и невозможно: оптимизация, которая ускоряет выполнение одной задачи, снижает производительность для другой.
Для какой нагрузки (для какого количества параллельных задач)?
Собираемся мы обслуживать нашим серверным приложением 300 одновременных пользователей? 1000? 10 000?
C какой скоростью?
Пример 1:
страница “просмотр заявки” в веб приложении в среднем случае должна загружаться быстрее 3-х секунд
Пример 2:
Процесс обнаружения подозрительной активности в банковских транзакциях должен проверять 100 000 транзакций в сутки
Что такое производительность?
Две ключевые метафоры для понимания производительности:
-
“труба” (pipe)
-
“конвейер задач”
Обслуживание пользователя - это всегда последовательность задач.
Возьмем для примера, WEB приложение, которое получило запрос пользователя (например “открыть приходную накладную номер 123”). Конвейер задач выглядит так:
-
HTTP POST request -
Find and load Session -
Check Permissions -
Try load object from Cache -
Load object from Database -
Write to usage tracking log -
Send Request back to client.
Каждая задача имеет “длину”, т.е. продолжительность задачи в миллисекундах.
Каждая задача имеет “ширину”, т.е. затраты процессорного времени/памяти/производительности дискового ввода-вывода.
Суммарная продолжительность задач при выполнении одного запроса - это скорость с которой приложение отвечает пользователю (Response time, оно же Latency). Это то, что конечный пользователь называет производительностью.
Количество запросов, которое приложение способно выполнить в минуту (час/день), обслуживая необходимое для бизнеса количество пользователей(скажем 10 000) -
это пропускная способность (Bandwitch). Именно ее называет производительностью Заказчик/Бизнес-спонсор проекта.
Пример: “1 миллион просмотров страницы товара в сутки, при количестве одновременных пользователей до 10 000”.
От чего зависит пропускная способность?
-
От “пространства”, которое приложению требуется, чтобы обслужить одни запрос, т.е. произведения ширины и длины задач
Например, чем больше CPU time(RAM/Network bandwitch,и т.д.) приложению требуется для задачи “Проверить наличие товара на складе”(или чем ДОЛЬШЕ оно эту задачу выполняет) - тем меньше его остается для обслуживания других пользователей.
-
От пропускной способности “трубы” (pipe) в которой запросы выполняются. Больше места в “трубе” - больше запросов можно обслужить одновременно. Ее определяют прежде всего аппаратное обеспечение(hardware), потом OS и Middleware.
Виды ресурсов и фундаментальные ограничения
| Вид ресурса | Операций в секунду | Пропускная способность (Bandwitch) | Скорость ответа(Latency) |
| Процессор | 2.0 - 3.5 GHz => 2,000,000,000 - 3,500,000,000 ops/sec | N/A | N/A |
| Диск(HDD) | 350 IOPs => 350 ops / sec | 50 - 120 MB / sec | 10 - 20 ms |
| Диск(SDD) | 100,000 - 130,000 IOPs 100,000 - 130,000 ops/sec | 200 - 6,000 MB /sec | 0.1 ms |
| Сеть (проводной Enternet) | 100 - 1000 Mbit / sec, Minimum TCP Packet 20 Bytes (160bits) => 600,000 - 6,000,000 ops/sec | LAN: 100Mbit - 1,000 Mbit => 12 - 125 MB/sec WAN: 2Mbit - 20 Mbit=> 0.25 - 2.5 MB/sec | LAN 0.1 - 1 ms WAN 20 - 300 ms |
| Оперативная память | Operational Freq: 166 - 255 MHz => 100,000,000 - 210,000,000 / sec | 8,500 - 17,000 MB / sec | 0.000,010 - 0.000,02 ms |
Примечание: Таблица составлена для реального “железа”. Виртуальное(cloud), естественно добавляет свои накладные расходы. Однако не меняет ситуацию принципиально. Никто не проектирует программное обеспечение отдельно для виртуальных машин и для реальных - и производители виртуальных платформ это понимают. В специфических случаях виртуальное “железо” может оказаться даже быстрее реального, например запись на виртуальный HDD может быть полностью буферизована в RAM внутри виртуальной машины и, естественно, будет в разы быстрее.
Как измерить производительность?
Мы хотим тестировать производительность, чтобы понять, выполнены ли требования к ней, надо ли улучшать.
Входное условие для тестирования - количество одновременных пользователей. Следует проводить тестирование не только на требуемой заказчиком возможной нагрузке, но так же и ниже/выше ее:
-
Если система имеет высокую производительность на максимальном количестве пользователей - это не означает что она не имеет проблем на среднем. -
Нужно знать, достигнут ли “потолок”, насколько большой запас производительности имеется в системе.
Показатели, которые следует мерить для нагрузочного тестирования:
-
Скорость ответа (далее Latency) - какая средняя скорость ответа? Какая максимальная и минимальная? -
Пропускная способность (далее Bandwitch) - сколько запросов в минуту выполнено? -
Количество ошибок (далее Error rate) - сколько запросов приложение не смогло выполнить?
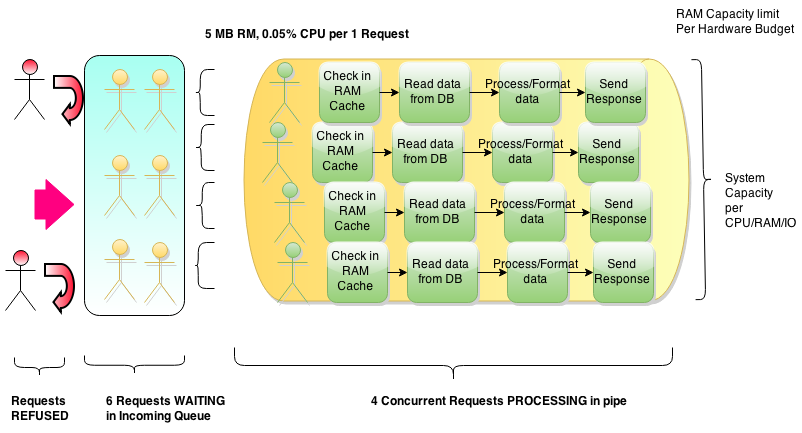
Подробнее о третьем показателе. Когда система подвергается большей нагрузке, чем способна обработать(т.е., когда мы пытаемся закачать в “трубу” больше задач, чем она может через себя пропустить), у нее есть 3 варианта поведения:
-
Правильный. Поставить входящие запросы в очередь и обработать их когда освободятся ресурсы
-
Пример: Наш электронный магазин предоставляет HTTP REST API партнерам, позволяя им закупать у нас товары оптом. Наш сервер API способен обслуживать 40 одновременных запросов. Что произойдет, когда мы получим одновременно 41 запрос? Нам придется поставить один запрос в очередь, и заставить его ждать, пока не освободится какой то из потоков, которые обслуживают сейчас предыдущих 40 пользователей. А если мы получим 60 одновременных запросов? Поставим в очередь 20 из них.
Правильный. Если количество запросов настолько велико

, что их невозможно обработать за требуемое время - отбрасывать запросы
-
Пример: Продолжая пример выше, что если мы получим 240 запросов? Мы конечно можем поставить 200 запросов в очередь- но чем больше у нас ожидающих в очереди, тем хуже средняя скорость ответа. Представьте, что вы стоите в огромной очереди за билетами на спектакль, который показывают сегодня последний раз и вы явно не успеваете до закрытия кассы. Нет смысла стоять в такой очереди. С точки зрения пользователя, система которая “зависла”, т.е.,отвечает слишком медленно, ничем не лучше системы которая “сломана”, т.е., не отвечает вообще. (Да, с точки зрения инженера, который обслуживает системы и знает их изнутри, разница большая - но заказчика это не интересует). Система, которая сразу сигнализирует о том, что перегружена/получила больше работы, чем может выполнить в срок, намного лучше, чем та которая молча заставляет клиентов ждать слишком долго/вечно. Нужно поставить лимит на длину очереди и отбрасывать (например через HTTP 500) запросы которые не уместились в нее.
Вопрос на проверку: если наш SLA(Service Level Agreement) “запрос должен быть обработан не больше чем за 6 секунды” и скорость выполнения запроса у нас 3 секунды - какая максимальная длина очереди имеет смысл? Ответ - 40. Более длинная очередь не позволит выполнить SLA.
-
Неправильный. Пытаться сделать больше работы, чем система способна выполнить. Это приведет лишь к неконтролируемому снижению производительности(из-за swopping’а памяти, перегрузки CPU/HDD/IO, и т.д.) -
Неправильный. Все остальное. Повредить данные, выдавать пользователю мусор вместо требуемого HTML/XML, не выдавать никакого ответа и так далее.
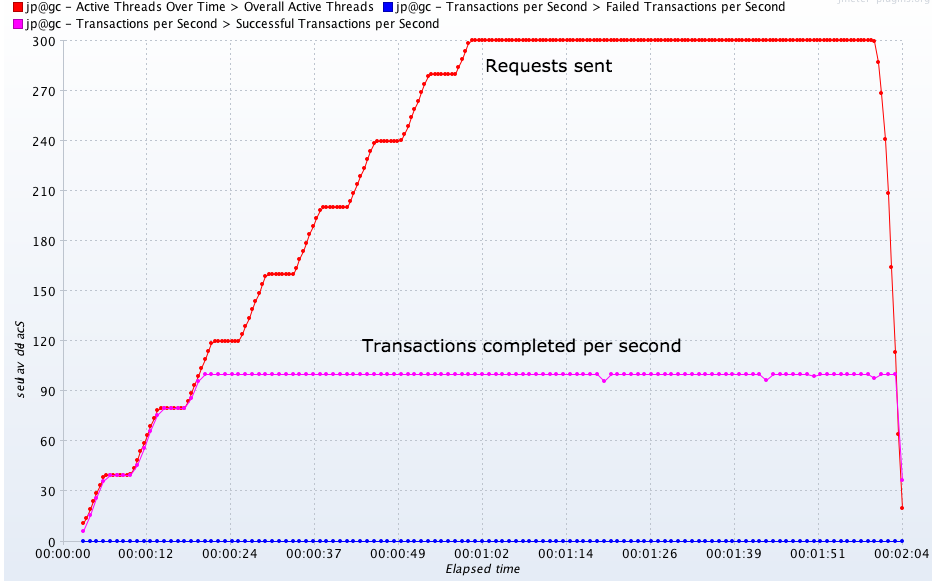
Типичный график нагрузочного тестирования. Система способна обработать не больше 100 запросов в секунду. Запихивание в систему большего объема работы (300 запросов) только создает длинную очередь из 200 ждущих запросов.
Тестирование, естественно, должно быть автоматизированным (как иначе имитировать работу сотен пользователей). Есть хороший выбор инструментов тестирования (Jmeter, Grinder, Load Runner).
Тестирование должно быть повторяемым (любой тест можно воспроизвести и сравнить производительность приложения до оптимизаций и после).
Любой участник команды(разработчик или тестировщик) должен иметь возможность провести тест на выбранном стенде в DEV(Developer) или QA(Quality Assurance) или на собственном компьютере - чтобы провести эксперимент или ревью.
Следовательно:
-
Тестовые скрипты, их настройки, тестовые данные, скрипты генерации тестовых данных - в Version Control System -
конфигурационные файлы приложения, OC и middleware (MongoDB, Elastic Search/ и т.д.) в Version Control System. -
Инструмент тестирования - любой разработчик может легко скачать и установить его на свой компьютер (нужны лицензии или инструмент должен быть open source). -
Отчет о тестировании должен показывать:
-
Производительность по каждой тестируемой задаче (“полнотекстовый поиск”, “просмотр накладной” и т.д.) по результатам последнего теста. -
Тренд в разрезе задача/производительность/количество пользователей за период, чтобы отследить, как недавние изменения в продукте повлияли на производительность
Необходимо отдельно тестировать производительность в режиме “кеширование включено” и “кеширование выключено”. Иначе мы можем получить завышенные результаты. Кеширование - может сильно повысить производительность и ,поэтому, используется, и в нашем продукте и во всех лежащих в его фундаменте Middleware(Веб сервер, СУБД,и т.д.). Но, в зависимости от того, как пользователи используют наш продукт, кеширование может дать как значительный выигрыш, так и нулевой и даже отрицательный (т.е., снизить производительность). Например, функция веб сайта “пользователь просматривает свой приватный профиль” не выигрывает от использования кеширования:
-
пользователь не будет просматривать свой профиль несколько раз подряд, -
другим пользователям доступ к этим данным запрещен, -
в целом этой функцией редко пользуются.
Нагрузочное тестирование для такой функции покажет ЗАВЫШЕННУЮ производительность. Потому что тест выполнит много запросов подряд, и , естественно, кеширование увеличит производительность - в тесте, но не в реальной жизни! Решение - выключить кеширование, прежде чем тестировать такую функцию ( в настройках нашего приложения, веб сервера, базы данных, и т.д.).
В ходе тестировании желательно фиксировать показатели нагрузки на железо/middleware. Это может помочь найти узкие места, препятсвующие движению данных (далее bottleneck) в системе.
Типовой набор метрик:
-
CPU User time -
CPU System time (Может показывать на неэффективный ввод-вывод, т.е. слишком большое количество мелких операций) -
HDD Number of reads -
HDD Number of writes -
HDD bytes readed -
HDD bytes written -
Network Number of reads -
Network number of writes -
Network bytes readed -
Network bytes written -
RAM Private space used by application -
RAM Shared space used by application -
RAM Number of page faults (насколько локализованы данные приложения в памяти?)
Когда начинать нагрузочное тестирование: как только получена первая сборка приложения.
Мощность и конфигурация тестового стенда должны быть идентичны продукции. (Для сокращения издержек, в случае использования облака можно выключать тестовые сервера либо снижать их мощность между нагрузочными тестами )
Типичная ошибка - запуск теста несколько раз без “холодного запуска” тестируемого ПО (завышает результаты из-за кеширования).
Как повысить производительность?
Чтобы получить высокую производительность:
-
Уменьшайте длину задач(т.е. Latency), но не за счет излишнего увеличения их “ширины”.
Например, слишком агрессивное кеширование памяти в задаче “сгенерировать веб страницу” ускорит ее выполнение, но заодно увеличит расход памяти на каждого пользователя - и ,в результате, сократит Bandwitch
-
Уменьшайте ширину задач в конвейере -
Уменьшайте количество задач в конвейере
Есть 3 способа достичь этого:
-
Ускорить задачу, выполнять ее быстрее -
Распараллелить задачи -
Исключить задачу, совсем обойтись без нее
Ускорение выполнения задачи
Основные способы:
-
Кеширование -
Предварительная калькуляция -
Предварительная инициализация -
Пакетные операции
Кеширование
Идея - мы вычислили/добыли данные один раз и кладем их поближе, чтобы в следующий раз далеко не тянуться.
Пример 1:
Прочитали данные с диска - запомнили в оперативной памяти. Сэкономим в следующий раз на ожидании дискового ввода-вывода.
Пример 2: У нас сервера в Европе, а клиент - в США. Проблема - network latency. Мы устанавливаем кеширующий сервер в CША, поближе к клиенту.
Как мы выбираем - что кешировать, а что - нет? На какой срок?
Не имеет смысла кешировать данные, которые не будут повторно востребованы. Такое кеширование только понизит производительность - из за накладных расходов на помещение данных в кеш/поиск в кеше.
Пример: Кеширует ли Google результаты поиска (вот этот набор из 100 000 ссылок по поисковой фразе “database performance”)? Предположу, что если и кеширует, то на короткий промежуток времени. Вероятность того, что много разных людей будут искать одно и то же - невелика. Вероятность, что они сформулируют свой поисковый запрос одинаково, слово в слово - еще меньше. В каком-нибудь поисковом сервисе для интранет - я бы не кешировал совсем.