Добавлен: 11.03.2024
Просмотров: 31
Скачиваний: 0

СОДЕРЖАНИЕ
ГЛАВА 1. ИНФОРМАЦИЯ И ЕЕ КОЛИЧЕСТВЕННЫЕ ОЦЕНКИ
1.2 Количественное оценивание информации
ГЛАВА 2. ЭФФЕКТИВНОЕ КОДИРОВАНИЕ ИНФОРМАЦИИ
2.1 Основная теорема Шеннона для кодирования
2.2 Типовая классификация методов кодирования
2.3 Статистические методы сжатия данных без потерь
2.4 Словарные методы оптимального кодирования
Пусть необходимо передать слово w = 221312233 в алфавите А = {1,2,3}. Монотонным кодом позиции 1 является 0, позиции 2 – 10, позиции 3 – 11. Кучка книг при последовательном появлении букв слова w изменяется таким образом:
(1,2,3) - (2,1,3) - (2,1,3) - (1,2,3) - (3,1,2) и т.д.
Кодом слова будет
100101110110 ...
Кодирование по степени новизны ненамного хуже лучшего кодирования методом Хаффмана. Данный метод уступает кодированию Хаффмана при уплотнении текстовых файлов, однако, для файлов с малым начальным алфавитом, можно добиться хороших результатов. Кодирование по степени новизны не требует предварительного просмотра начального массива. Этот метод легко приспосабливается к возможным колебаниям частот, поэтому он назван еще – локально-адаптивным. Кроме-того, он идеально подходит к совместному использованию вместе с BWT-преобразованием, которое размещает одинаковые символы блока, превращается, один за другим.
Вероятностное кодирования
Очень интересный и самый быстрый из известных методов уплотнения информации, дает к тому же неплохие результаты. Вероятностное уплотнения во многом напоминает гадание на кофейной гуще или предсказания погоды, только более эффективно [16].
Работает алгоритм следующим образом: достаточно большая таблица предсказаний, которая довольно быстро обновляется, в которой для каждой возможной пары последовательных входных символов указывается предусмотрен следующий (третий) символ. Если символ предусмотрен правильно – генерируется код в виде однобитного префикса, равного 1. Если знак не угадано – выдается код в виде префикса, равного 0 и не угаданного символа. При этом не угадан символ заменяет в таблице символ, который был там до этого, обеспечивая постоянное обновление статистической информации [1].
Алгоритм является адаптивным и поэтому он однопроходной и не требует сохранение таблицы вместе с закодированным текстом.
Декомпрессор работает по аналогичной программе, поддерживая и обновляя таблицу синхронно с компрессором. Если поступил префикс 1, очередная исходная буква берется из таблицы по индексу, полученным из двух предыдущих букв, иначе просто копируется код из входного потока в выходной. Для небольшого повышения степени уплотнения рекомендуется инициализировать таблицу перед началом работы любыми сочетаниями, которые часто встречаются.
Похожий алгоритм используется в архиваторе PKZIP Ver.1.5 под именем Reducing. Он почти по всем параметрам хуже, чем вероятностный (двухпроходной, требует передачи таблицы вместе с текстом), однако заслуживает упоминания. Таблица программы Reducing содержит массив символов V [256] [32], то есть для каждой входной буквы на первом проходе находятся не более, чем 32 (но может быть и меньше) следующих букв, которые часто встречаются. На втором проходе подобно вероятностного, если очередной символ b, поступающей по символу a находится среди 32 ожидаемых, генерируется код <prefix, position>, prefix = 1, position равно положению символа b в массиве V [a] [ ] с 32 букв. Иначе выдается префикс 0 и сам символ b. Алгоритм статический, поэтому таблица не обновляется в процессе работы.
2.4 Словарные методы оптимального кодирования
Словарные алгоритмы предназначены для устранения избытка цепочек событий. Суть алгоритма заключается в том, что цепочки событий помещаются в словарь. Если в дальнейшем во входном потоке встречается цепочка событий, который присутствует в словаре, то вместо этой цепочки в выходной поток помещается ссылка на элемент словаря.
Идея словарных алгоритмов была предложена Я. Зивом и А. Лемпелем в 1977 [15]. Идея была воплощена в алгоритме LZ77, ставший основой целого семейства алгоритмов. Альтернативный подход, предложенный ими же в 1978, породил семейство алгоритмов LZ78.
Словарные алгоритмы имеют не самые высокие коэффициенты уплотнения, но допускают очень быструю реализацию, особенно при декодировании данных, что и обуславливает их широкое использование.
Под словарем в алгоритмах семейства LZ77 понимается некоторое количество предыдущих событий. Как ссылки на элементы словаря используются расстояние до цепочки событий, которые встречались раньше, и длина этой цепочки [2].
Естественно, не для всех цепочек событий входного потока можно найти соответствующие цепочки в словаре. Чтобы обеспечить различие между цепочками событий и литерально событиями (событиями, не вошедшие в цепочки из словаря), алгоритм LZ77 просто чередует ссылки на элементы словаря с литерально событиями.
В алгоритме LZSS ссылки на элементы словаря и литеральны события различаются флажком-битом.
Алгоритм LZH аналогичный LZSS, но использует для указателей кодирования Хаффмана.
В настоящее время алгоритмы семейства LZ77 широко используются в программах универсальных архиваторов. Это, как правило, модификации LZSS с использованием кодов Хаффмана (LHARC) Шеннона-Фано (PKZIP) или арифметического кодирования (HA).
В алгоритмах семейства LZ78 цепочки в словаре увеличиваются на один символ каждый раз, когда цепочка из словаря встречается в входном потоке. В алгоритме LZ78, так же, как и в LZ77, литеральные события и элементы словаря чередовались.
В 1984 году Т. Уэлч предложил алгоритм LZW в котором все литеральные события являются элементами словаря [9]. Таким образом, в выходной поток помещаются только ссылки на элементы словаря, что упрощает алгоритм. Уэлч показал, что алгоритм может быть легко реализован на аппаратном уровне. Программная реализация, как правило, выполняется на основе вектора двоичных деревьев. Корнями деревьев служат элементы входного алфавита.
LZC – модификация алгоритма LZW направлена на повышение коэффициента сжатия.
Во-первых, в нем используется переменная длина кодов. Например, при уплотнении изображений с 4 битами на пиксель использование 5-битных кодов при пустом словаре дает значительную экономию по сравнению с 12-битными. По мере заполнения словаря длина кодов увеличивается.
Во-вторых, отслеживается степень уплотнения алгоритма. Если она падает ниже определенного предела, словарь очищается. Этим достигается быстрая адаптация алгоритма к резкому изменению характера данных.
LZC используется в утилите COMPRESS операционной системы UNIX и графическом формате GIF.
Алгоритм LZFG в некотором смысле является гибридом LZ77 и LZ78. Как и LZ77 он допускает кодирование цепочек произвольной длины (в алгоритмах LZ78 длина цепочек, как правило, ограничено количеством предыдущих появлений цепочки во входном потоке). С другой стороны, адресация элементов словаря аналогична технике LZ78 с той разницей, что вместо двоичного дерева используется так называемое дерево Patricia. Его отличие заключается в том, что если дерево не содержит разветвлений, то последовательность вершин объединяется в одну.
Алгоритм RFGD является модификацией LZFG с высокой степенью сжатия [1]. Он помещает в выходной поток данные четырех типов: терминальные вершины дерева, нетерминальные вершины дерева, литералы, что встречались ранее во входном потоке и литералы, которые ранее не встречались.
Каждый из них кодируется по собственной схеме. Для определения того, какого именно типа данные помещаются в выходной поток, непосредственно перед ними в выходной поток помещается специальный префикс. Алгоритм реализован на аппаратном уровне.
Алгоритм LZW
Алгоритм очень прост. Если коротко, то LZW-сжатие заменяет строки символов некоторыми кодами. Это делается без какого-либо анализа входного текста. Вместо этого, при добавлении каждой новой строки просматривается таблица строк. Сжатие происходит, когда код заменяет строка символов. Коды, генерируемые LZW-алгоритмом, могут быть любой длины, но они должны содержать больше бит, чем единичный символ.
Первые 256 кодов (когда используются 8-битные символы) по умолчанию соответствуют стандартному набору символов. Остальные коды соответствуют строкам, которые обрабатываются алгоритмом.
При сжатии и восстановлении LZW манипулирует тремя объектами: потоком символов, потоком кодов и таблицей строк. При сжатии поток символов является входным и поток кодов – выходным. При восстановлении входным является поток кодов, а поток символов – выходным. Таблица строк порождается и при сжатии, и при восстановлении, однако она никогда не передается от сжатия к восстановлению и наоборот.
Поскольку мы не знаем заранее объем файла, то трудно определить, какая
разрядность кодов будет оптимальной. Поэтому целесообразно использовать коды разной длины.
Уплотнения информации. Приведем алгоритм в простой форме. Каждый раз, когда генерируется новый код, новая строка добавляется в таблицу строк. LZW постоянно проверяет, данная строка уже известен, и, если так, выводит код без генерирования нового. Процедура LZW-сжатия приведена на рис. 2.2.

Рисунок 2.2 – Алгоритм уплотнения методом LZW
2.5 Арифметическое кодирование
Арифметическое кодирование позволяет кодировать события с вероятностью p количеством бит, как угодно близкой к величине -log2 p [14].
Пусть необходимо закодировать последовательность событий, причем в каждый момент может наступить событие A, B или C. Отложим вероятность событий A, B и C на отрезке [0,1].
Работа алгоритма наглядно показана на рис. 2.3, где на 4 диаграммах схематически отображены первые 3 шага работы алгоритма для входного алфавита, состоящего из событий «А», «В» и «С» при поступлении на вход алгоритма потока событий «А», «В», «С». Первая диаграмма показывает разделение интервала (0,1) на начальные подинтервалы между символами входного алфавита до начала работы алгоритма. После поступления на вход алгоритма события «В» рабочий интервал (X, Y) аналогичным образом делится между символами входного алфавита (диаграмма 2) и т.д. Диаграмма 4 соответствует заштрихованной области диаграммы 1.
По мере кодирования событий из входного потока рабочий интервал (X, Y) (X', Y') (X', Y') ... сокращается. Насколько он сократится при кодировании одного события, зависит от ширины начального интервала, соответствующего события (вероятность события).
Теоретически исходными данными алгоритма может служить любое число, входит в рабочий интервал после обработки последнего события входного потока. На практике же при каждом сокращении интервала в выходной поток помещаются все совпадающие старшие биты верхней и нижней границы рабочего интервала. Очевидно, что при поступлении события с большей вероятностью и с более широким начальным интервалом рабочий интервал сократится меньше и меньше битов попадет в выходной поток. Таким
образом, события с большей вероятностью появления кодируются меньшим числом битов.
Недостатком арифметического кодера является его высокая вычислительная сложность. Для каждого бита исходного потока необходимо выполнять ряд операций сравнения и смещения. Кроме того, для каждого кодированной события необходимо выполнить ряд операций умножения и деления.
С целью повышения быстродействия был предложен ряд быстрых алгоритмов. Как наиболее быстрая альтернатива арифметическому кодированию может быть использовано квазиарифметические [16]. В нем операции умножения и деления заменены операциями выбора значения из таблицы.
Алгоритм организован в виде конечного цифрового автомата. Во время поступления на вход кодированного события алгоритма в зависимости от текущего состояния при необходимости помещает в выходной поток некоторые биты и переходит в некоторое новое состояние. Таблицы переходов и выходов составлены так, чтобы эмулировать работу арифметического кодера. К недостаткам квазиарифметического кодера можно отнести низкую точность (или чрезмерно большой объем таблиц), а также то, что он реализован только для случая с двумя событиями.
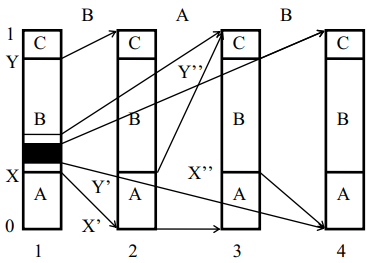
Рисунок 2.3 – Схема работы алгоритма арифметического кодирования
Удачной альтернативой арифметическому кодера, широко используемой в настоящее время, является Range-кодер [14]. Основным его отличием от арифметического кодера является не побитное, а побайтное сравнения верхней и нижней границы и побайтное размещения закодированного результата в выходной поток. Такой подход позволяет заметно повысить быстродействие кодера. При этом точность (качество кодирования) в отдельных реализациях Range-кодеров оказывается даже выше, чем у классического арифметического кодера (при использовании 32-битной целочисленной арифметики).
ЗАКЛЮЧЕНИЕ
В связи с возрастанием роли компьютерных технологий в повседневной жизни людей, интерес к теории информации и ее неотъемлемых составляющих кодирования и криптологии увеличивается. Причем, широкое применение находят равной степени три основные составляющие теории информации, которые имеют прикладной характер: экономное кодирование, помехоустойчивое кодирование и криптологии.
Методы теории информации, которые ранее были лишь предметом теоретических исследований, стали основой промышленных стандартов, используемых в сетях. Не в последнюю очередь это вызвано тем, что из сети передаются сообщения не только развлекательного характера, но и важные как с точки зрения отдельного человека, так и для общества в целом, в том числе и секретные. Повреждения или попадания в руки злоумышленников таких документов может привести к непредсказуемым последствиям.

