Добавлен: 11.03.2024
Просмотров: 42
Скачиваний: 0

СОДЕРЖАНИЕ
ГЛАВА 1. ИНФОРМАЦИЯ И ЕЕ КОЛИЧЕСТВЕННЫЕ ОЦЕНКИ
1.2 Количественное оценивание информации
ГЛАВА 2. ЭФФЕКТИВНОЕ КОДИРОВАНИЕ ИНФОРМАЦИИ
2.1 Основная теорема Шеннона для кодирования
2.2 Типовая классификация методов кодирования
2.3 Статистические методы сжатия данных без потерь
2.4 Словарные методы оптимального кодирования
2.1 Основная теорема Шеннона для кодирования
Эффективное кодирование сообщений для передачи их в дискретном канале без помех основывается на теореме Шеннона, которую можно сформулировать так [7]:
– сообщение источника с энтропией H(z) всегда можно закодировать последовательностями символов с объемом алфавита m так, что среднее число символов в знак сообщение lср будет как угодно близким к величине 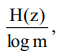 , но не меньше ее. При m = 2, lср ≥ H(z).
, но не меньше ее. При m = 2, lср ≥ H(z).
Теорема не указывает конкретного способа кодирования, но из нее видно, что каждый символ кодовой комбинации должен нести максимальную информацию, то есть каждый символ должен принимать значение либо 0, либо 1 по возможности с равными вероятностями и каждый выбор должен быть независимым от значения предыдущих символов. Для случая отсутствия взаимосвязей между знаками конструктивные методы построения эффективных кодов разработаны американскими учеными Шенноном и Фано. Поскольку их методики подобные, то соответствующий метод получил название Шеннона-Фано [3] .
Эффективное кодирование некоррелированной последовательности знаков методом Шеннона-Фано
Согласно методу Шеннона-Фано код строят следующим образом [3].
- Знаки алфавита сообщения вписывают в таблицу в порядке убывания их вероятностей.
- Затем их разделяют на 2 группы так, чтобы суммы вероятностей в обоих группах были по возможности одинаковы.
- Всем знакам одной группы приписывают как первый символ 0 (1), а знакам второй группы приписывают символ 1 (0).
- Каждую из полученных групп снова аналогично разбивают на 2 подгруппы.
- Процесс повторяется до тех пор, пока в каждой подгруппе не останется по одном знаке.
Пример. Выполнить эффективное кодирование ансамбля с 8 знаков, если известны их вероятности.
Решение. Используя методику Шеннона-Фано, получим совокупность кодовых комбинаций, приведенных в табл. 2.1.
Таблица 2.1 – Кодирование Шеннона-Фано
|
Знак |
p |
Кодовые комбинации |
Степень |
|
z1 |
1/2 |
1 |
I |
|
z2 |
1/4 |
01 |
II |
|
z3 |
1/8 |
001 |
II |
|
z4 |
1/16 |
0001 |
IV |
|
z5 |
1/32 |
00001 |
V |
|
z6 |
1/64 |
000001 |
VI |
|
z7 |
1/128 |
0000001 |
VII |
|
z8 |
1/128 |
0000000 |
VII |
Вычислим энтропию сообщения:
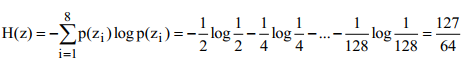
А среднее количество символов в знак после кодирования определяется так:
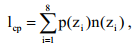
где n(zi) – количество символов (разрядов) в кодовой комбинации, соответствующей знаку zi .
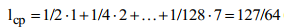
Поскольку вероятности знаков является целочисленные отрицательные значения двойки, то избыточность при кодировании изымается полностью, что и подтверждает равенство энтропии средним количеством символов в знак после кодирования.
Рассмотрена методика Шеннона-Фано не всегда приводит к однозначному построению кода. При разбиении на подгруппы можно сделать большею за вероятностями как одну, так и другую подгруппу. Этих недостатков не имеет методика Хаффмана.
2.2 Типовая классификация методов кодирования
Теория экономного или оптимального кодирования (optimal coding) объединяет в себе несколько различных направлений. В рамках данной теории методы принято разделять на методы экономного кодирования информации без потерь (lossless) и методы экономного кодирования информации с потерями (lossy) [9, 12-14]. Как следует из названий, обработка информации методами первой группы не ведет к информационным потерям, тогда как использование методов второй группы связано с такими потерями. Рассмотрим более подробно методы первой группы.
Среди алгоритмов уплотнения без потерь две схемы уплотнения – кодирования Хаффмана (Huffman) и LZW-кодирования (по начальным буквам фамилий Лэмпел (Lempel), Зив (Ziv) (его авторов) и Уэлч (Welch), который его существенно модифицировал), формируют основу для многих систем уплотнения [12].
Эти схемы подают два разных подхода к уплотнению данных. Отдельный класс образуют методы, которые известны как арифметическое кодирования. Таким образом алгоритмы сжатия данных без потерь можно разделить на следующие группы:
- статистические методы уплотнения;
- словарные (эвристические) методы уплотнения;
- арифметическое кодирование.
Статистические методы (Шеннона-Фано, Хаффмана, кодирование с степени новизны, вероятностное уплотнения и др.) требуют знания вероятностей появления символов в сообщении, оценкой которой является частота появления символов во входных данных [12].
Как правило, эти вероятности неизвестны. С учетом этого статистические алгоритмы можно разделить на три класса.
- Неадаптивные – используют фиксированные, заранее заданные вероятности символов. Таблица вероятностей символов не передается вместе с файлом, поскольку она известна заранее. Недостаток: полный список файлов, для которых достигается приемлемый коэффициент уплотнения.
- Полуадаптивный – для каждого файла строится таблица частот символов и с ее помощью уплотняют файл. Вместе с уплотненным файлом передается таблица символов. Такие алгоритмы достаточно неплохо уплотняют большинство файлов, но необходима дополнительная передача таблицы частот символов, а также два прохода начального файла для выполнения кодирования.
- Адаптивные – дело с фиксированной начальной таблицей частот символов (обычно все символы сначала равновероятны) и в процессе работы эта таблица меняется в зависимости от символов, встречающихся в файле. Преимущества: однопроходимость алгоритма, не требует передачи таблицы частот символов, достаточно эффективно сжимает широкий класс файлов.
Эвристические (словарные) алгоритмы уплотнения (типа LZ77, LZ78), как правило, ищут в файле строки, повторяющиеся и строят словарь фраз, которые уже встречались. Обычно такие алгоритмы имеют целый ряд специфических параметров (размер буфера, максимальная длина фразы и т.п.), подбор которых зависит от опыта автора работы, и эти параметры добираются таким образом, чтобы достичь оптимального соотношения времени работы алгоритма, коэффициента сжатия и перечень файлов, что хорошо сжимаются [12].
Арифметическое кодирование, подобно статистических методов, использует как основу технологии уплотнения, вероятность появления символа
в файле, однако сам процесс арифметического кодирования имеет принципиальные различия. В результате арифметического кодирования символьная последовательность (строка) заменяется действительным числом больше нуля и меньше единицы [10].
2.3 Статистические методы сжатия данных без потерь
Алгоритм RLE
Данный алгоритм очень прост в реализации. RLE (Run Length Encoding), или групповое кодирование, один из самых древних алгоритмов кодирования графики. Его суть заключается в замене повторяющихся символов, на один этот символ и счетчик повторений. Проблема заключается в том, чтобы архиватор при восстановлении мог отличить в результирующем потоке такую кодированную серию от других символов.
Решение очевидно – поместить во все цепочки некоторые заголовки (например, использовать первый бит как признак кодирования серии). Метод достаточно эффективен для графических изображений в формате «байт (byte) на пиксел» (например, формат РСХ использует кодирования RLE).
Однако недостатки алгоритма очевидны – это, в частности, было приспособленность ко многим типам файлов, часто встречающиеся, например, в текстовых. Поэтому его можно эффективно использовать только в сочетании с вторичным кодированием. Этот подход нашел свое отражение в алгоритме кодирования факсов: сначала изображение разбивается на черные и белые точки, превращаются алгоритмом RLE в поток длин серий, а потом эти длины серий кодируются методом Хаффмана со специально подобранным (экспериментально) деревом [7].
Кодирование Хаффмана
Хаффман предложил строить кодовое дерево не сверху вниз, как это неявно делается в алгоритме Шеннона-Фано – от корневого узла до листовых узлов, а снизу-вверх – от листовых узлов к корневому узлу. Такой подход оказался наиболее эффективным и получил весьма широкое распространение.
На начальном этапе работы алгоритма каждому символу информационного алфавита ставится в соответствие вес, равный вероятности (частоте) появления данного символа в сообщении. Символы помещаются в список, который сортируется по убыванию весов. На каждом шаге (итерации) два остальные элементы списка объединяются в новый элемент, который затем помещается в список вместо двух объединяемых элементов.
Новому элементу списка ставится в соответствие вес, равный сумме весов тех элементов, которые замещаются. Каждая итерация заканчивается упорядочиванием полученного нового списка, который всегда содержит в один элемент меньше, чем старый список.
Параллельно с работой указанной процедуры осуществляется последовательное построение кодового дерева. На каждом шаге алгоритма любому элементу списка соответствует корневой узел бинарного дерева, который состоит из вершин, соответствующих элементам, объединением которых был полученный данный элемент. При объединении двух элементов списка происходит объединение соответствующих деревьев в одно новое бинарное дерево, в котором корневой узел соответствует новому элементу, что помещается в список, а элементам списка что замещаются, соответствуют дочерние узлы этого корневого узла.
Алгоритм завершает работу, когда в списке остается один элемент, соответствующий корневом узлу построенного бинарного дерева. Это дерево называется деревом Хаффмана.
Система префиксных кодов может быть получена путем присвоения конкретных двоичных значений ребрам этого дерева. Пример построения дерева Хаффмана приведен на рис. 2.1.
Система кодов, полученная в результате построения дерева Хаффмана, является оптимальной системой префиксных кодов [13-14]. Отсюда, однако, в
некотором случае не следует вывод о том, что префиксные системы, полученные с использованием других алгоритмов, всегда менее эффективны.
Исходное сообщение
«Обороноспособность»
Статистика появления
букв в сообщении
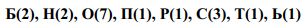
Построение системы префиксных кодов
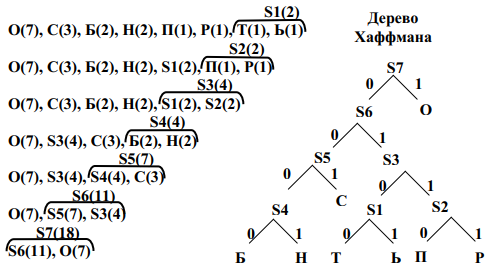
Система префиксных кодов
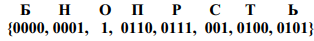
Рисунок 2.1 – Иллюстрация работы алгоритма Хаффмана
Недостатком такого кодирования является тот факт, что вместе с закодированным сообщением необходимо передавать также и построенную таблицу кодов (дерево), что снижает величину уплотнения. Однако существует динамический алгоритм построения дерева Хаффмана, в котором кодовая таблица обновляется самым кодировщиком и синхронно, и аналогично декодировщику в процессе работы после получения каждого очередного символа. Получаемые при этом коды оказываются квазиоптимальными, поэтому текст уплотняется немного хуже. Более того, растет сложность алгоритма и время работы программы (хотя она и становится однопроходных) [14].
Кодирование по степени новизны
Одним из вариантов адаптивного алгоритма Хаффмана алгоритм кодирования по степени новизны, известный также как MTF (Move To Front – двигай вверх), или кодирование с помощью кучки книг [12,15]. Идея метода такова: пусть алфавит источника состоит из N символов с номерами 1,2, ..., N. Кодер сохраняет список символов, которые представляют собой некоторую перестановку алфавита. Когда на вход поступает символ С, имеющий в список номер «и», кодер передает код номеру «и». Затем кодер переставляет символ С в начало списка, увеличивая на единицу номера всех символов, которые стоят перед С. Таким образом, более «популярные» символы будут тяготеть к началу списка и будут иметь более короткие коды.
Как код для кодирования по степени новизны можно использовать монотонный код – универсальный код источника, для которого известно лишь упорядоченность вероятностей символов. Монотонный код построен так, что более близкие к началу списка позиции, получают более короткие коды. В результате буквы, которые часто появляются и тяготеют к началу списка, будут иметь короткие кодовые обозначения. Рассмотрим уплотнения информации методом кодирования по степени новизны на примере.

