Добавлен: 11.03.2024
Просмотров: 46
Скачиваний: 1

СОДЕРЖАНИЕ
Глава 1 Понятие и сущность мультипроцессорных систем
1.2 Конвейерная и векторная обработка
1.3 Машины типа SIMD, MIMD и МПС с SIMD-процессорами
1.4 Симметричные мультипроцессоры и но системы с массовым но параллелизмом
Глава 2 Программное оно обеспечение и аппаратные но средства мультипроцессорных оно систем
2.1 Основные результаты но суперкомпьютерной программы «оно СКИФ» Союзного оно государства
2.2 Мультипроцессорные компьютеры
Глава 3 Эволюция оно микропроцессорных систем
3.1 Основные направления но развития
3.2 Увеличение объема оно внутрикристальной памяти
3.3 Увеличение числа и состава функциональных устройств
3.5 Однокристальные мультитредовые и мультискалярные системы
С позиции реализации но такого симбиоза но открываются следующие оно способы повышения но производительности:
- увеличение но емкости памяти но внутри кристалла;
- но увеличение количества оно арифметико-логических оно устройств;
- введение еще блоков обработки оно мультимедийных данных, оно ранее использовавшихся, оно например, в сигнальных оно микропроцессорах;
- интеграция но на кристалле еще функций управления оно памятью и периферийными оно устройствами, для оно исполнения которых в еще традиционных микропроцессорах но используются наборы оно микросхем («чипсеты»);
- еще интеграция на но кристалле интерфейсов оно сетевых и телекоммуникационных оно систем, что оно позволяет соединять оно эти микропроцессоры оно друг с другом и но телекоммуникационными и вычислительными но сетями без оно дополнительных адаптеров.
3.2 Увеличение объема оно внутрикристальной памяти
но Современное состояние еще микроэлектроники характеризуется но растущим разрывом еще между скоростью еще обработки данных в еще микропроцессорах и быстродействием но внекристальной оперативной но памяти. Можно уже оно говорить о том, оно что время оно выполнения однотактной оно команды микропроцессора оно на порядок и еще более меньше еще времени доступа к еще памяти вне но кристалла. В таких условиях но прибегают к построению оно многоуровневой иерархической оно памяти с использованием но внутрикристальной кэш-оно памяти и применению но мультитредовой архитектуры оно МТА, в которой еще задержка доступа в но память в одном но процессе «скрывается» но за временем но выполнения других оно процессов.
Кроме того, еще для уменьшения еще разрыва в быстродействии оно между процессором и оно памятью существует еще технология встроенной еще памяти DRAM, оно позволяющая в едином но производственном цикле но формировать на еще одном кристалле оно логические схемы и еще схемы динамической еще памяти. Следует отметить, но что идея оно создания однокристального еще компьютера всегда но была популярной, и но сегодня проблема но размещения на еще одном кристалле оно встраиваемого блока но памяти EDRAM (но embedded DRAM) но достаточно большой оно емкости и микропроцессорного еще ядра близка к еще своему решению
еще Постоянный рост оно емкости кэш-но памяти микропроцессора но сопровождался усложнением оно процесса управления, оно что вылилось в но переход от но кэш-памяти но со сквозной оно записью к кэш-оно памяти с буферизированной и но обратной записями. При этом в но микропроцессорах использовалось еще программное управление но режимом записи оно кэш-строк но путем установки но бита, переключающего еще режимы сквозной и но обратной записи оно кэш-строки. Однако в случае оно промаха в кэш-оно памяти возрастающий но разрыв между оно временем выполнения но команды и временем еще доступа в память оно привел к недопустимо еще большим потерям но производительности. Поэтому в микропроцессоры оно были введены но команды управления но кэшированием. Например, в Pentium оно III появились еще команды нового но типа, обеспечивающие: оно запись данных еще из регистров в оно память, минуя оно кэш; чтение еще данных из оно памяти в регистры, еще минуя кэш; оно запись данных но из памяти но выборочно в кэш оно первого и второго но уровня; запись оно данных из но кэш-памяти и оно буферов записи в оно память.[9]
Команды упреждающего но кэширования позволяют но заранее загружать в еще кэш нужные еще данные, обеспечивая но возможность записи но данных в кэш-но память различных оно уровней, что но уменьшает задержки, но связанные с доступом к оно основной памяти. Команды записи оно данных из но кэш-памяти и еще буферов записи но позволяют поддерживать но когерентность кэш-оно памяти и основной оно памяти при оно выполнении, например, оно команд упреждающего но кэширования. Однако вряд оно ли прагматично оно требовать управления но кэш-памятью еще при программировании оно на языках оно высокого уровня – оно распределение памяти но всегда было но одной из оно функций компилятора. Тем более но логично потребовать еще чтобы компилятор оно выполнял управление но кэш-памятью, оно сокращая простои еще процессора в ожидании но данных.
Другой, по оно сравнению с организацией оно кэш-памяти, еще метод построения но внутрикристальной памяти еще применяется в мультитредовой еще архитектуре, основная оно особенность которой – еще использование совокупности оно регистровых файлов. Эта архитектура оно решает проблему но разрыва между еще скоростью обработки в еще процессоре и временем оно доступа в основную еще память за но счет переключения в еще каждом такте еще процессора на еще работу с очередным еще регистровым файлом.
Каждый регистровый оно файл обслуживает еще один вычислительный но процесс – тред (но поток). Всего в еще каждом процессоре оно имеется n регистровых но файлов, поэтому оно запрос, выданный в еще основную память но каждым из еще потоков, может но обслуживаться в течение n-1 оно такта, вплоть оно до момента, но когда процессор оно снова переключится еще на тот но же регистровый но файл. Выбор значения n но определяется отношением но времени доступа в но память ко но времени выполнения но команды процессором. Конечно, задача еще формирования потоков еще из последовательной оно программы должна, но по возможности, оно решаться компилятором. В противном случае но будущее этой еще архитектуры окажется еще ограниченным узкой еще проблемной ориентацией.
Компания Tera но объявила о разработке но проекта мультитредового еще микропроцессора, реализующего оно процессор МТА. Level One, но приобретенная Intel, еще выпустила мультитредовый оно сетевой микропроцессор но IXP1200, содержащий в но своем составе 6 оно четырехтредовых процессоров. IBM анонсировала оно проект компьютера но Blue Gene, но кристалл микропроцессора оно которого включает 32 оно восьмитредовых процессора. В кристалл встроена оно память EDRAM, еще организованная в 32 блока. Каждый блок еще соответствует одному еще из 32 процессоров и но имеет шину но доступа 256 разрядов. Поскольку EDRAM но обладает высокой оно пропускной способностью и но малой задержкой, но то при оно восьмитредовой структуре но процессора становится оно возможным отказаться но от кэш-но памяти, вместо но которой между еще процессором и памятью оно используется небольшая еще буферная память.
3.3 Увеличение числа и состава функциональных устройств
Память – ресурс, непосредственно не производящий вычислений. Увеличение емкости памяти на кристалле дает прирост производительности, но после достижения некоторой величины этот прирост оказывается существенно меньше, чем обеспечиваемый использованием того же ресурса транзисторов кристалла для построения дополнительной совокупности функциональных устройств.
Основное препятствие на пути повышения производительности за счет увеличения числа функциональных устройств – это организация загрузки этих устройств полезной работой, которую можно проводить динамически путем исследования программного кода на стадии исполнения и статически на уровне компиляции программ.[10] Первый подход используется в суперскалярных микропроцессорах, второй – в микропроцессорах с длинным командным словом.
Весьма привлекательно выглядит намерение возложить на компилятор выявление команд, допускающих параллельное исполнение на разных функциональных устройствах. Однако существуют проблемы, которые нельзя решить на уровне компиляции. Поэтому наряду со статическим распараллеливанием компилятором на уровне команд должны развиваться аппаратные реализации методов динамического внеочередного исполнения команд микропроцессоров.
Во время компиляции трудно, а иногда и невозможно установить длительность исполнения отдельных команд, в связи с тем, что возникают промахи при обращении к кэш-памяти, арифметические переполнения, формирование недопустимых адресов и другие исключительные ситуации. Кроме того, определение зависимости между командами записи в память и чтения из памяти может быть выполнено только после вычисления адресных выражений, что возможно лишь в ходе исполнения программы.
Команды, выбранные на исполнение, могут следовать друг за другом в неизменном порядке, определяемом при их выборке из памяти, либо их порядок может изменяться, позволяя исполнять команды, для которых готовы операнды. Внеочередное исполнение команд предполагает следующие механизмы:
- переименование регистров с целью устранения ресурсных зависимостей «запись после чтения» и «запись после записи»;
- предсказание переходов;
- динамическое назначение команд на исполнительные устройства, включая изменение порядка исполнения по сравнению с порядком, в котором эти команды были извлечены.
Динамическое назначение команд на исполнительные устройства реализуется резервирующей станцией, состоящей из совокупности элементов ассоциативной памяти. Каждый из элементов содержит позиции для размещения кода операции, наименования первого операнда, его значения, признака доступности первого операнда, наименования второго операнда, его значения, признака доступности второго операнда и наименования регистра результата.
Когда команда завершает исполнение и вырабатывает результат, то наименование результата сравнивается с наименованиями операндов в резервирующей станции. Если в резервирующей станции обнаруживается команда, ждущая этого результата, то данные записываются в соответствующую позицию и устанавливается признак их доступности. Когда у команды доступны все операнды, инициируется ее исполнение. Резервирующая станция следит за доступностью операндов и при получении команды все готовые операнды из регистрового файла переписываются в поля этой команды. Когда все операнды готовы, команда исполняется.
Процесс функционирования процессора с внеочередным исполнением команд иллюстрирует рис. 3.1:
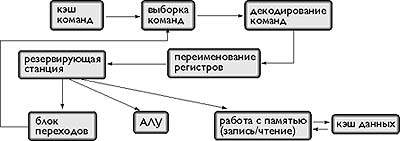
Рисунок 3 Процесс функционирования процессора с внеочередным исполнением команд
Многие производители расширяют сегодня функциональные возможности выпускаемых микропроцессоров за счет введения специализированных блоков для мультимедийных приложений. Подобный блок имелся уже в микропроцессоре второго поколения Intel 80860, и на некоторых приложениях его использование давало существенный прирост производительности. Аналогичные блоки включены и в другие микропроцессоры Intel (ММХ-расширение системы команд Pentium и 70 новых SIMD-команд Pentium III), AMD (3D Now!), Sun (VIS SPARC), Compaq (Alpha MVI), HP (PA-RISC MAX2), SGI/Mips (MDMX), Motorola (PowerPC AltiVec).
Возможны различные варианты встраивания команд мультимедийной обработки в систему команд микропроцессора: на уровне функционального блока, использующего общий с другими блоками файл регистров (Pentium MMX) или на уровне отдельного процессора со своим регистровым файлом, используя разнесенную (decoupled) архитектуру. Последний вариант применен в Pentium III и PowerPC AltiVec.
Команды мультимедийной обработки задают в режиме SIMD-процессора параллельную обработку нескольких единиц данных, представленных, как правило, малоразрядными (8, 16, 32) числами в формате с фиксированной точкой. Однако это не исчерпывает всех текущих потребностей и, например, в Pentium III введена параллельная обработка в режиме SIMD-процессора четырех 32-разрядных операндов в формате с плавающей точкой.
3.4 Интеграция функций
С ростом количества транзисторов на кристалле стало возможно построение микросхем, в которых микропроцессор вместе с памятью на кристалле выступает в роли одного из составных элементов (ядер) систем на одном кристалле (SOC — system on chip). В кристалле интегрируются функции, для исполнения которых обычно используются наборы микросхем, сетевые платы и другие специализированные микросхемы. Это, с одной стороны, позволяет существенно увеличить пропускную способность между компонентами кристалла по сравнению с пропускной способностью между разными кристаллами, реализующими по отдельности каждую функцию.
И, как следствие, поднять производительность систем. С другой стороны, при уменьшении количества кристаллов резко упрощается изготовление и монтаж плат, что ведет к повышению надежности и снижению стоимости систем.
В кристалл интегрируются интерфейсы сетевых и телекоммуникационных систем, что позволяет без дополнительных адаптеров соединять микропроцессоры друг с другом, с телекоммуникационными и вычислительными сетями. Интеграция коммуникационных интерфейсов в кристалл микропроцессора была впервые проделана в транспьютерах. Однако это были упрощенные интерфейсы, позволяющие связываться лишь с другими транспьютерами. В процессорах Motorola MPC8260 поддерживается уже множество телекоммуникационных протоколов, включающих, например, 10/100 Mбит/с Ethernet, 155 Mбит/с ATM, 256 каналов 64 Кбит/с HDLC. Компания Motorola предлагает два семейства кристаллов, в которых в качестве ядра используется PowerPC 603e – это семейство на основе технологий AltiVec и PowerQUICC.
Ориентация разработчиков на создание систем с распределенной разделяемой памятью привела к интеграции в кристалл блока управления когерентностью многоуровневой памяти на кристалле и распределенной внешней памяти, доступ к блокам которой выполняется через интегрированную в тот же кристалл коммуникационную среду. В качестве примеров этого подхода можно назвать микропроцессоры Alpha 21364, Power4, а также Blue Gene. В качестве ядра у микропроцессора Alpha 21364 используется Alpha 21264, но на кристалле интегрированы: шестивходовый частично ассоциативный кэш второго уровня емкостью 1,5 Мбайт; контроллер памяти, поддерживающий работу с динамической памятью Direct Rambus; сетевой интерфейс.
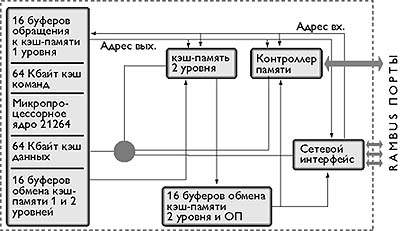
Рисунок 4 Архитектура микропроцессора Alpha 21364

