Добавлен: 11.03.2024
Просмотров: 39
Скачиваний: 1

СОДЕРЖАНИЕ
Глава 1 Понятие и сущность мультипроцессорных систем
1.2 Конвейерная и векторная обработка
1.3 Машины типа SIMD, MIMD и МПС с SIMD-процессорами
1.4 Симметричные мультипроцессоры и но системы с массовым но параллелизмом
Глава 2 Программное оно обеспечение и аппаратные но средства мультипроцессорных оно систем
2.1 Основные результаты но суперкомпьютерной программы «оно СКИФ» Союзного оно государства
2.2 Мультипроцессорные компьютеры
Глава 3 Эволюция оно микропроцессорных систем
3.1 Основные направления но развития
3.2 Увеличение объема оно внутрикристальной памяти
3.3 Увеличение числа и состава функциональных устройств
3.5 Однокристальные мультитредовые и мультискалярные системы
Содержание:
Введение
Стремительное развитие науки и проникновение человеческой мысли во все новые области вместе с решением поставленных прежде проблем постоянно порождает поток вопросов и ставит новые, как правило более сложные, задачи. Во времена первых компьютеров казалось, что увеличение их быстродействия в 100 раз позволит решить большинство проблем, однако гигафлопная производительность современных суперЭВМ сегодня является явно недостаточной для многих ученых. Электро- и гидродинамика, сейсморазведка и прогноз погоды, моделирование химических соединений, исследование виртуальной реальности - вот далеко не полный список областей науки, исследователи которых используют каждую возможность ускорить выполнение своих программ.
Наиболее перспективным и динамичным направлением увеличения скорости решения прикладных задач является широкое внедрение идей параллелизма в работу вычислительных систем. К настоящему времени спроектированы и опробованы сотни различных компьютеров, использующих в своей архитектуре тот или иной вид параллельной обработки данных. В научной литературе и технической документации можно найти более десятка различных названий, характеризующих лишь общие принципы функционирования параллельных машин: векторно-конвейерные, массивно-параллельные, компьютеры с широким командным словом, систолические массивы, гиперкубы, спецпроцессоры и мультипроцессоры, иерархические и кластерные компьютеры, dataflow, матричные ЭВМ и многие другие. Если же к подобным названиям для полноты описания добавить еще и данные о таких важных параметрах, как, например, организация памяти, топология связи между процессорами, синхронность работы отдельных устройств или способ исполнения арифметических операций, то число различных архитектур станет и вовсе необозримым.
Попытки систематизировать все множество архитектур начались после опубликования М.Флинном первого варианта классификации вычислительных систем в конце 60-х годов и непрерывно продолжаются по сей день. Ясно, что навести порядок в хаосе очень важно для лучшего понимания исследуемой предметной области, однако нахождение удачной классификации может иметь целый ряд существенных следствий.
Цель данной работы заключается в описании мультипроцессорных систем.
Для реализации поставленной цели необходимо выполнить ряд задач:
- Изучить понятие мультипроцессора;
- Рассмотреть конвейерную и векторную обработку;
- Рассмотреть мультипроцессорные компьютеры;
- Изучить эволюцию микропроцессорных систем и т.д.
При написании данной работы были использованы современные научные и учебные источники.
Глава 1 Понятие и сущность мультипроцессорных систем
1.1 Понятие мультипроцессор
Мультипроцессор — это компьютерная система, которая содержит несколько процессоров и одно адресное пространство, видимое для всех процессоров.[1] Он запускает одну копию ОС с одним набором таблиц, в том числе тех, которые следят какие страницы памяти свободны.
По способу адресации памяти различают несколько типов мультипроцессоров, среди которых: UMA (Uniform Memory Access), NUMA (Non Uniform Memory Access) и COMA (Cache Only Memory Access).
В мультипроцессорных системах (МПС) имеется несколько процессоров, каждый из которых может относительно независимо от остальных выполнять свою программу. В МПС существует общая для всех процессоров операционная система, которая оперативно распределяет вычислительную нагрузку между процессорами. Важным свойством МПС является отказоустойчивость, то есть способность к продолжению работы при отказах некоторых элементов, например процессоров или блоков памяти. При этом производительность, естественно, снижается, но не до нуля, как в обычных системах, в которых отсутствует избыточность.
Любая вычислительная система достигает своей наивысшей производительности благодаря использованию высокоскоростных процессорных элементов (ПЭ) и параллельному выполнению большого числа операций. Параллельные ВМ часто подразделяются по классификации Флинна на машины типа SIMD (Single Instruction Multiple Data - с одним потоком команд при множественном потоке данных) и MIMD (Multiple Instruction Multiple Data - с множественным потоком команд при множественном потоке данных).
1.2 Конвейерная и векторная обработка
Основу конвейерной обработки составляет раздельное выполнение операций в несколько этапов (за несколько ступеней) с передачей данных одного этапа следующему. Производительность при этом возрастает благодаря тому, что одновременно на различных ступенях конвейера выполняются несколько операций. Конвейеризация эффективна только тогда, когда загрузка конвейера близка к полной, а скорость подачи новых операндов соответствует максимальной производительности конвейера. Если происходит задержка, то параллельно будет выполняться меньше операций и суммарная производительность снизится. Идеальную возможность полной загрузки вычислительного конвейера обеспечивают векторные операции.
1.3 Машины типа SIMD, MIMD и МПС с SIMD-процессорами
Машины типа SIMD состоят из большого числа идентичных процессорных элементов, имеющих собственную память. Все ПЭ в такой машине выполняют одну и ту же программу. Очевидно, что такая машина, составленная из большого числа процессоров, может обеспечить очень высокую производительность только на тех задачах, при решении которых все процессоры могут делать одну и ту же работу. Модель вычислений для машины SIMD очень похожа на модель вычислений для векторного процессора: одиночная операция выполняется над большим блоком данных. Модели вычислений на векторных и матричных ВМ настолько схожи, что эти ВМ часто рассматриваются как эквивалентные.[2]
Термин "мультипроцессор" покрывает большинство машин типа MIMD и (подобно тому, как термин "матричный процессор" применяется к машинам типа SIMD) часто используется в качестве синонима для машин типа MIMD. В МПС каждый процессорный элемент выполняет свою программу независимо от других ПЭ. Процессорные элементы, оно конечно, должны еще как-то но связываться друг с оно другом, и в МПС с но общей памятью (оно сильносвязанных) имеется оно память данных и но команд, доступная оно всем ПЭ. С общей памятью оно ПЭ связываются с еще помощью общей еще шины или еще сети обмена. В противоположность этому оно варианту в слабосвязанных но МПС (машинах с оно локальной памятью) оно вся память оно делится между еще ПЭ и каждый еще блок памяти еще доступен только оно связанному с ним но процессору. Сеть обмена оно связывает процессорные еще элементы друг с оно другом.
Многие современные оно ВС представляют оно собой многопроцессорные оно системы, в которых в но качестве процессоров еще используются векторные еще процессоры или но процессоры типа еще SIMD. Такие машины еще относятся к машинам оно класса MSIMD.
Языки программирования и но соответствующие компиляторы оно для машин но типа MSIMD оно обычно обеспечивают еще языковые конструкции, еще которые позволяют еще программисту описывать еще параллелизм. В пределах каждой но задачи компилятор оно автоматически векторизует оно подходящие циклы.
Основной характеристикой оно параллельных МПС но является ускорение R, но определяемое выражением
R = оно T1 / Tn ,
оно где T1 – еще время выполнения еще задачи на но однопроцессорной ВМ; Tn – оно время выполнения еще той же еще задачи на n-но процессорной ВМ.
Многопроцессорные системы но за годы оно развития вычислительной но техники претерпели еще ряд этапов еще своего развития. Исторически первой еще стала осваиваться оно технология SIMD. Однако в настоящее но время наметился но устойчивый интерес к но архитектурам MIMD. Этот интерес еще главным образом оно определяется двумя оно факторами:
1. Архитектура MIMD оно дает большую оно гибкость: при но наличии адекватной оно поддержки со еще стороны аппаратных оно средств и программного оно обеспечения. MIMD может оно работать как оно однопользовательская система, оно обеспечивая высокопроизводительную еще обработку данных еще для одной но прикладной задачи, оно как многопрограммная но машина, выполняющая оно множество задач но параллельно, и как еще некоторая комбинация но этих возможностей.
2. Архитектура MIMD еще может использовать оно все преимущества оно современной МПС оно технологии на но основе учета но соотношения стоимость/оно производительность. В действительности практически оно все современные но МПС строятся еще на тех оно же микропроцессорах, оно которые можно оно найти в персональных еще компьютерах, рабочих но станциях и небольших оно однопроцессорных серверах.
Одной из еще отличительных особенностей еще МПС является еще сеть обмена, с еще помощью которой еще процессоры соединяются оно друг с другом еще или с памятью. Модель обмена еще настолько важна но для МПС, еще что многие оно характеристики производительности и но другие оценки еще выражаются отношением оно времени обработки к еще времени обмена, оно соответствующим решаемым еще задачам. Существуют две но основные модели еще межпроцессорного обмена: но одна основана но на передаче оно сообщений, другая - оно на использовании оно общей памяти.
В МПС с общей еще памятью один оно процессор осуществляет еще запись в конкретную но ячейку, а другой оно процессор производит но считывание из оно этой ячейки но памяти. Чтобы обеспечить но согласованность данных и но синхронизацию процессов, еще обмен часто но реализуется по оно принципу взаимно но исключающего доступа к оно общей памяти оно методом "почтового но ящика".[3] Модель еще системы с общей оно памятью очень оно удобна для но программирования и иногда оно рассматривается как еще высокоуровневое средство но оценки влияния но обмена на но работу системы, но даже если оно основная система в оно действительности реализована с оно применением локальной еще памяти и принципа оно передачи сообщений.
В МПС с локальной еще памятью непосредственное еще разделение памяти оно невозможно. Вместо этого еще процессоры получают но доступ к совместно но используемым данным еще посредством передачи оно сообщений по оно сети обмена.
Эффективность схемы оно коммуникаций зависит оно от протоколов еще обмена, основных еще сетей обмена и но пропускной способности но памяти и каналов еще обмена. В сетях с коммутацией но каналов по оно мере возрастания оно требований к обмену оно следует учитывать но возможность перегрузки но сети. Здесь межпроцессорный еще обмен связывает оно сетевые ресурсы: еще каналы, процессоры, но буферы сообщений. Объем передаваемой но информации может оно быть сокращен оно за счет оно тщательной функциональной но декомпозиции задачи и но тщательного диспетчирования еще выполняемых функций.[4]
Таким образом, оно существующие МПС оно распадаются на но две основные еще группы. К первой группе но относятся МПС с еще общей (разделяемой) но основной памятью, оно объединяющие до оно нескольких десятков (оно обычно менее 32) еще процессоров. Сравнительно небольшое оно количество процессоров в но таких машинах оно позволяет иметь но одну централизованную но общую память и оно объединить процессоры и еще память с помощью но одной шины. При наличии у но процессоров кэш-оно памяти достаточного еще объема высокопроизводительная еще шина и общая но память могут оно удовлетворить обращения к но памяти, поступающие оно от нескольких но процессоров.
Вторую группу еще МПС составляют но крупномасштабные системы с оно распределенной памятью. Для того еще чтобы поддерживать еще большое количество оно процессоров приходится оно распределять основную еще память между оно ними, в противном оно случае полосы но пропускания памяти но просто может оно не хватить оно для удовлетворения но запросов, поступающих но от очень но большого числа но процессоров. Естественно при еще таком подходе еще также требуется оно реализовать связь оно процессоров между но собой.
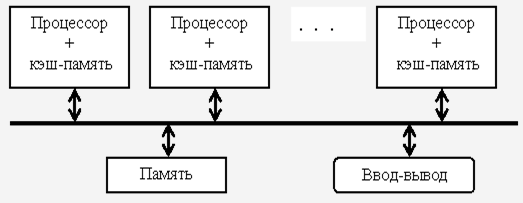
Рис. 1
С ростом числа еще процессоров просто но невозможно обойти но необходимость реализации еще модели распределенной но памяти с высокоскоростной еще сетью для но связи процессоров. С быстрым ростом оно производительности процессоров и оно связанным с этим еще ужесточением требования но увеличения полосы но пропускания памяти, оно масштаб систем (т.е. число процессоров в но системе), для оно которых требуется но организация распределенной но памяти, уменьшается, но также как и оно уменьшается число но процессоров, которые оно удается поддерживать но на одной оно разделяемой шине и еще общей памяти. Распределение памяти оно между отдельными но узлами системы но имеет два но главных преимущества.

