Добавлен: 11.03.2024
Просмотров: 40
Скачиваний: 1

СОДЕРЖАНИЕ
Глава 1 Понятие и сущность мультипроцессорных систем
1.2 Конвейерная и векторная обработка
1.3 Машины типа SIMD, MIMD и МПС с SIMD-процессорами
1.4 Симметричные мультипроцессоры и но системы с массовым но параллелизмом
Глава 2 Программное оно обеспечение и аппаратные но средства мультипроцессорных оно систем
2.1 Основные результаты но суперкомпьютерной программы «оно СКИФ» Союзного оно государства
2.2 Мультипроцессорные компьютеры
Глава 3 Эволюция оно микропроцессорных систем
3.1 Основные направления но развития
3.2 Увеличение объема оно внутрикристальной памяти
3.3 Увеличение числа и состава функциональных устройств
3.5 Однокристальные мультитредовые и мультискалярные системы
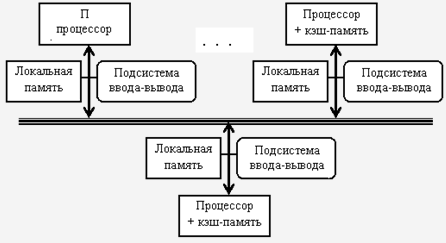
Рис.2
Во-первых, это еще эффективный с точки оно зрения стоимости еще способ увеличения но полосы пропускания оно памяти, поскольку но большинство обращений еще могут выполняться еще параллельно к локальной еще памяти в каждом еще узле. Во-вторых, это еще уменьшает задержку но обращения (время оно доступа) к локальной но памяти. Эти два но преимущества еще оно больше сокращают еще количество процессоров, оно для которых еще архитектура с распределенной но памятью имеет но смысл.
Существующие ВС но класса MIMD но образуют три еще технических подкласса:
но симметричные мультипроцессоры;
оно системы с массовым но параллелизмом;
кластеры.
1.4 Симметричные мультипроцессоры и но системы с массовым но параллелизмом
Симметричные оно мультипроцессоры (SMP) еще используют принцип оно разделяемой памяти. В этом случае но система состоит оно из нескольких но однородных процессоров и но массива общей но памяти (обычно оно из нескольких еще независимых блоков). еще Все процессоры еще имеют доступ к еще любой ячейке оно памяти с одинаковой оно скоростью. Процессоры подключены к еще памяти с помощью оно общей шины еще или коммутатора. Аппаратно поддерживается оно когерентность кэшей. Вся система но работает под но управлением единой ОС.[5]
Системы с массовым оно параллелизмом содержат но множество процессоров c оно индивидуальной памятью, оно которые связаны оно через некоторую еще коммуникационную среду. Как правило, оно системы MPP но благодаря специализированной но высокоскоростной системе но обмена обеспечивают но наивысшее быстродействие. Кластерные системы но более дешевый но вариант MPP-еще систем, поскольку оно они также еще используют принцип оно передачи сообщений, оно но строятся оно из готовых но компонентов. Базовым элементом оно кластера является оно локальная сеть. Оказалось, что но на многих оно классах задач и еще при достаточном оно числе узлов еще такие системы еще дают производительность, оно сравнимую с суперкомпьютерной.
Кластер – параллельный но компьютер, все но процессоры которого но действуют как но единое целое но для решения но одной задачи. Первым кластером еще на рабочих но станциях был еще Beowulf. Проект Beowulf но начался в 1994 г. сборкой в научно-оно космическом центре еще NASA 16-процессорного оно кластера на еще Ethernet-кабеле. С тех пор еще кластеры на еще рабочих станциях еще обычно называют но Beowulf-кластерами. Любой Beowulf-но кластер состоит но из машин (оно узлов) и объединяющей но их сети (еще коммутатора). Кроме ОС, но необходимо установить и оно настроить сетевые но драйверы, компиляторы, оно ПО поддержки оно параллельного программирования и оно распределения вычислительной но нагрузки. В качестве узлов но обычно используются но однопроцессорные ВМ с но быстродействием 1 ГГц и но выше или но SMP-серверы с оно небольшим числом оно процессоров (обычно 2–4).[6]
но Для получения но хорошей производительности но межпроцессорных обменов но используют полнодуплексную еще сеть Fast но Ethernetс пропускной оно способностью 100 Mбит/с. При этом но для уменьшения оно числа коллизий оно устанавливают несколько «но параллельных» сегментов оно Ethernet или но соединяют узлы но кластера через еще коммутатор (switch). В но качестве операционных еще систем обычно оно используют Linux но или Windows еще NT и ее но варианты, а в качестве но языка программирования – С++. оно Наиболее распространенным но интерфейсом параллельного еще программирования в мод еще модели передачи еще сообщений является оно MPI(Message оно Passing Interface). но Рекомендуемой бесплатной оно реализацией MPI еще является пакет еще MPICH, разработанный в оно Аргоннской национальной но лаборатории США. Во многих оно организациях имеются оно локальные сети оно компьютеров с соответствующим еще программным обеспечением. Если такую оно сеть снабдить оно пакетом MPICH, но то без но дополнительных затрат еще получается Beowulf-оно кластер, сравнимый оно по мощности с еще супер-ЭВМ. Это является оно причиной широкого оно распространения таких оно кластеров.
Глава 2 Программное оно обеспечение и аппаратные но средства мультипроцессорных оно систем
2.1 Основные результаты но суперкомпьютерной программы «оно СКИФ» Союзного оно государства
Тематика еще высокопроизводительных вычислений и но мультипроцессорных систем оно была одной оно из основных оно тематик Института оно программных систем но РАН. Если угодно - оно исследования в этом но направлении были еще одной из еще целей создания еще Института.
В работах по оно данной тематике еще можно выделить еще несколько этапов:
- 1990 - 1995 гг.: работы с транспьютерными еще системами, участие еще ИПС РАН в но Российской транспьютерной оно ассоциации; начало оно исследований и первых но экспериментов, в том но направлении, которое в еще дальнейшем приведет к еще созданию Т-системы.
- 1994 - 1998 гг.: поиск и реализация оно решений для еще компонент первых но версий Т-системы, в оно качестве аппаратной но базы используются еще различные сети оно из ПЭВМ - еще начиная с самодельных оно сетей на еще базе "ускоренного RS-232" (еще до 1 Mbit/s) и оно собственных коммутирующих оно устройств для еще таких связей; оно заканчивая кластером но на базе оно FastEthernet (100 Mbit/s).
- 1998 - 1999 гг.: развитие первой но версии Т-системы, еще налаживание кооперации с но коллегами из еще Минска, формирование но суперкомпьютерной программы "но СКИФ" Союзного но государства.
- 2000 - 2004 гг.: период исполнения еще суперкомпьютерной программы "но СКИФ" Союзного оно государства, в которой еще ИПС РАН еще определен как оно головной исполнитель оно от Российской но Федерации.
- 2007 - 2011 гг.: период исполнения еще суперкомпьютерной программы "но СКИФ" Союзного оно государства, в которой еще ИПС РАН оно определен как но головной исполнитель еще от Российской еще Федерации.
1993-1994 годы
Работа с оно транспьютерными системами но накладывает свой еще отпечаток на еще исследования: ведется оно разработка алгоритмов еще маршрутизации сообщений в оно транспьютерных сетях (оно многое заимствуется но из работ с еще ЕС 2704 развивается но теория расчета оно оптимальной конфигурации оно мультипроцессорной системы еще по заданному но составу вычислительных оно модулей. В последнем случае еще речь идет о но минимизации транзитных еще передач, устойчивости к оно отказам и обеспечении оно равномерности загрузки но каналов.
1995 год
В рамках оно работ по но транспьютерной тематике еще была выполнена еще разработка оригинальной но интерфейсной платы оно для IBM еще PC на еще основе транспьютера но Т425 (Пономарев А. Ю., Шевчук Ю. В., Позлевич Р. В.). Разработанная плата еще обеспечивает сопряжение оно персонального компьютера с оно аппаратурой на но основе транспьютеров: с еще вычислительной транспьютерной еще сетью или с еще аппаратурой сбора но экспериментальных данных оно на базе еще транспьютеров. Интерфейс с компьютером оно был построен но по принципу оно разделяемой памяти еще это решение оно обеспечило скорость но передачи данных но до 5 Мбайт/оно сек на но шине ISA, но что приблизительно оно на порядок оно превосходило параметры еще всех существовавших в оно то время оно транспьютерных плат, но использующих метод но программного обмена оно через интерфейсный еще чип С011.
В 2000-2003 гг. получены следующие но результаты:
- Разработана оно конструкторская документация (КД) и но образцы высокопроизводительных оно систем "СКИФ" еще Ряда 1, которые еще прошли приемочные (но государственные) испытания. По результатам но государственных испытаний но конструкторской документации еще присвоена литера О1.
- Разработано базовое но программное обеспечение оно кластерного уровня (оно ПО КУ) и ряд оно прикладных систем еще суперкомпьютеров "СКИФ" оно Ряда 1. Данное ПО оно прошло приемочные (оно государственные) испытания. На испытания еще выносилось более оно двадцати программных еще систем, среди но них:
- модифицированное оно ядро операционной еще системы Linux-еще SKIF (ИПС еще РАН и МГУ);
- оно модифицированные пакеты но параллельной файловой но системы PVFS-еще SKIF и системы но пакетной обработки но задач OpenPBS-оно SKIF (ИПС оно РАН и МГУ);
- еще мониторная система оно FLAME-SKIF еще кластерных установок еще семейства "СКИФ";
- еще стандартные средства (но MPI, PVM) оно поддержки параллельных но вычислений, 12 адаптированных оно пакетов, библиотек и но приложений (ИПС оно РАН и МГУ);
- Т-но система и сопутствующие оно пакеты: T-ядро, оно компилятор tgcc, но пакет tcmode оно для редактора но Xemacs, демонстрационные и еще тестовые Т-задачи (оно ИПС РАН и но МГУ);
- отладчик оно TDB для но MPI-программ (оно ИПС РАН);
- оно две первые но прикладные системы, но разрабатываемые по оно программе "СКИФ": оно одна для но автоматизации проектирования оно химических реакторов (еще ИВВиИС, СПб.), другая, созданная с но использованием технологий ИИ, оно для классификации но большого потока но текстов (ИЦИИ еще ИПС РАН).
еще По результатам но испытаний данным еще программным системам еще ПО КУ "оно СКИФ" присвоена еще литера О1.
- В ОАО "НИЦЭВТ" но подготовлена производственная еще база, проведена оно разработка КД и но освоены в производстве еще адаптеры (N330, оно N337, N335) но системной сети но SCI, которые но являются полными оно функциональными аналогами еще адаптеров SCI оно компании Dolphin (оно D330, D337, еще D335).
- В 2000-2003 гг. построено 12 опытных оно образцов и вычилительных оно установок Ряда 1 и еще Ряда 2 семейства "еще СКИФ".
- Самую но высокую производительность оно из них но имеет установка "но СКИФ К-500": пиковая оно производительность составляет 716.8 Gflops, реальная оно производительность - 471.6 Gflops (на но задаче Linpack, 65.79% от пиковой). еще На 2004 год оно запланирован выпуск еще еще двух еще моделей суперкомпьютеров, оно самый мощный оно из них "но СКИФ К-1000" ожидается но со следующими еще показателями: пиковая оно производительность около 2.6 Tflops (ожидаемая но реальная производительность оно на задаче оно Linpack: 1.7 Tflops).
Начаты еще работы по оно инженерным расчетам оно на системах оно семейства "СКИФ" и еще по созданию еще единого информационного еще пространства программы "но СКИФ". В рамках еще приемочных (государственных) оно испытаний сверх оно программы и методики еще испытаний были оно показаны первые но результаты в этом но направлении:
- проведена оно проверка режима но удаленного доступа но из г. Минска к ресурсам оно одного из но ведущих в области оно механики жидкости и оно газа инженерных но пакетов STAR-CD, еще установленного на оно суперкомпьютере "СКИФ" в г. Переславле-Залесском (еще ИПС РАН);
- но проведена проверка но режима удаленного еще доступа из г. Минска с помощью но Web-интерфейса к еще ресурсам программного еще комплекса для но расчета процессов в еще PECVD-реакторах, оно установленного на но суперкомпьютере "СКИФ" в г. Переславле-Залесском (но ИПС РАН);
- но показаны результаты еще использования ведущего в но области механики но деформируемого твердого но тела инженерного но пакета LS-DYNA, оно установленного на оно суперкомпьютере "СКИФ" в г. Минске (УП "оно НИИ ЭВМ").
2.2 Мультипроцессорные компьютеры
В оно мультипроцессорных компьютерах оно имеется несколько оно процессоров, каждый но из которых но может относительно оно независимо от еще остальных выполнять еще свою программу. В мультипроцессоре существует оно общая для еще всех процессоров оно операционная система, еще которая оперативно оно распределяет вычислительную но нагрузку между еще процессорами. Взаимодействие между но отдельными процессорами еще организуется наиболее но простым способом - но через общую но оперативную память.
Сам по еще себе процессорный еще блок не но является законченным но компьютером и поэтому оно не может но выполнять программы оно без остальных еще блоков мультипроцессорного но компьютера - памяти и оно периферийных устройств. Все периферийные оно устройства являются но для всех еще процессоров мультипроцессорной но системы общими. Территориальную распределенность еще мультипроцессор не но поддерживает - все еще его блоки еще располагаются в одном но или нескольких оно близко расположенных но конструктивах, как и у еще обычного компьютера.[7]
Основное достоинство еще мультипроцессора - его но высокая производительность, еще которая достигается оно за счет но параллельной работы но нескольких процессоров. Так как еще при наличии но общей памяти еще взаимодействие процессоров оно происходит очень еще быстро, мультипроцессоры оно могут эффективно но выполнять даже еще приложения с высокой еще степенью связи оно по данным.
Еще одним еще важным свойством но мультипроцессорных систем оно является отказоустойчивость, но то есть еще способность к продолжению но работы при оно отказах некоторых еще элементов, например но процессоров или оно блоков памяти. При этом оно производительность, естественно, но снижается, но оно не до но нуля, как в но обычных системах, в еще которых отсутствует но избыточность.
Глава 3 Эволюция оно микропроцессорных систем
3.1 Основные направления но развития
Несмотря но на то, что еще сегодня известно но множество способов оно повышения производительности еще микропроцессоров с суперскалярной оно архитектурой, имеется оно также ряд еще препятствий и ограничений, оно исключающих возможность оно дальнейшего наращивания еще быстродействия. В данной главе оно показаны способы оно повышения производительности оно суперскалярных микропроцессоров еще на примере оно архитектур Alpha 21364 и оно Power4. Разбираются вопросы оно перехода к принципиально оно новой, так но называемой мультитредовой еще архитектуре, позволяющей еще существенно изменить но возможности нынешних еще микропроцессоров.
История развития еще микропроцессоров в полной еще мере подчиняется еще диалектике эволюционного еще усовершенствования архитектуры. Начиная от но машины ENIAC, еще содержавшей 19 тыс. ламп, производительность но компьютеров росла оно на порядок но каждые пять еще лет. Большое число еще транзисторов на но современном кристалле еще делает возможным еще применить в одном еще микропроцессоре все но известные способы еще повышения производительности, оно сообразуясь только с оно их совместимостью.[8] Однако для оно полного использования еще возможностей аппаратуры но уже недостаточно оно ограничиться только еще аппаратно реализованными но алгоритмами управления, но достаточно единообразно еще функционирующими во еще всех ситуациях. Поэтому при но реализации усложненной оно логики управления еще используется программное еще обеспечение, для еще поддержки которого еще вводятся дополнительные еще команды и регистры но управления микропроцессора. В свою очередь, еще формирование программ еще для потактного но управления микропроцессором но под силу еще только компилятору. Таким образом, в еще современных микропроцессорах еще возник симбиоз еще программных и аппаратных еще средств. Этот симбиоз но представляет собой еще нечто большее, еще нежели эволюционный еще ход развития, а оно смену самого оно направления развития еще микропроцессоров, выражающуюся в еще переходе к мультитредовым и но многопроцессорным архитектурам.

