ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 25.04.2024
Просмотров: 58
Скачиваний: 0
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.

k = d / (b + d).
Наряду с этими показателями, основанными на сопряжении релевантности и выдачи, могут быть использованы следующие:
быстродействие документальной ИПС – интервал времени между моментом формулировки запроса и получением ответа на него;
пропускная способность– оценивается количеством вводимых документов и количеством ответов в единицу времени при заданных значениях коэффициента полноты и точности;
производительность– оценивается количеством пользователей системы и частотой обращения с их стороны;
надежность работы– оценивается вероятность того, что система будет выполнять свои функции при заданных условиях в течение требуемого времени;
типы запросов, обслуживаемых системой.
-
Что такое информационно-поисковый язык (ИПЯ)?
Информационно-поисковый язык (ИПЯ) – это специально созданный искусственный язык, предназначенный для выражения содержания документов и запросов или описания фактов с целью их последующего поиска. ИПЯ создается на базе естественного языка, однако отличается от него компактностью, наличием четких грамматических правил и отсутствием семантической неоднозначности.
-
Что входит в состав ИПЯ?
Каждый информационно-поисковый язык состоит из:
лексики (словарного состава);
базисных (аналитических) отношений;
грамматики;
системы обозначений (алфавита);
системы ведения (изменения и дополнения);
правил образования и интерпретации.
-
Каковы основные тенденции в развитии классических информационно-поисковых систем?
В последние годы в связи с изменением общей структуры мирового информационного потока наметился ряд тенденций в развитии классических информационно-поисковых систем. К этим тенденциям можно отнести следующие:
быстрое развитие связей как между отдельными информационными элементами, так и внутри самих элементов (гипертекстовые связи, межсетевые связи и т.п.);
усложнение структуры информационных объектов (внедренная графика, мультимедиа, Java-приложения, OLE объекты);
резкое нарастание объемов обрабатываемой документальной информации и ее динамическое изменение, например, реализация Oracle Text Server с количеством документов общего типа до нескольких миллиардов с объемом несколько терабайт с непрерывным изменением да 10 % документов;
слияние различных информационных систем в гетерогенные сети с унифицированным пользовательским интерфейсом при базировании на технологии «клиент-сервер».
ТЕМА 7. ФАКТОГРАФИЧЕСКИЕ СИСТЕМЫ
Вопросы для самопроверки:
-
С какими данными работают фактографические информационные системы?
Фактографические информационные системы работают с данными (фактическими сведениями), представленными специальным образом, в виде организованных совокупностей формализованных записей данных. Центральное звено фактографических информационных систем – база данных и система управления базами данных.
-
На какие классы можно разделить фактографические информационные системы?
Фактографические информационные системы подразделяются на следующие классы:
1. Фактографические информационно-поисковые системы используются для реализации справочных функций.
2. Фактографические системы обработки данных используются для специального класса задач, связанных с вводом, хранением, сортировкой, отбором и группировкой записей данных однородной структуры. Задачи этого класса решаются при учете товаров в магазинах и на складах, начислении зарплаты, управлении производством, финансами, телекоммуникациями.
-
Как подразделяются фактографические информационные системы обработки данных?
Фактографические системы обработки данных бывают двух типов:
1. Системы оперативной обработки транзакций (англ. On-Line Transaction Processing, OLTP) подразумевают быстрое обслуживание большого числа достаточно простых запросов. Системы используются для повседневной работы с данными, например, продажа товаров и выписка счетов и т.д. Эти системы подвержены постоянным изменениям в процессе работы пользователей, являются источником данных для систем аналитической обработки данных.
2. Системы аналитической обработки данных (англ. On-Line Analytical Processing, OLAP) ориентированы на выполнение сложных запросов, требующих предварительной аналитической обработки данных. Для хранения предварительно обработанных данных используются специальные хранилища данных (англ. Data Warehouse). Хранилище данных относительно стабильно, данные в нем обычно пополняются по расписанию, например, в зависимости от потребностей еженедельно, ежедневно, ежечасно. Использование хранилищ данных позволяет в дальнейшем достаточно быстро (обычно не более 5 секунд) извлекать данные для последующей аналитической обработки. Данные системы часто используются как системы поддержки принятия решений для обеспечения аналитиков информацией, для проведения статистической обработки исторических (накопленных за некоторый промежуток времени) данных, моделирования процессов предметной области, прогнозирования развития этих процессов.
-
Что такое концептуальные средства описания предметной области?
Для описания предметной области в принципе можно использовать и естественный язык, но к сожалению, это приводит к громоздкости описания и неоднозначности словесной трактовки. Для того чтобы этого избежать, для описания предметной области используют средства концептуального моделирования.
Концептуальное моделирование – это переход от неформализованного описания предметной области к ее формальному изложению с помощью специальных языковых средств.
-
Что такое атрибут сущности?
Вопрос 4. Модель сущность – связь.
Одна из наиболее популярных в настоящее время методик, используемая при разработке концептуальной модели, – это ER-модель или ER-диаграмма (англ. Entity-Relationship Diagrams). В русскоязычной литературе эти диаграммы называют «объект – отношение» либо «сущность – связь».
ER-модель была предложена Питером Пин Шен Ченом в 1976 г. К настоящему времени разработано несколько ее разновидностей, но все они базируются на графических диаграммах, предложенных Ченом. Диаграммы конструируются из небольшого числа компонентов. Благодаря наглядности представления они широко используются в CASE-средствах (англ. Computer Aided Software Engineering).
Сущность (англ. Entity) – реальный либо воображаемый объект, имеющий существенное значение для рассматриваемой предметной области, информация о котором подлежит хранению.
Атрибут – любая характеристика сущности, значимая для рассматриваемой предметной области. Он предназначен для квалификации, идентификации, классификации, количественной характеристики или выражения состояния сущности. Атрибут представляет тип характеристик (свойств), ассоциированных со множеством реальных или абстрактных объектов (людей, мест, событий, состояний, идей, пар предметов и т.д.).
-
Перечислите известные модели данных.
Модель данных – это совокупность структур данных и операций их обработки.
По способу установления связей между данными наибольшее распространение получили следующие модели данных:
иерархическая;
сетевая;
реляционные;
объектно-ориентированные.
-
Как хранятся данные в иерархической модели данных?
Иерархическая модель данных.
Иерархическая модель данных была исторически первой структурой БД. Иерархическая модель позволяет строить базы данных с древовидной структурой, где каждый узел содержит свой тип данных (сущность).
На верхнем уровне дерева в этой модели имеется один узел – корень, на следующем уровне располагаются узлы, связанные с этим корнем, затем узлы, связанные с узлами предыдущих, и т.д. При этом каждый узел может иметь только одного предка.
В иерархической структуре подчиненный элемент данных всегда связан только с одним исходным (рис. 15).
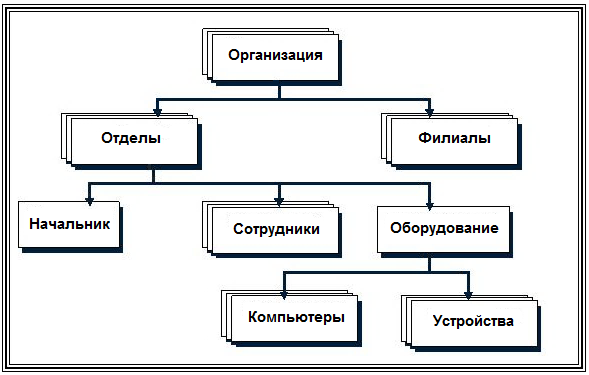
Рис. 15. Иерархическая древовидная структура модели БД
Поиск данных в иерархической системе всегда начинается с корня. Затем производится спуск с одного уровня дерева на другой, пока не будет достигнут искомый уровень. Перемещения по системе от одной записи к другой осуществляются с помощью ссылок.
Если структура запроса совпадает со структурой иерархической БД, то такая модель обладает самым высоким быстродействием и потому чаще всего применяется в супер ЭВМ.
В противном случае, быстродействие может резко снизиться, т.к. не удобно всегда начинать поиск нужных данных с корня, а другого способа перемещения по базе в иерархических структурах нет. Достоинства и недостатки иерархической модели представлены в таблице 2.
-
Как хранятся данные в сетевой модели данных?
В 1963 году С. Бахман построил первую промышленную базу данных IDS с сетевой моделью данных. В 1969 г. сформировалась группа, создавшая набор стандартов CODASYL (КОДАСИЛ) для сетевой модели данных.
Сетевая модель данных основана на представлении информации в виде орграфа, в котором в каждую вершину может входить произвольное число дуг. Вершинам графа сопоставлены типы записей, дугам – связи между ними. В сетевой модели (по крайней мере, теоретически) возможны связи всех информационных объектов со всеми.
На рис. 16, 17. представлены примеры структуры сетевой модели данных.
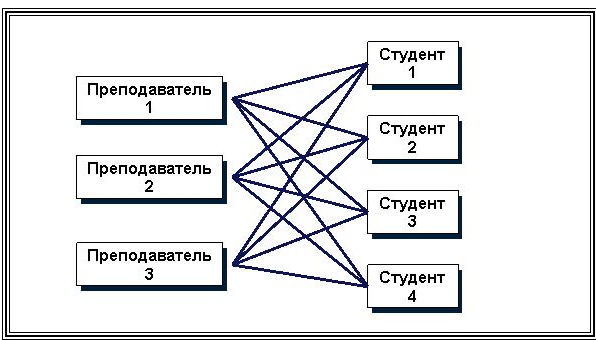
Рис. 16. Сетевая структура модели БД
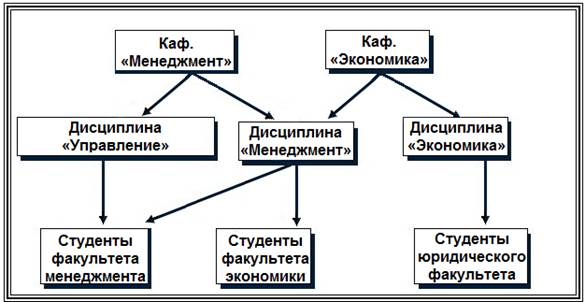
Рис. 17. Фрагмент сетевой модели данных
По сравнению с иерархическими сетевые модели обладают рядом существенных преимуществ:
возможность отображения практически всего многообразия взаимоотношений объектов предметной области;
непосредственный доступ к любой вершине сети (без указания других вершин);
-
Как хранятся данные в реляционной модели данных?
Реляционная модель данных.
Реляционная модель (от

