Добавлен: 12.03.2024
Просмотров: 14
Скачиваний: 0

СОДЕРЖАНИЕ
ГЛАВА 1. ОРГАНИЗАЦИОННЫЕ АСПЕКТЫ КОНТРОЛЯ ДОСТУПА К ДАННЫМ 8
1.2 Выбор средств контроля доступа к данным 13
ГЛАВА 2. ОРГАНИЗАЦИЯ КОНТРОЛЯ К БАЗАМ ДАННЫХ 18
2.1. Планирование работ по защите информации и порядок отчетности 18
2.2. Контроль состояния защиты информации 21
2.3. Взаимодействие с учреждениями по вопросам защиты информации 31
ВВЕДЕНИЕ
На сегодняшний день, в период быстро развивающихся информационных технологий, неуклонно возрастающего объема информации и усложнения коммуникаций все более актуальной становится задача защиты данных, в том числе защиты их передачи как между различными организациями, так и внутри одной компании, эффективной организации системы хранения ценной информации и возможности ограничения доступа к документам.
Организации защиты информации на современных предприятиях обычно уделяется меньше внимания, чем следовало бы. Хотя проще всего получить любую интересующую информацию из документов с помощью пробелов в делопроизводстве – это наиболее простой и малозатратный способ. Особенно это касается больших предприятий со сложной системой документооборота. Как известно, в программировании, чем сложнее код, тем вероятнее наличие в нем ошибок или чем сложнее система, тем более в ней выражена степень энтропии, отклонения от нормы. Поэтому на сегодняшний день актуальной становится задача выявления слабых мест в системе защиты документооборота и их укрепление.
Данное исследование актуально потому, что позволяет решить ряд практических задач на основе полученных в исследовании данных.
В данной сфере отмечено большое количество работ, раскрывающих вопросы безопасности как электронного, так и бумажного документооборота. Усилия многих ученых позволили создать практическую и теоретическую базу для дальнейшего углубления результатов в направлении организации защиты документов. Так, Е. Калугин основное внимание уделил проблемам защиты конфиденциальной информации, информационной безопасности личности, общества и государства, а также вопросам правового регулирования прав интеллектуальной собственности на информационные продукты[1].
Киви Берд – псевдоним специалиста по криптографии, шифрованию и дешифрованию, конспирологии, общей защиты информации. Настоящее имя автора неизвестно, что снижает уровень доверия. Долгое время публикуется в журнале «Компьютерра», также является автором книг об информационных технологиях. Основные темы статей – криптография, конспирология и теория заговора. Автор рассматривает технологическую сторону взлома и защиты электронных документов. Является обозревателем «Компьютерра», поэтому отслеживает новые события и атаки в мире информационных технологий. На основании сопоставления данных с другими работами можно установить степень достоверности его исследований[2].
Н.Н. Ковалева раскрыла понятия информации, информационного права и информационных правоотношений в современном обществе, охарактеризовала электронный документооборот, выявила особенности правового регулирования Интернета[3].
А. Крупин изучил виртуальные следы, оставляемые пользователем при работе в Интернете и программные средства их уничтожения. Стандартные log-файлы, скрипты и прочие средства владельцев сайтов способны сохранять информацию о пользователях: тип компьютера, операционной системы и браузера, страну пребывания, название и адрес провайдера, разрешение дисплея и т.д.[4].
А. Лукацкий рассмотрел ситуацию и в области информационной безопасности современных компаний, требования российского законодательства к средствам защиты, которое в неявной форме делит некоторые категории средств защиты на российские и зарубежные, закрывая последним дорогу на отечественный рынок (речь идет в первую очередь о средствах шифрования) и, возникшую в связи с этим, задачу единого управления этими разнородными средствами[5].
Особенности внедрения и применения новейших электронных технологий в современных библиотеках, основные проблемы, которые в основном заключаются в недостатке финансирования библиотек и обучении сотрудников, особенно старшего возраста представлены в работе Т.В. Майстрович[6].
В работе Г.Ю. Максимович приводятся правила оформления и составления документов разной направленности и назначения. По шагам описывается, как с помощью программ Word и Excel создать тот или иной документ. Немалое внимание уделяется тому, что и в какой форме должно быть написано в том или ином документе. Даются рекомендации по стилю служебного и делового письма. Рассматриваются правила международной переписки[7].
В исследовании О. Скиба даны основные направления защиты электронного документа в организации, основная идея – главным фактором в сфере безопасности является человеческий[8].
Особенности заключения договоров с использованием электронных документов были рассмотрены в работе Н. Соловяненко[9].
А. Стародымов, М. Пелепец пришли к выводу, что смартфоны являются самыми сомнительными устройствами в плане информационной безопасности. С позиций безопасности же были проанализированы флэш-карты и ноутбуки[10].
Н.Н. Федосеева в своей работе исследовала сущность и проблемы электронного документооборота, проанализировала преимущества электронных систем перед традиционными бумажными[11].
Н.Н. Федотов является автором цикла статей о защите данных на электронных носителях[12].
Джефри Розен (Jeffrey Rosen) и Грегори Конти (Gregory Conti) описали нашумевший взлом рейтинга, опубликованного газетой Time. В результате этого, рейтинг был изменен так, что первые буквы имен его лидеров образовывали определенную фразу[13].
Целью исследования является комплексное изучение средств и методов защиты информации от несанкционированного доступа на примере организации ТЭК.
Задачи, которые требуют решения для достижения данной цели: изучение организационных аспектов обеспечения защиты информации; исследование организационных и технических мероприятий по защите информации; планирование работ по защите информации и порядок отчетности; проведение контроля состояния защиты информации; организация взаимодействия с учреждениями по вопросам защиты информации.
Объектом исследования данной работы является ОАО «Газпромнефть-Урал», а предметом: система защиты информации ОАО «Газпромнефть-Урал».
Электронный документ тесно связан с понятием Интернет (англ. Internet, сокр. от Interconnected Networks – объединенные сети) – глобальная телекоммуникационная сеть информационных и вычислительных ресурсов. Поскольку ключевым словом в понятии Интернет является «глобальный», то территориальных рамок в объекте моей работы попросту не существует.
Хронологические рамки моей работы заключают период с начала 50-х гг. XX в. до настоящего времени. Это объясняется тем, что электроника начала развиваться высокими темпами в это время. Именно тогда были написаны коды первых программ ЭВМ – в 1951 г. Джон фон-Нейман предложил механизм самовоспроизводящихся программ – современных вирусов – которые продолжают совершенствоваться и по сей день.
Данная работа состоит из введения, двух глав, заключения, списка литературы, приложений.
ГЛАВА 1. ОРГАНИЗАЦИОННЫЕ АСПЕКТЫ КОНТРОЛЯ ДОСТУПА К ДАННЫМ
Особенностью анализа биологической информации является то, что в большинстве исследований требуется сделать запросы по нескольким параметрам к коллекции сгенерированных данных. Система, которая позволила бы обрабатывать такие запросы посредством адекватных интерфейсных средств ввода параметров и инфраструктуры доступа к большим коллекциям, также позволила бы высвободить ресурсы биоинформатиков и предоставить биологам качественные данные.
Сервисы GMQL (Рисунок 1) – коллекция биоинформационных сервисов с простым механизмом запуска и получения результата. Сервисы работают на уровне геномных регионов, предоставляя операции быстрого пересечения, выборки, соединения и т. д. Каждый сервис основан на геномном языке GMQL – высокопроизводительном окружении для запуска геномных запросов. GMQL – язык для формулирования геномных запросов, которые исполняются на фреймворке Hadoop. Сервисы оборачивают выбранные запросы геномного языка и предоставляют простой способ запуска запросов с пользовательскими параметрами и файлами. Интегрированные сервисы работают с пользовательскими данными и публичными репозиториями данных (ENCODE. Epigenomics Roadmap и т. д.).
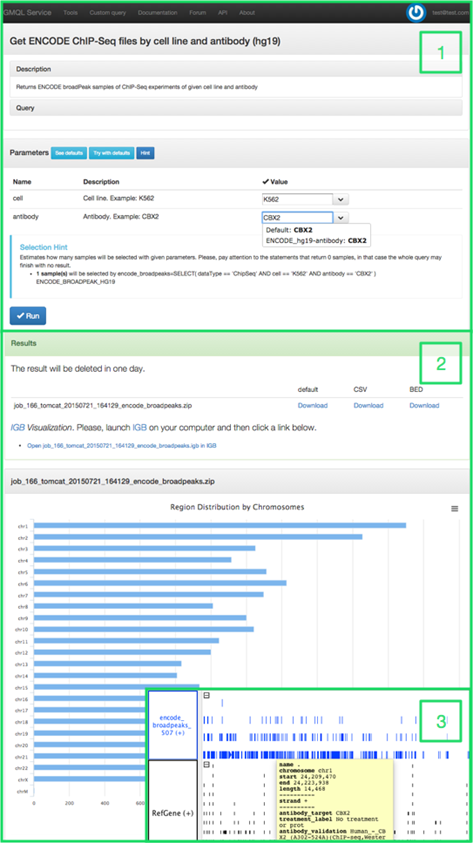
Рисунок 1. Изображение работы сервисов GMQL.
(1) Форма ввода данных с двумя параметрами, авто-заполнением и активированной подсказкой о количестве образцов, которые будут выбраны с текущими входными параметрами. (2) Часть результата со скачиваемыми данными во множественных форматах и распределение результирующих участков по хромосомам. (3) Часть результата, открытого в браузере IGB с подсказкой, которая показывает мета-данные результирующих участков
GMQL (GenoMetric Query Language) [1] поднимает уровень абстракции данных по сравнению с текущими языками, которые используются в биоинформатике, так как он позволяет формулировать запросы мощными, но простыми операциями. Таким образом, язык позволяет получать новые знания по ряду направлений. Важным аспектом языка является то, что он оперирует
геномными расстояниями, которые измеряются парами оснований (нуклеотидов) между регионами геномов. При предположении, что геномные участки выровнены на референсный геном, такие геномные операции вычисляются, как простые арифметические операции между координатами. В долгосрочной перспективе, главной сложность при работе с данными NGS является масштабируемость до тысяч или даже миллионов экспериментов. Поэтому на структуру геномного языка оказал влияние язык Pig Latin, высокоуровневый декларативный язык, который может быть исполнен на Hadoop.
Геномный язык GMQL составляет вычислительное ядро сервисов, которые предоставляют возможность создания веб-сервисов с пользовательскими операциями на лету.
Все доступные сервисы перечислены на странице инструментов. Пользователь может открыть любой сервис и запустить его. Сервисы, которые создаются администратором, появляются в верхней части списка. Пользовательские сервисы появляются в нижней части списка (в подразделе). Каждый сервис отображает статистику запусков. Сервисы отсортированы по популярности (числу запусков). Также, если сервис предполагает загрузку пользовательских данных, то он помечается соответствующим бейджем.
Поиск по запросу происходит в полях имен, описаний и текстах самих запросов сервисов. В поисковую выдачу попадают сервисы, которые содержат слова или части слов запроса в указанных выше полях.
Для запуска сервиса достаточно указать несколько параметров и нажать кнопку «Запуск». По завершению задачи, доступен скачиваемый результат. Для ознакомительного запуска, для большинства сервисов доступны параметры по умолчанию. Параметры по умолчанию можно подставить для их отображения перед запуском или же запустить сервис сразу.
Если запрос сервиса содержит операции выборки из геномных коллекций, то становится доступна функция оценки числа выбираемых экспериментов. Будет посчитано количество экспериментов с заданными параметрами. Это может быть полезно для оценки времени исполнения или правильности параметров.
Каждый запуск сервиса создает соответствующую вычислительную задачу. Список задач доступен на странице профиля пользователя. Таким образом пользователи могут запустить в асинхронном режиме столько задач, сколько необходимо и всегда иметь доступ к ним. Каждый пользователь имеет доступ только к собственным задачам и данным.
Текстовые параметры, которые вводит пользователь должны обязательно соответствовать соответствующим значениям в базе данных (таким образом, GATA1, gata1, gata – три разных значения). Для того, чтобы снизить процент ошибок, каждое поле ввода работает через автозаполнение.
По мере накопления данных в научном центре, биологам требуется выполнять разнотипные запросы, зачастую с использованием данных из открытых биоинформационных баз, содержащих сотни тысяч образцов. Например, для получения всех ChIP-Seq экспериментов для данного транскрипционного фактора. Геномный язык GMQL позволяет реализовывать различные запросы к хранилищам биоинформационных данных, таких как ENCODE. Разработанный метод генерации сервисов на основе геномного языка позволил биологам осуществлять запросы к большим хранилищам данных и получать результат в удобном для них формате, а также оценивать качество результата благодаря динамически генерируемым графикам и таблицам.

